


Large generative AI models unlock massive value for the world, but the picture isn’t only roses. Costs for training for these civilization-redefining models have been ballooning at an incredible pace. Modern AI has been built on scaling parameter counts, tokens, and general complexity an order of magnitude every single year. This report will discuss the brick wall for scaling dense transformer models, the techniques and strategies being developed to break through that wall, and which specific ones will be used in GPT 4…
大型生成性人工智能模型为世界解锁了巨大的价值,但情况并非全是美好。训练这些重新定义文明的模型的成本以惊人的速度飙升。现代人工智能的构建依赖于每年在参数数量、标记和整体复杂性上扩大一个数量级。该报告将讨论密集变换器模型扩展的瓶颈,正在开发的突破该瓶颈的技术和策略,以及在 GPT 4 中将使用哪些具体策略……
Amazon’s Cloud Crisis: How AWS Will Lose The Future Of Computing
亚马逊的云危机:AWS 将如何失去计算的未来
Nitro, Graviton, EFA, Inferentia, Trainium, Nvidia Cloud, Microsoft Azure, Google Cloud, Oracle Cloud, Handicapping Infrastructure, AI As A Service, Enterprise Automation, Meta, Coreweave, TCO
氮气、重力子、EFA、Inferentia、Trainium、英伟达云、微软 Azure、谷歌云、甲骨文云、障碍基础设施、人工智能即服务、企业自动化、Meta、Coreweave、TCO
Amazon owns more servers than any other company in the world despite its internal needs being much smaller than Google, Microsoft, Meta, and Tencent. Amazon Web Services (AWS) has long been synonymous with cloud computing. AWS has dominated the market by catering to startups and businesses alike, offering scalable, reliable, low-cost compute, and storage solutions. This engine has driven Amazon to become the preeminent computing company in the world, but that is changing.
亚马逊拥有的服务器数量超过世界上任何其他公司,尽管其内部需求远小于谷歌、微软、Meta 和腾讯。亚马逊网络服务(AWS)长期以来与云计算同义。AWS 通过为初创公司和企业提供可扩展、可靠、低成本的计算和存储解决方案,主导了市场。这个引擎推动亚马逊成为全球首屈一指的计算公司,但这一切正在发生变化。
Amazon is an amazing technical company, but they lack in some ways. Technological prowess, culture, and/or business decisions will hamper them from capturing the next wave of cloud computing like they have the last two. This report will cover these 3 phases of cloud computing and how Amazon’s continued dominance in the first two phases doesn’t necessarily give them a head start in the battle for the future of computing.
亚马逊是一家令人惊叹的技术公司,但在某些方面存在不足。技术实力、文化和/或商业决策将阻碍他们像过去两次那样捕捉到下一波云计算的浪潮。本报告将涵盖云计算的这三个阶段,以及亚马逊在前两个阶段的持续主导地位并不一定使他们在未来计算的竞争中占得先机。
We will present an overview of Amazon’s various in-house semiconductor designs, including Nitro, Graviton, SSDs, Inferentia, and Trainium. This overview will tackle the technology and total cost of ownership perspectives of Amazon’s in-house semiconductor ambitions. We will also cover what Amazon is intentionally doing that harms its position in AI and enterprise automation and will ultimately cause them to lose market share in computing. We will also explain how Microsoft Azure, Google Cloud, Nvidia Cloud, Oracle Cloud, IBM Cloud, Equinix Fabric, Coreweave, Cloudflare, and Lambda are each fighting Amazon’s dominance across multiple vectors and to various degrees.
我们将概述亚马逊的各种内部半导体设计,包括 Nitro、Graviton、SSD、Inferentia 和 Trainium。此概述将从技术和总拥有成本的角度探讨亚马逊的内部半导体雄心。我们还将讨论亚马逊故意采取的措施,这些措施损害了其在人工智能和企业自动化中的地位,并最终导致其在计算领域失去市场份额。我们还将解释微软 Azure、谷歌云、英伟达云、甲骨文云、IBM 云、Equinix Fabric、Coreweave、Cloudflare 和 Lambda 如何在多个方面以不同程度对抗亚马逊的主导地位。
Before we dive into our thesis, we need a bit of a history lesson first.
在我们深入探讨我们的论点之前,我们需要先上一堂历史课。
The Emergence of AWS AWS 的崛起
As Amazon ballooned in size with its retail business, it began to run into limitations of its monolithic 90s-era software practices. Metcalfe’s law sort of applied; as each additional service or developer was added, complexity grew at an n^2 rate. Even simple changes or enhancements impacted many downstream applications and use cases, requiring huge amounts of communication. As such, Amazon would have to freeze most code changes at a certain point in the year so the holiday season could focus on bug fixes and stability.
随着亚马逊的零售业务不断壮大,它开始遇到 90 年代单体软件实践的局限性。梅特卡夫定律在某种程度上适用;随着每增加一个服务或开发者,复杂性以 n^2 的速度增长。即使是简单的更改或增强也会影响许多下游应用程序和用例,导致需要大量的沟通。因此,亚马逊不得不在一年中的某个时点冻结大部分代码更改,以便在假日季节专注于修复错误和稳定性。
Amazon also had significant issues with duplication of work and resources just to stand up a simple relational database or compute service. This was exacerbated by the fact that the brightest engineers are often not the best communicators, which especially rings true when there isn’t a shared goal among different teams. Large software projects tend to reach a critical mass where the size of the organization and applications cause productivity and new features to take way too long to implement.
亚马逊在建立一个简单的关系数据库或计算服务时,也面临着重复工作和资源的重大问题。这一问题因最优秀的工程师往往不是最好的沟通者而加剧,尤其是在不同团队之间没有共同目标时更是如此。大型软件项目往往会达到一个临界点,组织和应用的规模导致生产力和新功能的实现时间过长。
Microsoft was among the first companies to have this problem, and they initially solved this by bringing in the role of program manager. A dedicated person who interfaces with a team of developers managing tasks such as organization, communications, and specification documents was unheard of at the time, but it was an effective tool. This alone doesn’t solve all of the problems.
微软是首批遇到这个问题的公司之一,他们最初通过引入项目经理的角色来解决这个问题。一个专门与开发团队对接、管理组织、沟通和规范文档等任务的人在当时是前所未闻的,但这是一个有效的工具。仅靠这一点并不能解决所有问题。
Amazon reached this same issue many years later, but they took a very different approach when they ran into these issues. Instead of facilitating communications between teams, Amazon attempted to reduce communications by leveraging "hardened interfaces." They moved from this monolithic software development paradigm to a service-oriented architecture. To be clear, other companies and academia were also implementing this, but no one jumped into the technique quite as strongly as Amazon.
亚马逊在许多年后也遇到了同样的问题,但他们在遇到这些问题时采取了非常不同的方法。亚马逊试图通过利用“硬化接口”来减少团队之间的沟通,而不是促进沟通。他们从这种单体软件开发范式转向了面向服务的架构。需要明确的是,其他公司和学术界也在实施这一点,但没有人像亚马逊那样强烈地采用这种技术。
Steve Yegge, an early employee at Amazon, recalled this pivotal moment at Amazon. Below is a portion of a memo he had ranting about Amazon once he joined Google, which was accidentally shared online.
史蒂夫·耶格,亚马逊的早期员工,回忆起在亚马逊的这个关键时刻。以下是他在加入谷歌后对亚马逊进行抨击的一份备忘录的部分内容,该备忘录意外地在线分享。
So one day Jeff Bezos issued a mandate. He's doing that all the time, of course, and people scramble like ants being pounded with a rubber mallet whenever it happens. But on one occasion -- back around 2002 I think, plus or minus a year -- he issued a mandate that was so out there, so huge and eye-bulgingly ponderous, that it made all of his other mandates look like unsolicited peer bonuses.
有一天,杰夫·贝索斯发布了一项命令。他当然一直在这样做,每当发生这种情况,人们就像被橡胶锤击打的蚂蚁一样忙乱。但在某个时候——我想是 2002 年左右,加减一年——他发布了一项如此超前、如此庞大且令人瞠目结舌的命令,以至于他所有其他的命令看起来都像是自愿的同伴奖金。His Big Mandate went something along these lines:
他的重大授权大致如下:
All teams will henceforth expose their data and functionality through service interfaces.
所有团队今后将通过服务接口公开他们的数据和功能。Teams must communicate with each other through these interfaces.
团队必须通过这些接口相互沟通。There will be no other form of interprocess communication allowed: no direct linking, no direct reads of another team's data store, no shared-memory model, no back-doors whatsoever. The only communication allowed is via service interface calls over the network.
不允许其他任何形式的进程间通信:不允许直接链接,不允许直接读取其他团队的数据存储,不允许共享内存模型,绝对不允许后门。唯一允许的通信方式是通过网络上的服务接口调用。It doesn't matter what technology they use. HTTP, Corba, Pubsub, custom protocols -- doesn't matter. Bezos doesn't care.
他们使用什么技术并不重要。HTTP、Corba、Pubsub、自定义协议——都无所谓。贝索斯并不在乎。All service interfaces, without exception, must be designed from the ground up to be externalizable. That is to say, the team must plan and design to be able to expose the interface to developers in the outside world. No exceptions.
所有服务接口,毫无例外,必须从头开始设计为可外部化。也就是说,团队必须计划和设计能够将接口暴露给外部开发者。没有例外。Anyone who doesn't do this will be fired.
任何不这样做的人将被解雇。Thank you; have a nice day!
谢谢;祝你有美好的一天!Ha, ha! You 150-odd ex-Amazon folks here will of course realize immediately that #7 was a little joke I threw in, because Bezos most definitely does not give a shit about your day.
哈,哈!你们这 150 多位前亚马逊的朋友们当然会立刻意识到第 7 条是我开的小玩笑,因为贝索斯绝对不关心你们的日子。
The most impactful part of this rant is number 5, which is they must be able to externalize these hardened interfaces. This is the beginning of making AWS….in 2002
这段 rant 中最有影响力的部分是第 5 点,即他们必须能够外部化这些硬化接口。这是创建 AWS 的开始……在 2002 年。
From there, off to the races! The logical progression was to make compute and storage hardware abstracted away in a similar manner. With many teams building services all the time and being told they will be fired if they talk to other teams, there was no conceivable way for IT centrally plan the need for servers and the growth of compute and storage requirements. As teams’ services surged in popularity internally, they needed to be able to provision hardware for the task.
从那里,开始比赛!逻辑上的进展是将计算和存储硬件以类似的方式抽象化。由于许多团队一直在构建服务,并被告知如果与其他团队交谈就会被解雇,因此 IT 部门无法集中规划服务器的需求和计算与存储需求的增长。随着团队的服务在内部人气飙升,他们需要能够为任务配置硬件。
It took another ~4 years to take these ideas and create the public offering that become AWS. For more history, check out this awesome podcast.
这花了大约 4 年的时间将这些想法转化为成为 AWS 的公开上市。有关更多历史,请查看这个精彩的播客。
We will fast forward through the start and talk more about what this era means to this day. In the early days, Amazon picked up all the startups and enabled them to actually build their own businesses. While most early adopters were these non-traditional new firms in software like Netflix and Twitch, innovative hardware companies were also all aboard the unstoppable freight train of cloud.
我们将快速跳过开头,更多地讨论这个时代对今天的意义。在早期,亚马逊收购了所有初创公司,使它们能够真正建立自己的业务。虽然大多数早期采用者是像 Netflix 和 Twitch 这样的非传统新软件公司,但创新的硬件公司也都加入了这个不可阻挡的云计算快车。
It’s so much easier. For a new company like us, you would just never build a traditional data center anymore.
这太简单了。对于像我们这样的新公司,你根本不会再建立传统的数据中心。Andy Bechtolsheim, 2010 – Founder of Arista and Sun Microsystems, also one of earliest investors in Google and VMware.
安迪·贝克托尔斯海姆,2010 年 – Arista 和 Sun Microsystems 的创始人,也是谷歌和 VMware 的最早投资者之一。
Amazon launched S3, a storage service, in 2006. Shortly after EC2, a compute service. In 2009, a relational database service was offered. Then there was Redshift and Dynamo DB. There are quite literally hundreds of important releases Amazon did with customers before any of their competitors got even close. The main point is that this era is characterized by AWS simply having better/more products, applications, and service offerings with better documentation than anyone else. Every time Google Cloud or Microsoft Azure built something, Amazon was many steps ahead and/or easier to use.
亚马逊在 2006 年推出了 S3 存储服务。随后推出了 EC2 计算服务。2009 年,提供了关系数据库服务。接着是 Redshift 和 Dynamo DB。可以说,亚马逊在与客户的合作中发布了数百个重要产品,而其竞争对手甚至还未接近。关键在于,这个时代的特点是 AWS 拥有更好的产品、应用和服务,且文档比其他任何人都要完善。每当谷歌云或微软 Azure 构建某样东西时,亚马逊总是走在前面,且使用起来更简单。
While this was true, especially in the beginning of the cloud, and it still continues to this day in some categories. The story and life cycle of the emergence of AWS are still playing out, although the gulf has diminished significantly. Amazon’s model of letting people pay with a credit card disrupted the legacy business of 6-figure or 7-figure service contracts and continues to do so. There is a long tail to this first wave of cloud computing.
虽然这在云计算的初期确实如此,并且在某些类别中至今仍然如此。AWS 的出现故事和生命周期仍在继续,尽管差距已显著缩小。亚马逊允许人们使用信用卡支付的模式颠覆了六位数或七位数服务合同的传统业务,并继续这样做。这是云计算第一波的长尾效应。
The Dominant Scale of AWS
AWS 的主导规模
As the middle part of the last decade rolled on, the majority of fortune 500 companies also started to migrate toward the cloud. As the cloud computing market matured, other companies recognized the opportunity and began investing heavily in their cloud offerings. Microsoft Azure, in particular, emerged as a strong contender by leveraging its enterprise-friendly approach. While Google Cloud Platform initially struggled to gain market share due to a lack of commercial focus, it has since improved its offerings and will reach profitability soon.
随着上个十年代中期的推进,大多数财富 500 强公司也开始向云端迁移。随着云计算市场的成熟,其他公司意识到这一机会,并开始在其云服务上进行大量投资。特别是微软 Azure,通过其企业友好的方法,成为了一个强有力的竞争者。虽然谷歌云平台最初因缺乏商业焦点而难以获得市场份额,但它已经改善了其产品,并将很快实现盈利。
The competition has only gotten tougher and more serious, but Amazon has an ace up its sleeve.
竞争变得越来越激烈和严肃,但亚马逊手中还有一张王牌。
Scale. 规模。
There are two ways to look at this scale advantage. First is from the lens that Amazon is quite literally just larger and has more footprint in the cloud space than anyone else. Cloud service providers needed a certain level of scale to leverage their size into buying hardware at lower prices and to amortize their software and hardware design costs.
有两种方式来看待这种规模优势。第一种是从亚马逊的角度来看,它在云计算领域的规模确实比其他任何公司都要大。云服务提供商需要一定的规模,以便利用其规模以更低的价格购买硬件,并摊销其软件和硬件设计成本。
A cloud service provider also needs to have a certain amount of capacity ready for others to use at a moment’s notice. This is especially important because cloud service providers cannot just centrally plan the utilization of their servers. Even long-term contracts often come with a high degree of uncertainty around when credits will be spent. At the same time, cloud providers must have high utilization rates to get an adequate return on invested capital (RoIC). The larger you are, the easier that is to achieve those high utilization rates with enough excess capacity for customers to ramp up and down.
云服务提供商还需要在瞬间准备好一定的容量供他人使用。这一点尤其重要,因为云服务提供商无法仅仅通过集中计划来利用他们的服务器。即使是长期合同,关于何时使用信用额度也常常存在很大的不确定性。同时,云服务提供商必须拥有高利用率,以获得足够的投资资本回报率(RoIC)。您越大,达到这些高利用率就越容易,同时为客户提供足够的冗余容量以便于他们的需求波动。
This lens is mostly limited in duration as the size of the cloud market means that multiple companies can achieve a minimum viable critical mass. Amazon hit that hockey stick moment, arguably in the early to middle parts of the 2010s. In 2012, Amazon had 23 total price reductions for AWS since inception, and by 2015 they had done 51 total. Public price reductions slowed markedly after the 2017 era, despite competition starting to heat up, although private double-digit % discounting is very common. At the very least, Microsoft and Google have also long since achieved that level of scale. In specialized applications, other clouds have reached meaningful scale as well, such as Cloudflare in CDN or Oracle in AI servers.
这个领域的持续时间主要受到限制,因为云市场的规模意味着多家公司可以实现最低可行的临界质量。亚马逊在 2010 年代早期到中期达到了那个曲棍球棒时刻。2012 年,亚马逊自成立以来对 AWS 进行了 23 次价格调整,到 2015 年总共进行了 51 次。尽管竞争开始加剧,但 2017 年后公开价格调整明显放缓,尽管私下的双位数百分比折扣非常普遍。至少,微软和谷歌也早已达到了那种规模。在专业应用中,其他云服务也达到了有意义的规模,例如 Cloudflare 在 CDN 领域或 Oracle 在 AI 服务器领域。
The much more important angle of scale is from the lens of purpose-built semiconductors, either in-house or with partners in the ecosystem. Amazon and Google are the foremost leaders in this transition, but every hyperscale company has already begun deploying at least some in-house chips. This ranges from networking to general-purpose compute to ASICs.
规模的更重要角度是从专用半导体的视角来看,无论是内部开发还是与生态系统中的合作伙伴合作。亚马逊和谷歌是这一转型的主要领导者,但每个超大规模公司已经开始部署至少一些内部芯片。这包括从网络到通用计算再到 ASIC。
Amazon drives tremendous savings from custom silicon which are hard for competitors to replicate, especially in the standard CPU compute and storage applications. Custom silicon drives 3 core benefits for cloud providers.
亚马逊通过定制硅芯片实现了巨大的节省,这对于竞争对手来说很难复制,特别是在标准 CPU 计算和存储应用中。定制硅芯片为云服务提供商带来了三个核心好处。
Engineering the silicon for your unique workloads for higher performance through architectural innovation.
为您的独特工作负载工程硅,以通过架构创新实现更高性能。Strategic control and lock-in over certain workloads.
战略控制和对某些工作负载的锁定。Cost savings from removing margin stacking of fabless design firms.
去除无晶圆设计公司边际叠加所带来的成本节省。
Amazon was, and still is, run in a very entrepreneurial way when it comes to new business units, segments, or infrastructure changes. Their teams, in many ways, remain nimble and small, but they still have the full backing of the behemoth organization behind them. Our favorite story pertaining to this is their inception into custom silicon.
亚马逊在新业务单元、细分市场或基础设施变更方面,一直以来都是以非常创业的方式运营。它们的团队在许多方面仍然保持灵活和小型,但他们仍然得到了庞大组织的全力支持。我们最喜欢的故事与他们进入定制硅有关。
Amazon Nitro 亚马逊氮气
All the way back in ~2012, an engineer at AWS, had an idea. Why not place a ‘dongle’, a dedicated piece of hardware, between every EC2 instance and the outside world so that all data would flow through it? This dongle would run security, networking, and virtualization tasks such as the hypervisor. The benefits of the ‘dongle’ would have the immediate benefit of improving performance, cost, and security for EC2 instances while also enabling bare metal instances. What started as a little idea was able to turn into the entire custom silicon effort of Amazon, which designs many different chips and saves them tens of billions of dollars a year.
早在 2012 年,AWS 的一位工程师有了一个想法。为什么不在每个 EC2 实例和外部世界之间放置一个“加密狗”,一个专用硬件,这样所有数据都可以通过它流动呢?这个加密狗将运行安全、网络和虚拟化任务,例如虚拟机监控程序。“加密狗”的好处将立即改善 EC2 实例的性能、成本和安全性,同时也支持裸金属实例。最初的一个小想法最终发展成了亚马逊整个定制硅片的努力,设计了许多不同的芯片,每年为其节省数百亿美元。
AWS set out a specification for a custom chip that would support this dongle idea. The requirements were simple, a dual-core Arm-based System-on-Chip (SoC), that could be PCIe attached. After approaching several firms, AWS worked with Cavium on the challenge of building a custom SoC at a cost that wouldn’t lead to a material increase in the cost of each EC2 server. The resulting Cavium part was delivered soon after. The whole system, with the custom SoC on a discrete PCIe card and associated software, was named ‘Nitro System’. It first appeared (although it wasn’t initially discussed publicly) in C3, R2, and I2, EC2 instances.
AWS 制定了一项定制芯片的规范,以支持这个加密狗的想法。要求很简单,一个基于双核 Arm 的系统级芯片(SoC),可以通过 PCIe 连接。在接触了几家公司后,AWS 与 Cavium 合作,解决在不显著增加每个 EC2 服务器成本的情况下构建定制 SoC 的挑战。最终的 Cavium 部件很快交付。整个系统,包括在独立 PCIe 卡上的定制 SoC 和相关软件,被命名为“Nitro System”。它首次出现在 C3、R2 和 I2 EC2 实例中(尽管最初并未公开讨论)。
By August 2022, AWS had over 20 million Nitro parts installed over four generations, with every new EC2 server installing at least one Nitro part.
截至 2022 年 8 月,AWS 已安装超过 2000 万个 Nitro 部件,涵盖四个版本,每个新的 EC2 服务器至少安装一个 Nitro 部件。
The primary cost benefit of this “dongle” is that it offloads Amazon’s management software, the hypervisor, which would otherwise run on an existing CPU. The most commonly deployed CPU across Amazon’s infrastructure was, and still is, an Intel 14nm 24-core CPU. Even to this day, other clouds, such as Microsoft Azure eat as many as 4 CPU cores on workloads that aren’t the customers’. If this held true across all of Amazon’s infrastructure, that would be as much as a ~15% reduction in the number of VMs for existing servers and, therefore, revenue.
这种“加密狗”的主要成本效益在于它卸载了亚马逊的管理软件,即虚拟机监控程序,否则这些软件将运行在现有的 CPU 上。亚马逊基础设施中最常用的 CPU 是英特尔 14nm 24 核 CPU。即使到今天,其他云服务,如微软 Azure,在非客户的工作负载上也会消耗多达 4 个 CPU 核心。如果这一点在亚马逊的所有基础设施中都成立,那么现有服务器的虚拟机数量将减少约 15%,因此也会影响收入。
Even with much more conservative estimates of 2 CPU cores saved per Nitro, with per-core cost estimated at 1/4th that of reserved list price, the savings of Nitro exceed $7 billion annually.
即使以每个 Nitro 节省 2 个 CPU 核心的更保守估计,按每个核心的成本估算为预留列表价格的 1/4,Nitro 的节省每年超过 70 亿美元。

The removal of these workloads from server CPU cores to the custom Nitro chip not only greatly improves cost, but also improves performance due to removing noisy neighbor problems associated with the hypervisor, such as shared caches, IO bandwidth, and power/heat budgets.
将这些工作负载从服务器 CPU 核心转移到定制的 Nitro 芯片,不仅大大降低了成本,还由于消除了与虚拟机监控程序相关的噪声邻居问题(如共享缓存、IO 带宽和功率/热预算)而提高了性能。
Furthermore, customers also reap the benefits of improved security by adding an air gap between the hypervisor management layer and server. This physical isolation removes a possible vector of side-channel escalation attacks from rogue tenants.
此外,客户通过在虚拟机管理层和服务器之间增加空气间隙,也获得了安全性提升的好处。这种物理隔离消除了来自恶意租户的侧信道升级攻击的可能途径。
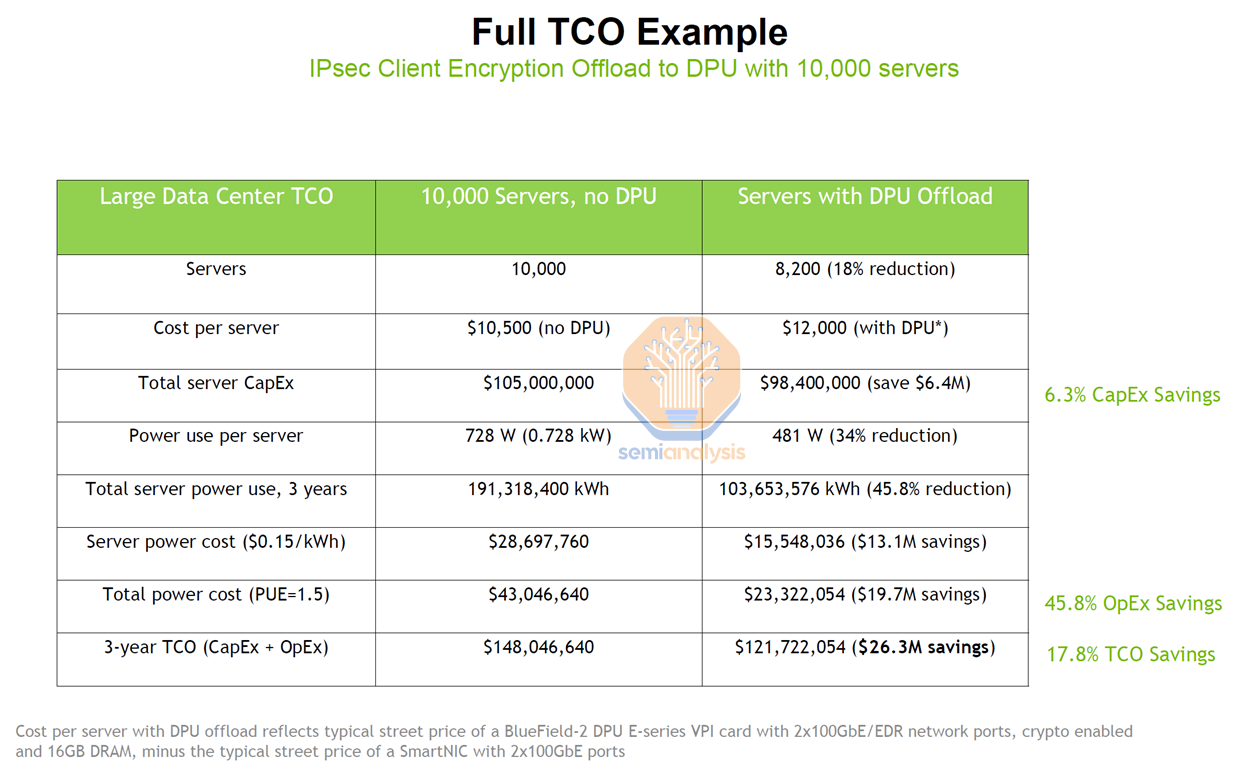
In addition to the hypervisor offload savings, as Nitro has evolved, it has also taken a central role in many networking workloads. For example, IPsec can be offloaded, which alone could be many millions in savings for each of Amazon’s major customers.
除了虚拟机监控程序卸载节省的成本,随着 Nitro 的发展,它在许多网络工作负载中也发挥了核心作用。例如,IPsec 可以被卸载,这本身就可能为亚马逊的每个主要客户节省数百万的成本。
The core of Amazon’s custom silicon efforts comes directly from their work with and later acquisition of Annapurna Labs in 2015. Annapurna was focused on server SOCs for networking and storage. It should be noted that Nitro is not just 1 chip, even though we are referring to it as such. There are multiple generations with multiple variants for different use cases.
亚马逊定制硅片工作的核心直接来自于他们与安纳普尔纳实验室的合作以及 2015 年的收购。安纳普尔纳专注于用于网络和存储的服务器 SOC。需要注意的是,Nitro 不仅仅是一个芯片,尽管我们称之为这样。它有多个世代和多个变种,适用于不同的使用场景。
Most of Amazon’s top services beyond EC2 are related to storage and databases. Nitro is the major enabler of a durable competitive advantage for Amazon in these workloads. Classical server architectures places at least some storage within every single server, which leads to significant stranding of unused resources.
亚马逊在 EC2 之外的大多数顶级服务与存储和数据库相关。Nitro 是亚马逊在这些工作负载中实现持久竞争优势的主要推动力。传统的服务器架构在每台服务器中至少放置一些存储,这导致了大量未使用资源的闲置。
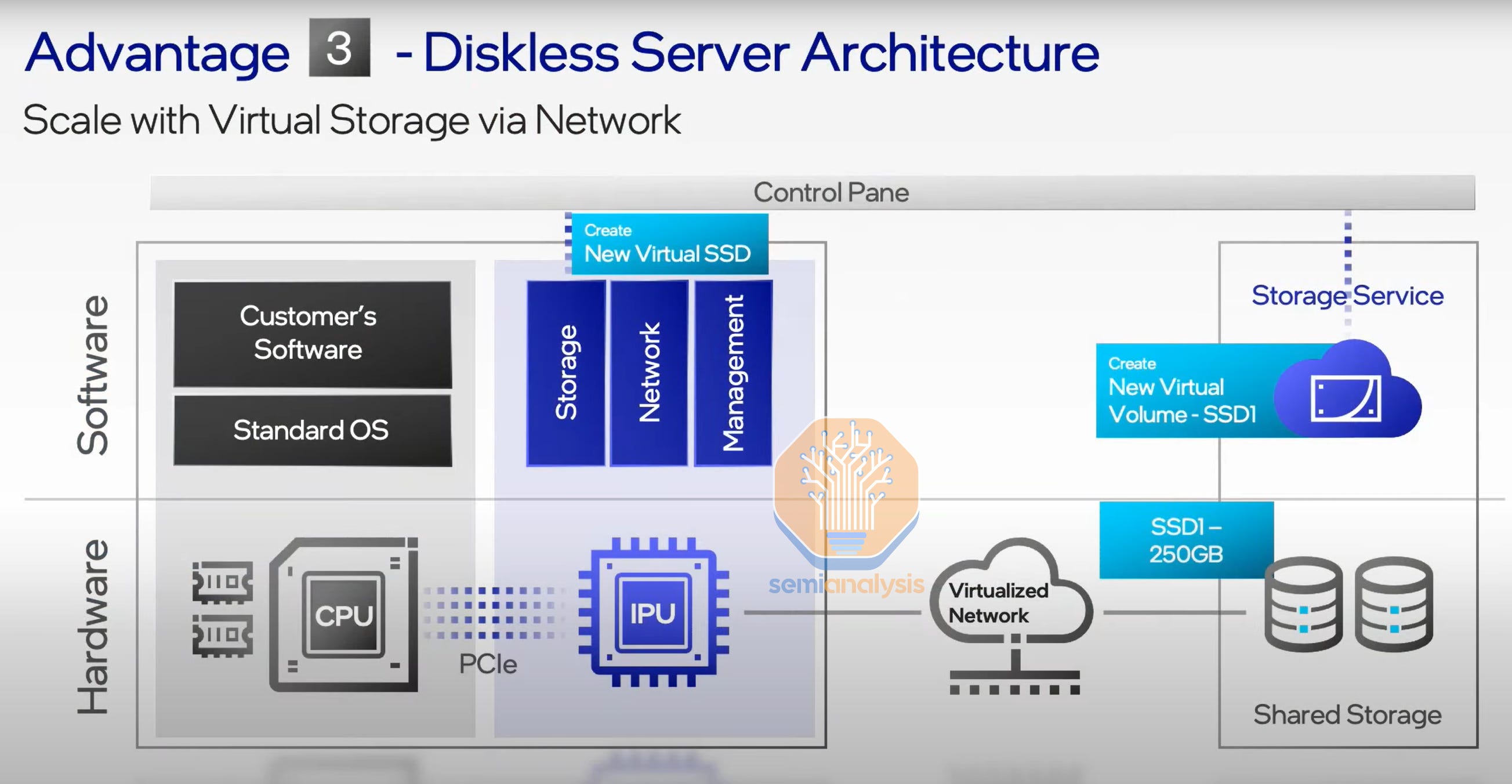
Amazon is able to remove that storage from every server and move it into centralized servers. The servers that customers rent can then boot off of the networked storage. Nitro enables this to be done even with high-performance NVMe SSDs. This shift in storage architecture helps Amazon save tremendously on storage costs as customers do not need to pay for any more storage than they want to use. Customers can dynamically grow and shrink their pools of high-performance storage seamlessly.
亚马逊能够将每个服务器上的存储移除并转移到集中式服务器中。客户租用的服务器可以从网络存储中启动。Nitro 使得即使使用高性能的 NVMe SSD 也能实现这一点。这种存储架构的转变帮助亚马逊在存储成本上节省了大量开支,因为客户无需支付超过他们想要使用的存储。客户可以动态地无缝扩展和缩减他们的高性能存储池。
This is extremely costly from a compute and networking perspective using general-purpose hardware, but Nitro can provide services such as virtual disk to the tenant's virtual machines at a lower cost due to being on an in-house workload-specific ASIC.
从计算和网络的角度来看,使用通用硬件的成本极高,但由于 Nitro 使用内部工作负载专用的 ASIC,可以以更低的成本为租户的虚拟机提供虚拟磁盘等服务。

Amazon’s focus on storage extends out to co-designing the ‘AWS Nitro SSD’ controller with Marvell. These SSDs focus on avoiding latency spikes and avoiding latency variability as well as maximizing the lifetime of the SSD through advanced, Amazon-managed wear leveling. Future variants will include some compute offload to improve query performance.
亚马逊对存储的关注扩展到与 Marvell 共同设计“AWS Nitro SSD”控制器。这些 SSD 专注于避免延迟峰值和延迟变化,同时通过先进的亚马逊管理的磨损均衡最大化 SSD 的使用寿命。未来的变种将包括一些计算卸载,以提高查询性能。
The other big 2 clouds are trying to go the same route, but they are years behind and require a partner who demands some margin. Google has chosen to go with custom silicon with the co-designed Intel Mount Evans IPUs, and Microsoft has a combination of AMD Pensando DPUs and eventually internally developed Fungible-based DPUs for storage use cases. Both of these competitors are stuck with 1st or 2nd generation merchant silicon for the next few years.
另外两个大型云服务商正试图走同样的路线,但他们落后多年,并需要一个要求一定利润的合作伙伴。谷歌选择与共同设计的英特尔 Mount Evans IPU 合作,采用定制硅片,而微软则结合了 AMD Pensando DPU,并最终开发基于 Fungible 的 DPU 用于存储用例。在接下来的几年里,这两家竞争对手都将被困在第一代或第二代商用硅片中。
Amazon is installing their 5th generation Nitro which was designed in-house. The advantages that Nitro brings from an infrastructure cost perspective cannot be understated. It enables much lower costs for Amazon, which can then be passed on to customers, or result in higher margins. With that said, Amazon’s Nitro also has some major drawbacks; more on this later.
亚马逊正在安装他们的第五代 Nitro,这是内部设计的。从基础设施成本的角度来看,Nitro 带来的优势不可小觑。它使亚马逊的成本大幅降低,这可以转嫁给客户,或者带来更高的利润率。话虽如此,亚马逊的 Nitro 也有一些主要缺点;稍后会详细介绍。
Arm At AWS 在 AWS 的 Arm
While Nitro does utilize Arm-based CPU cores, the key is the variety of fixed-function application-specific acceleration. AWS’s interest in Arm-based custom silicon isn’t limited to offloading their own workloads to dedicated hardware. During 2013, AWS’s thinking on using their own silicon developed much further. In a document titled “AWS Custom Hardware,” James Hamilton, an engineer, proposed two key points.
尽管 Nitro 确实使用基于 Arm 的 CPU 核心,但关键在于多种固定功能的应用特定加速。AWS 对基于 Arm 的定制硅的兴趣并不仅限于将他们自己的工作负载卸载到专用硬件上。在 2013 年,AWS 对使用自己硅的思考发展得更为深入。在一份名为“AWS 定制硬件”的文件中,工程师詹姆斯·汉密尔顿提出了两个关键点。
The volume of Arm CPUs being shipped on mobile and IoT platforms would enable the investment to create great Arm-based server CPUs in the same way Intel was able to leverage x86 in the client business to take over server CPU business in the 90s and 00s.
在移动和物联网平台上出货的 Arm CPU 数量将使投资能够像英特尔在 90 年代和 00 年代通过 x86 在客户端业务中占领服务器 CPU 市场一样,创造出优秀的基于 Arm 的服务器 CPU。Server functionality would ultimately come together into a single SoC. Thus to innovate in the cloud, AWS would need to innovate on silicon.
服务器功能最终将汇聚成一个单一的系统级芯片(SoC)。因此,要在云端进行创新,AWS 需要在硅片上进行创新。
The ultimate conclusion was that AWS needed to do a custom Arm server processor. As an aside, it would be amazing if this document was released publicly on its 10-year anniversary to show how visionary it was.
最终结论是,AWS 需要开发一个定制的 Arm 服务器处理器。顺便提一下,如果这份文件在其十周年纪念日公开发布,展示其前瞻性,那将是非常惊人的。
Let’s expand on this thesis James Hamilton had and look at two key ways in which using AWS-designed, Arm-based CPUs could offer advantages compared to their external counterparts.
让我们扩展一下詹姆斯·汉密尔顿的这个论点,看看使用 AWS 设计的基于 Arm 的 CPU 相比于外部同类产品的两个关键优势。
Firstly, they provide a way for AWS to reduce its costs and to offer better value to customers. How would it achieve this? Elaborating on James Hamilton’s points, it could tap into Arm’s scale in mobile by using the Arm-designed Neoverse cores. It can also utilize TSMC’s manufacturing scale, which far exceeds that of Intel, primarily due to the smartphone market. Using TSMC would, of course, also bring access to leading-edge process nodes, ahead of what Intel can make.
首先,他们为 AWS 提供了一种降低成本并为客户提供更好价值的方法。它将如何实现这一点?详细阐述詹姆斯·汉密尔顿的观点,它可以通过使用 Arm 设计的 Neoverse 核心来利用 Arm 在移动领域的规模。它还可以利用台积电的制造规模,这远远超过英特尔,主要是由于智能手机市场。当然,使用台积电还将获得领先的工艺节点,超越英特尔的制造能力。
Our estimates have Amazon’s in-house Graviton 2 and 3 CPUs as nearly 1 million units in 2022. This alone is a respectable enough volume to justify an in-house CPU program with core design outsourced to Arm, especially as Amazon continues to substitute AMD and Intel CPU purchases with their own. Amazon’s vertical integration play is a no-brainer, even if the only benefit was cheaper CPUs.
我们的估计显示,亚马逊自家研发的 Graviton 2 和 3 CPU 在 2022 年的出货量接近 100 万台。仅这一点就足以证明自家 CPU 项目的合理性,核心设计外包给 Arm,尤其是亚马逊继续用自家的 CPU 替代 AMD 和 Intel 的采购。即使唯一的好处是更便宜的 CPU,亚马逊的垂直整合策略也是显而易见的。
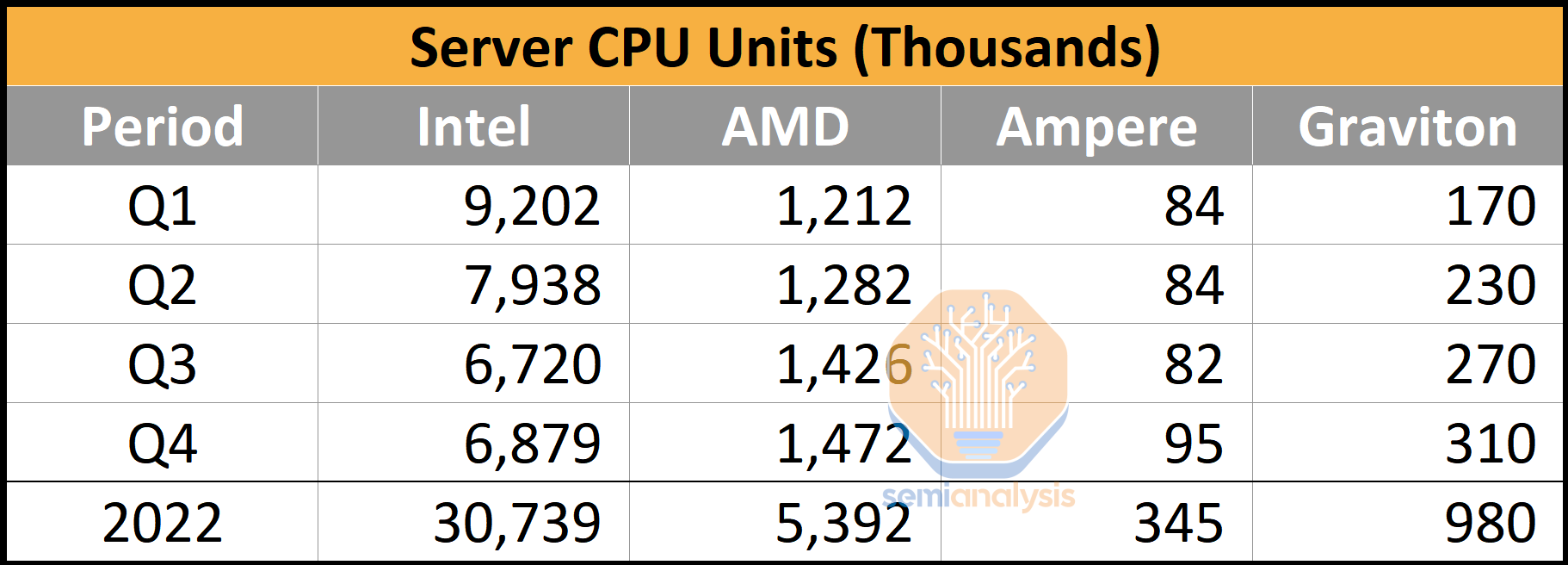
Comparing Amazon’s Graviton unit volume to the general market, and they are still currently dwarfed by Intel and AMD. While we believe Amazon has out-shipped Ampere Computing in the Arm server space with their in-house installations, there is still a big gap compared to the x86 vendors.
比较亚马逊的 Graviton 单元销量与整体市场,目前仍然被英特尔和 AMD 所压制。虽然我们相信亚马逊在 Arm 服务器领域的自有安装中已经超越了 Ampere Computing,但与 x86 供应商相比,仍然存在很大差距。
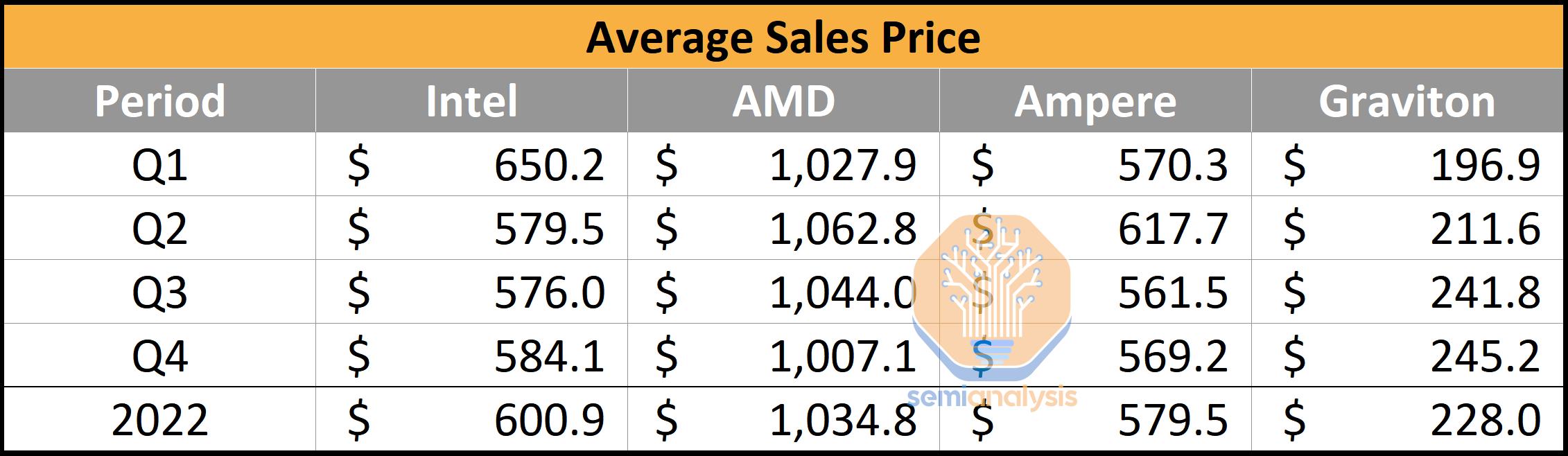
Now if we examine average sales prices, AMD commanded the highest sales price in the industry due to their high mix of 48-core and 64-core server CPUs with unmatched IO capabilities. Intel and Ampere Computing have similar ASPs, ranging around $600. We used our own estimates on manufacturing, packaging, and test costs for Graviton 2 and Graviton 3. Note IP licensing costs are not accounted for, but likely they aren’t that high, given Amazon has a sweetheart deal with Arm.
现在如果我们检查平均销售价格,AMD 由于其高比例的 48 核和 64 核服务器 CPU 以及无与伦比的 IO 能力,在行业中占据了最高的销售价格。英特尔和 Ampere Computing 的平均销售价格相似,约为 600 美元。我们使用了自己对 Graviton 2 和 Graviton 3 的制造、包装和测试成本的估算。请注意,IP 许可成本未被计算在内,但考虑到亚马逊与 Arm 有优惠协议,可能并不高。
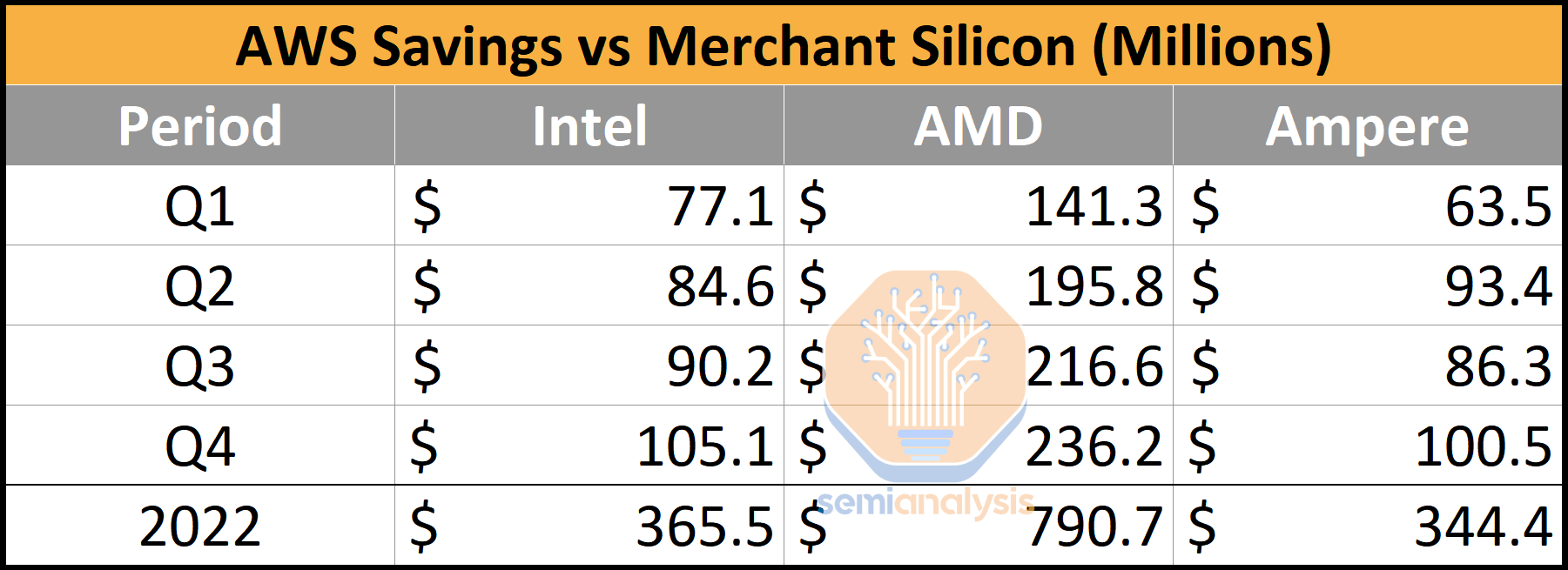
If CPUs were assumed to be 1-to-1 replacements, then the switch to in-house silicon by Amazon saves them hundreds of millions of dollars. Of course, not all CPUs are equal. Even AMD’s last generation Milan is still faster than Intel’s, Amazon’s, or Ampere’s current generation in many ways. Even ignoring the outlier that is AMD, the potential savings from Graviton in 2022 are >$300M. Now layer on the fact that Amazon’s CPUs are higher performance than Intel’s while also using less power, and the savings start to grow rapidly. We believe the total cost of development of Graviton is likely in the ~$100M annual range, which gives them >$200M of savings.
如果假设 CPU 是 1 对 1 的替代品,那么亚马逊转向自家硅片为他们节省了数亿美元。当然,并非所有 CPU 都是平等的。即使是 AMD 的上一代 Milan 在许多方面仍然比英特尔、亚马逊或 Ampere 的当前一代更快。即使忽略 AMD 这个特例,2022 年 Graviton 的潜在节省也超过 3 亿美元。再加上亚马逊的 CPU 性能高于英特尔,同时功耗更低,节省开始迅速增长。我们认为 Graviton 的总开发成本可能在每年约 1 亿美元的范围内,这使他们的节省超过 2 亿美元。
The merchant silicon providers are irreversibly losing hundreds of millions of dollars and soon billions of dollars in TAM. Intel is the biggest loser here, moving from a chip company selling millions of CPUs into the cloud to a manufacturing company that is doing the significantly lower margin packaging of these Graviton3 CPUs.
商用硅供应商正不可逆转地损失数亿美元,甚至很快将损失数十亿美元的市场总量(TAM)。英特尔是这里最大的输家,从一家销售数百万个 CPU 到云端的芯片公司,转变为一家进行这些 Graviton3 CPU 的低利润包装的制造公司。
Just as important, in-house CPUs enables Amazon to design CPUs to maximize density and minimize server and system level energy, which helps tremendously on a total cost of ownership basis. One easy-to-understand engineering decision is that Amazon architected Graviton 3 to be only 64 cores, despite ample room to scale chip size and power up.
同样重要的是,内部 CPU 使亚马逊能够设计 CPU,以最大化密度并最小化服务器和系统级能耗,这在总拥有成本方面有很大帮助。一个易于理解的工程决策是,尽管有足够的空间来扩大芯片尺寸和提升功率,亚马逊还是将 Graviton 3 架构设计为仅 64 个核心。
Contrast this with AMD’s 96-core Epyc, which is much faster, but also has higher power. Amazon’s conscious engineering decision enables them to put 3 CPUs per 1U server. Meanwhile, AMD Genoa servers max out at 2 CPUs per 1U, and due to power constraints, it often ends up being a 2U-sized server. Some of the more nuanced engineering choices which differ from AMD and Intel revolve around Graviton being cloud-native, which we explored more in detail here.
将此与 AMD 的 96 核 Epyc 进行对比,后者速度更快,但功耗也更高。亚马逊的有意识工程决策使他们能够在 1U 服务器中放置 3 个 CPU。与此同时,AMD Genoa 服务器在 1U 中最多只能放置 2 个 CPU,由于功耗限制,通常最终变成 2U 大小的服务器。与 AMD 和英特尔不同的一些更细微的工程选择围绕 Graviton 的云原生特性,我们在这里进行了更详细的探讨。
We shouldn’t forget, of course, that competition also increases the pressure on Intel and AMD to reduce prices on CPUs. AWS also saves on their x86 CPUs too! AMD and Intel must outengineer Amazon to such a large degree that they can justify their huge margins on merchant silicon. We have no doubts AMD is better at engineering CPU cores and SoCs, and Intel could get there too, but can they be >2x better to justify their ~60% datacenter margins? Tough proposition.
我们当然不应该忘记,竞争也增加了英特尔和 AMD 降低 CPU 价格的压力。AWS 在他们的 x86 CPU 上也节省了成本!AMD 和英特尔必须在工程上超越亚马逊,以至于他们能够证明自己在商用硅上的巨大利润率。我们毫不怀疑 AMD 在 CPU 核心和 SoC 的工程方面更出色,英特尔也有可能达到这一点,但他们能否做到超过 2 倍的优势,以证明他们约 60%的数据中心利润率?这是一个艰难的命题。
Microsoft and Google both have ongoing internal server CPU efforts on the horizon, but they have yet to install anything in volume. Even once they do, it’s hard to imagine they will be able to beat Amazon’s 3rd or 4th iteration.
微软和谷歌都在进行内部服务器 CPU 的努力,但他们尚未大规模安装任何设备。即使他们这样做了,也很难想象他们能够超越亚马逊的第三代或第四代产品。
The tremendous scale of Amazon, especially with regard to general-purpose compute and storage-related verticals, cannot be understated. This will continue to drive a durable advantage in the cloud for many years to come.
亚马逊的巨大规模,尤其是在通用计算和存储相关领域,无法被低估。这将继续在云计算中推动持久的优势,持续多年。
Check out The Chip Letter for a ton of great history lessons on semiconductors, Babbage helped us write a portion of the history here, and he will be releasing his own piece that goes over more of the history of Amazon’s in-house semiconductors soon.
查看《芯片信件》,了解大量关于半导体的历史课程,巴贝奇帮助我们撰写了这里的一部分历史,他将很快发布自己的一篇文章,详细介绍亚马逊内部半导体的更多历史。
The Next Era of Computing
下一时代的计算机技术
So far, we have only sung praises about Amazon, but the background and realities of Amazon’s advantages had to be presented before we can even begin to talk about the future of cloud service providers.
到目前为止,我们只对亚马逊赞不绝口,但在我们开始谈论云服务提供商的未来之前,必须先呈现亚马逊优势的背景和现实。
Amazon, semiconductors, and tech, in general, are stories of stacking S curves. Amazon, as a company, is geared to constantly grow. They’ve never really exited the investment cycle. In many ways, they are culturally equipped to always find the next big thing, not necessarily extracting maximum value once their fangs are sunk in.
亚马逊、半导体和科技行业总体上都是堆叠 S 曲线的故事。作为一家公司,亚马逊始终致力于不断增长。他们从未真正退出投资周期。在许多方面,他们在文化上具备始终寻找下一个大事物的能力,而不一定是在他们的“牙齿”深入后提取最大价值。
Amazon’s culture, conscious business decisions around their cloud service provider model, and technology choices with regard to custom compute and networking silicon could leave them hanging dry in the next era of computing. While the prior two eras of cloud will continue to play out and Amazon will extract huge value out of being the leading unregulated utility in an oligopoly-like market, the next era is not necessarily theirs for the taking. There is significant competitive pressure from existing competitors and new ones who are racing ahead.
亚马逊的文化、围绕其云服务提供商模型的有意识商业决策,以及在定制计算和网络硅片方面的技术选择,可能会使他们在下一个计算时代中陷入困境。虽然前两个云时代将继续发展,亚马逊将在一个类似寡头市场的无监管公用事业中提取巨大的价值,但下一个时代并不一定是他们的。来自现有竞争对手和新兴竞争对手的竞争压力非常显著,他们正在快速前进。
The second half of this report is for subscribers and will go in-depth about major technical deficiencies in Amazon’s silicon strategy and how they are missing the next era of explosive growth in both AI and services. We will be comparing the silicon, server, and cloud strategies of multiple competitors, including Microsoft Azure, Nvidia Cloud, Google Cloud, Oracle Cloud, IBM Cloud, Equinix Fabric, Coreweave, and Lambda. Furthermore, we will have a discussion about the services business and how competitors are more equipped to lead there. We will share multiple viewpoints and, ultimately, how we see the market shaking out. Furthermore, we will share some short-term commentary on cloud, AI, and services as well.
本报告的下半部分是为订阅者准备的,将深入探讨亚马逊硅战略中的主要技术缺陷,以及他们如何错过 AI 和服务领域的下一个爆炸性增长时代。我们将比较多个竞争对手的硅、服务器和云战略,包括微软 Azure、英伟达云、谷歌云、甲骨文云、IBM 云、Equinix Fabric、Coreweave 和 Lambda。此外,我们还将讨论服务业务,以及竞争对手在这一领域的领先能力。我们将分享多个观点,并最终阐述我们对市场发展的看法。此外,我们还将分享一些关于云、AI 和服务的短期评论。
The cloud infrastructure business, while offering significant growth opportunities, is not always the most lucrative venture on its own. Right now, there are at least 4 infrastructure providers who have hit sufficient scale (Amazon, Microsoft, Alibaba, Google), but over time others will also reach a sufficient scale. As the cloud industry matures, the true value of cloud infrastructure lies in the ability to leverage that position to sell higher-margin and less capital-intensive products. This rings true even for Amazon today. Their service-oriented offerings related to databases and serverless compute are much higher margins than their general-purpose compute instances.
云基础设施业务虽然提供了显著的增长机会,但单独来看并不总是最有利可图的投资。目前,至少有 4 家基础设施提供商(亚马逊、微软、阿里巴巴、谷歌)已达到足够的规模,但随着时间的推移,其他公司也将达到足够的规模。随着云行业的成熟,云基础设施的真正价值在于利用这一地位销售更高利润和资本密集度较低的产品。即使是今天的亚马逊,这一点也同样适用。他们与数据库和无服务器计算相关的服务导向产品的利润率远高于他们的通用计算实例。
There are generally 3 major buckets of cloud computing services. The capital intensity and typical margins differ across each bucket. Furthermore, lock-in barriers rise with each successive bucket.
云计算服务通常分为三个主要类别。每个类别的资本密集度和典型利润率有所不同。此外,随着每个类别的增加,锁定壁垒也会提高。
Infrastructure as a Service (IaaS): IaaS provides virtualized computing resources over the internet. In this model, the cloud provider manages the underlying physical infrastructure (servers, storage, and networking), while the user is responsible for managing the operating systems, applications, and data. This is the most capital intensive and lowest margin business.
基础设施即服务(IaaS):IaaS 通过互联网提供虚拟化计算资源。在这种模式下,云服务提供商管理底层物理基础设施(服务器、存储和网络),而用户负责管理操作系统、应用程序和数据。这是资本密集型且利润率最低的业务。Platform as a Service (PaaS): PaaS offers a higher level of abstraction compared to IaaS. In this model, the cloud provider manages the underlying infrastructure as well as the operating systems and runtime environments. Users can focus on developing, deploying, and managing their applications without worrying about infrastructure management. PaaS is particularly useful for developers, as it often includes tools, libraries, and frameworks that simplify application development and deployment. This is less capital-intensive and higher margin with more lock-in than infrastructure.
平台即服务(PaaS):与基础设施即服务(IaaS)相比,PaaS 提供了更高层次的抽象。在这种模型中,云服务提供商管理底层基础设施以及操作系统和运行环境。用户可以专注于开发、部署和管理他们的应用程序,而无需担心基础设施管理。PaaS 对开发人员特别有用,因为它通常包括简化应用程序开发和部署的工具、库和框架。这种模式的资本投入较少,利润率更高,且比基础设施有更多的锁定效应。Software as a Service (SaaS): SaaS is the most abstracted cloud service model, where the cloud provider manages the entire application stack, including infrastructure, operating systems, middleware, and the application itself. SaaS is typically billed on a subscription basis and can be scaled up or down as needed. Examples of SaaS providers include Salesforce, Microsoft Office 365, and Google Workspace. This is the least capital-intensive and highest-margin business a cloud service provider can offer. Furthermore, it has the highest amount of customer lock-in.
软件即服务(SaaS):SaaS 是最抽象的云服务模型,云服务提供商管理整个应用程序堆栈,包括基础设施、操作系统、中间件和应用程序本身。SaaS 通常按订阅计费,并可以根据需要进行扩展或缩减。SaaS 提供商的例子包括 Salesforce、Microsoft Office 365 和 Google Workspace。这是云服务提供商可以提供的资本密集度最低、利润率最高的业务。此外,它具有最高的客户锁定程度。
Information technology will only grow as a percentage of GDP, but much of this growth will be captured by platform and software service providers who can leverage both on-prem, collocated, and relatively lower-margin public infrastructure providers.
信息技术在 GDP 中的比例只会增长,但这部分增长将主要被能够利用本地、共置和相对低利润的公共基础设施提供商的平台和软件服务提供商所占据。
Enterprise automation and AI will be the biggest drivers of future economic growth. These are the most important markets to service to drive the highest margin and most lock-in. The firms that can enable this are the winners. The biggest question is who is best equipped for these transitions. Will Amazon be able to scale beyond infrastructure into these services?
企业自动化和人工智能将是未来经济增长的最大驱动力。这些是服务于最高利润和最强锁定的最重要市场。能够实现这一点的公司将是赢家。最大的问题是,谁最有能力进行这些转型。亚马逊能否在基础设施之外扩展到这些服务?
Furthermore, the scarier question is if Amazon is even equipped to provide competitive infrastructure for AI. We believe that Amazon will not be a good provider of AI infrastructure, let alone platforms and software.
此外,更令人担忧的问题是亚马逊是否具备提供竞争性人工智能基础设施的能力。我们认为亚马逊不会是一个好的人工智能基础设施提供商,更不用说平台和软件了。
Amazon – Scale To Service?
亚马逊 – 扩大服务规模?
The biggest threat to Amazon and cloud infrastructure providers, in general, is that scale advantages only take them so far. Is Amazon’s long-term trajectory to become a reasonable RoIC balance sheet that interfaces between customers, electronics manufacturers/fabs like TSMC and Samsung, and high-margin service providers? If Amazon remains only an infrastructure provider rather than a platform and software provider, then the competition can also muscle into the infrastructure side. We see this happening already with other clouds such as Microsoft, Oracle, and IBM.
亚马逊及云基础设施提供商面临的最大威胁是规模优势只能带他们走得很远。亚马逊的长期发展轨迹是否是成为一个合理的投资回报率资产负债表,连接客户、电子制造商/代工厂如台积电和三星,以及高利润服务提供商?如果亚马逊仅仅作为基础设施提供商,而不是平台和软件提供商,那么竞争对手也可以进入基础设施领域。我们已经看到其他云服务如微软、甲骨文和 IBM 正在发生这种情况。
Amazon is ridiculously behind on enterprise automation services. Due to its customer base being very concentrated in this area, it is hard for Amazon to move up into developing its own alternatives. In most cases, Amazon is not even trying to move up. Deploying traditional enterprise software is a must, in order to get access to data. This data will be critical to further business automation and add new capabilities with AI.
亚马逊在企业自动化服务方面落后得令人难以置信。由于其客户群在这一领域非常集中,亚马逊很难向上发展自己的替代方案。在大多数情况下,亚马逊甚至没有尝试向上发展。部署传统企业软件是必须的,以便获取数据。这些数据对于进一步的业务自动化至关重要,并将通过人工智能增加新的能力。
Amazon is even further behind with AI than they are with enterprise automation. Their services suite has nearly 0 adoptions outside of simple, cheap image nets. Even their most recent, best research, is years behind that of Google and OpenAI. Furthermore, they resort to disingenuous comparisons to OpenAI’s work in academic papers, which doesn’t look good. Amazon has never led in any areas of AI, including LLM, DLRM, or Image/Video models.
亚马逊在人工智能方面的进展甚至比企业自动化还要落后。他们的服务套件几乎没有在简单、廉价的图像网络之外的应用。即使是他们最新的、最好的研究,也比谷歌和 OpenAI 的研究落后多年。此外,他们在学术论文中对 OpenAI 工作的比较显得不够真诚,这并不好。亚马逊在人工智能的任何领域,包括LLM、DLRM 或图像/视频模型,从未处于领先地位。
How will they be able to deploy pre-trained models or fine-tune these models if they can’t even build them? How can they set up an optimized infrastructure offering for AI if they don’t know what the forefront of hardware innovation looks like? In fact, Amazon’s custom infrastructure is set up very inefficiently for AI (more on this in a bit).
他们如何能够部署预训练模型或微调这些模型,如果他们连模型都无法构建?如果他们不知道硬件创新的前沿是什么样子,他们如何能够建立一个优化的 AI 基础设施?事实上,亚马逊的定制基础设施在 AI 方面设置得非常低效(稍后会详细说明)。
Amazon should, at the very least, replicate Meta’s strategy with LLM. Meta, a leader in areas of machine learning but not LLM, is first replicating the best of Google and OpenAI work in 2021/2022 before moving forward to developing newer technologies. Meta is also way more in touch with AI software due to their role in creating and leading PyTorch. Furthermore, Meta has direct access to tons of user data and feedback that Amazon can never hope to access. It’s a vicious cycle of Amazon never having access to enterprise and consumer data in the same way Google, Microsoft/OpenAI, and Meta do. This cycle is leading them to not focus on LLMs, and not being able to optimize infrastructure for them.
亚马逊至少应该复制 Meta 的战略与LLM。Meta 在机器学习领域处于领先地位,但在LLM方面并不突出,首先在 2021/2022 年复制谷歌和 OpenAI 的最佳成果,然后再向前发展新技术。由于 Meta 在创建和领导 PyTorch 方面的角色,他们与 AI 软件的联系更加紧密。此外,Meta 直接访问大量用户数据和反馈,而亚马逊永远无法希望获得这些数据。这形成了一个恶性循环,亚马逊无法像谷歌、微软/OpenAI 和 Meta 那样访问企业和消费者数据。这个循环导致他们无法专注于LLMs,也无法为他们优化基础设施。
As more enterprises adopt multi-cloud approaches, they seek to leverage the best-of-breed services from various cloud providers, reducing reliance on a single vendor and mitigating the risks associated with vendor lock-in. Amazon does not have lock-in from the angle of compute. General purpose compute is ultimately a commodity, and Amazon’s Graviton is mostly a cost optimization that is being replicated by Microsoft and Google.
随着越来越多的企业采用多云策略,他们寻求利用来自不同云服务提供商的最佳服务,减少对单一供应商的依赖,并降低与供应商锁定相关的风险。从计算的角度来看,亚马逊并没有锁定。通用计算最终是一种商品,而亚马逊的 Graviton 主要是一种成本优化,微软和谷歌也在复制这一点。
The other side of Amazon’s cloud is arguably much more powerful from the angle of lock-in. AWS has developed a strong ecosystem of storage and database services. Services such as Amazon S3, RDS, Redshift, DynamoDB, etc have become critical components of many organizations' data management strategies. The extensive integration and optimization of these services within the AWS ecosystem make it challenging for customers to migrate their data and applications to alternative platforms.
亚马逊云的另一面从锁定的角度来看无疑更具实力。AWS 已经建立了强大的存储和数据库服务生态系统。像 Amazon S3、RDS、Redshift、DynamoDB 等服务已成为许多组织数据管理策略的关键组成部分。这些服务在 AWS 生态系统内的广泛集成和优化使得客户将其数据和应用程序迁移到其他平台变得具有挑战性。
The stickiness of these platforms cannot be understated. Look at Oracle as the obvious answer as to why. Amazon’s storage business will be just as sticky, if not more-so. Even Snowflake, which pitches itself as the harbinger of multi-cloud database and storage, primarily runs its services for clients on AWS.
这些平台的粘性不可小觑。看看 Oracle,显然就是原因所在。亚马逊的存储业务同样会非常粘性,甚至更强。即使是 Snowflake,虽然自称是多云数据库和存储的先驱,但其服务主要还是在 AWS 上运行。
Migrating data out of Amazon, even if the software is transferable, is incredibly costly on a time basis due to limited bandwidth and egress costs. If an enterprise has a staggering 1 exabyte of data, that costs ~$60 million to send out (egress costs). Note that it would cost $1 million to $23 million to store, depending on whether standard storage or archival storage is chosen. No discounts are applied in those figures above.
将数据迁移出亚马逊,即使软件可以转移,由于带宽有限和出口成本,时间成本非常高。如果一个企业有惊人的 1 艾字节的数据,发送出去的成本约为 6000 万美元(出口成本)。请注意,存储成本在 100 万美元到 2300 万美元之间,具体取决于选择标准存储还是归档存储。上述数字中没有应用任何折扣。
This strength of data lock-in is very much overstated with AI. A complete model is essentially a file with a bunch of weights, which are less than 1TB of data, even for Google and OpenAI’s largest publicized model. These models can run the compute-heavy element of inference easily in any other cloud. A common argument we have heard is that companies locked into the Amazon storage and database ecosystem will train their AIs where their data is located due to data egress cost.
这种数据锁定的强度在人工智能领域被大大夸大了。一个完整的模型本质上是一个包含大量权重的文件,即使是谷歌和 OpenAI 最大公开模型的数据也不到 1TB。这些模型可以轻松地在任何其他云中运行计算密集型的推理元素。我们听到的一个常见论点是,被锁定在亚马逊存储和数据库生态系统中的公司将会在其数据所在的位置训练他们的人工智能,因为数据出口成本。
This is an incorrect assumption. While data pre-processing flows would occur in Amazon’s datacenters, in general, they are quite cheap/low on compute. A few standard compute nodes could easily scrape PDFs and word documents into text files. These text files are relatively small and could then be sent to where the model will actually be trained.
这是一个错误的假设。虽然数据预处理流程会在亚马逊的数据中心进行,但一般来说,它们的计算成本相对较低。几个标准计算节点可以轻松地将 PDF 和 Word 文档抓取为文本文件。这些文本文件相对较小,然后可以发送到实际进行模型训练的地方。
A few months ago, we discussed the practical limits of scaling dense transformer models from a parameter count, token, and cost standpoint. This is relevant through the lens of both training and inference workloads.
几个月前,我们讨论了从参数数量、标记和成本的角度扩展密集变换器模型的实际限制。这在训练和推理工作负载的视角下都是相关的。
The largest dataset size of Google’s largest (publicly disclosed) model is Chinchilla. It was trained on 1.4 trillion tokens. Even if that number were 10x’ed, the amount of data used to train it would be irrelevant in terms of egress costs. These 10x models would likely cost hundreds of millions, if not billions of dollars, to train on current hardware. More likely, models are fine-tuned from pre-trained models offered by the leaders in LLM.
谷歌最大(公开披露)的模型的数据集大小是 Chinchilla。它是在 1.4 万亿个标记上训练的。即使这个数字增加 10 倍,用于训练的数据量在出口成本方面也将无关紧要。这些 10 倍模型在当前硬件上训练的成本可能高达数亿,甚至数十亿美元。更有可能的是,模型是从LLM的领导者提供的预训练模型中进行微调的。
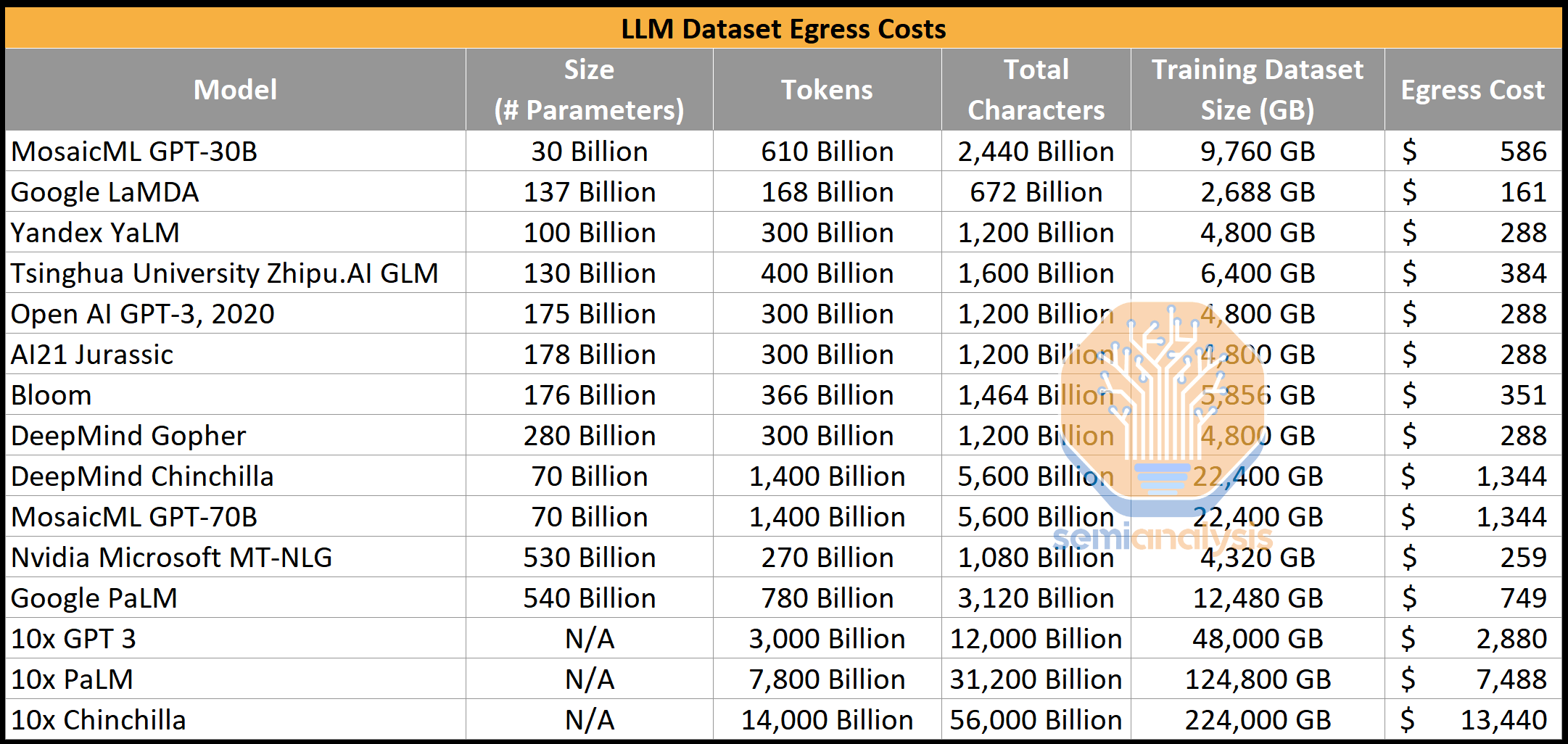
Migrating training and inference out of Amazon is quite easy, but more importantly, it is necessary. Amazon will not only miss out on the AI services boom due to their lack of capabilities in AI.
将训练和推理迁移出亚马逊非常简单,但更重要的是,这是必要的。亚马逊不仅会因为在人工智能方面缺乏能力而错过人工智能服务的繁荣。
Amazon has been developing their in-house Trainium and Inferentia; neither is well-suited for large language models. They are designed in collaboration with Taiwanese firm AlChip. While there are glimpses of excellence, especially when using CFP8 with stochastic rounding, in general, they are not competitive even after heavy discounting. Amazon may narrow the gap in raw compute hardware over time, even if they remain behind Nvidia and Google. Furthermore, they will be able to leverage the PyTorch 2.0 and OpenAI Triton ecosystem to close the gap in software.
亚马逊一直在开发其内部的 Trainium 和 Inferentia;这两者都不太适合大型语言模型。它们是与台湾公司 AlChip 合作设计的。尽管在使用 CFP8 和随机舍入时有一些卓越的表现,但总体而言,即使在大幅打折后,它们也没有竞争力。亚马逊可能会随着时间的推移缩小原始计算硬件的差距,即使他们仍然落后于英伟达和谷歌。此外,他们将能够利用 PyTorch 2.0 和 OpenAI Triton 生态系统来缩小软件方面的差距。
In-house silicon is only part of the equation. The obvious answer is that Amazon can just as easily adopt external silicon at the same cost as any other cloud, right… well, not exactly.
内部硅只是方程的一部分。显而易见的答案是,亚马逊可以以与其他云服务相同的成本轻松采用外部硅,对吧……其实并不是这样。
Amazon Purposely Handicapping AI At AWS
亚马逊故意限制 AWS 的人工智能
Amazon is actively hampering its efforts in AI clusters. Compute is only part of the equation. Networking is the other side and arguably just as important.
亚马逊正在积极阻碍其在人工智能集群中的努力。计算只是方程的一部分。网络是另一面,且可以说同样重要。
Rather than implement the best networking from Nvidia and/or Broadcom, Amazon is using its own Nitro and Elastic Fabric Adaptor (EFA) networking. This works well for many workloads, plus it delivers a cost, performance, and security advantage.
亚马逊并没有采用 Nvidia 和/或 Broadcom 的最佳网络,而是使用了自己的 Nitro 和弹性网络适配器(EFA)网络。这对于许多工作负载来说效果良好,并且在成本、性能和安全性方面具有优势。
There are business, cultural, and security reasons why Amazon will not implement other networking. The cultural one is important. Nitro and networking SoC’s generally have been Amazon’s biggest cost advantage for years. It’s ingrained into their DNA. Even EFA delivers on this too, but they don’t see how new workloads are evolving and that a new tier is needed due to the lack of foresight in their internal workload and infrastructure teams.
亚马逊不实施其他网络的原因包括商业、文化和安全方面的考虑。文化因素非常重要。Nitro 和网络 SoC 多年来一直是亚马逊最大的成本优势。这已深深植根于他们的 DNA 中。即使是 EFA 也在这方面有所贡献,但他们没有看到新工作负载的演变,缺乏对内部工作负载和基础设施团队的前瞻性,导致需要一个新的层级。
Amazon is making a deliberate choice of not adopting that we believe will bite them in the future.
亚马逊正在故意选择不采纳我们认为将来会对他们造成影响的做法。
Amazon believes its approach is superior to what merchant silicon providers such as Nvidia are implementing, even on performance. The future of datacenters is with composable server architectures that provide scalable heterogeneous compute with support for memory pooling and sharing to break through the memory wall.
亚马逊认为其方法优于像英伟达这样的商用硅提供商所实施的方法,甚至在性能上也是如此。数据中心的未来在于可组合的服务器架构,这种架构提供可扩展的异构计算,并支持内存池和共享,以突破内存瓶颈。
Amazon still hasn’t even joined the CXL consortium. Furthermore, multiple AWS sources (with permission to share) tell us Amazon will not deploy 3rd party composable fabrics between nodes from Nvidia, although Amazon is working on something.
亚马逊仍然没有加入 CXL 联盟。此外,多位 AWS 消息来源(获得分享许可)告诉我们,亚马逊不会在 Nvidia 的节点之间部署第三方可组合的网络,尽管亚马逊正在开发某些东西。
AI clusters do not need many of the features in CXL, but they do need a few of these features. Specifically, high bandwidth coherent fabrics. Nvidia’s NVLink is a proprietary coherent interconnect between GPUs that implements some features of CXL.
AI 集群不需要 CXL 中的许多功能,但确实需要其中的一些功能。具体来说,高带宽一致性网络。Nvidia 的 NVLink 是一种专有的 GPU 之间的一致性互连,实施了 CXL 的一些功能。
Arguably Nvidia’s biggest improvement in the new H100 GPU is the introduction of scale-up NVLink. This scales Nvidia’s NVLink proprietary interconnect up to multiple servers rather than only within a single server like the prior generation.
可以说,Nvidia 在新 H100 GPU 中最大的改进是引入了可扩展的 NVLink。这使得 Nvidia 的 NVLink 专有互连可以扩展到多个服务器,而不仅仅局限于像前一代那样的单个服务器内。
Amazon is refusing to deploy Nvidia’s current solution beyond a single node. While the reason we were given was security, it is likely because they do not control Nvidia’s NVLink. This hampers AI significantly by forcing strict boundaries on nodes and inhibiting scalability, performance, and memory transactions.
亚马逊拒绝在单个节点之外部署英伟达的当前解决方案。虽然我们得到的理由是安全性,但这很可能是因为他们无法控制英伟达的 NVLink。这大大限制了人工智能,强制对节点施加严格的边界,抑制了可扩展性、性能和内存事务。
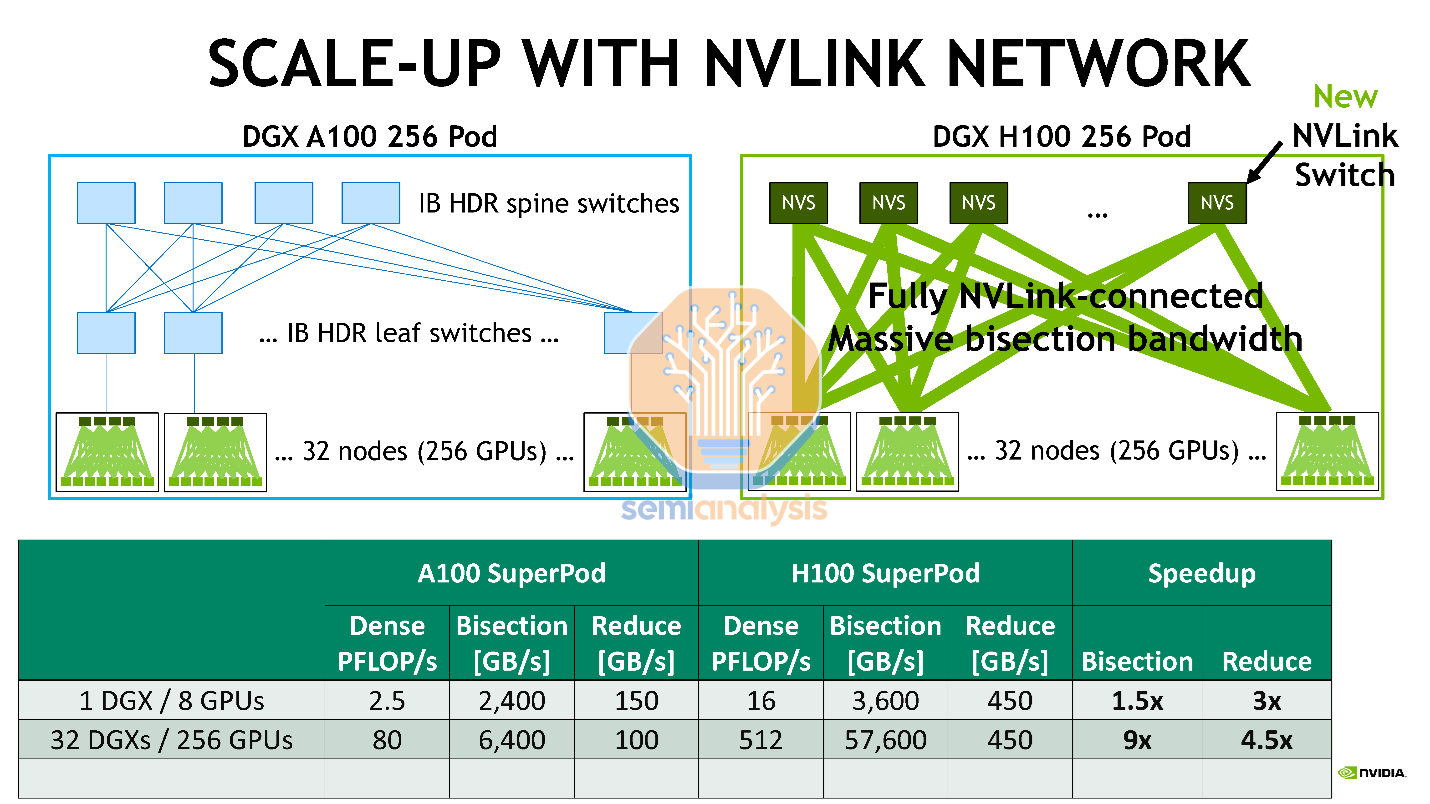
Furthermore, Nvidia’s NVLink network uses switches that can perform some compute functions, such as AllReduce. This will dramatically improve one of the biggest bottlenecks in training.
此外,Nvidia 的 NVLink 网络使用可以执行一些计算功能的交换机,例如 AllReduce。这将显著改善训练中的最大瓶颈之一。
In total, Nvidia claims H100 performance is improved by more than 3.5x when using NVLink between GPU Nodes in a large distributed system for the most advanced network types (MoE Switch-XXL). This is an important point. Less advanced models such as GPT-3 16B parameter and 175B parameter do not scale a significant amount, but newer model architectures will. GPT4 is a mixture of experts multi-modal LLM, similar to MoE Switch on architecture, at least more so than any other model in Nvidia’s performance claims.
总的来说,Nvidia 声称在大型分布式系统中使用 NVLink 连接 GPU 节点时,H100 的性能提高了超过 3.5 倍,适用于最先进的网络类型(MoE Switch-XXL)。这是一个重要的观点。像 GPT-3 16B 参数和 175B 参数这样的较旧模型并没有显著扩展,但更新的模型架构会。GPT4 是一个专家混合的多模态LLM,在架构上类似于 MoE Switch,至少比 Nvidia 的其他性能声明中的任何模型更为相似。
By refusing to implement Nvidia’s NVLink fabric, Amazon effectively kills one of the biggest selling points of Nvidia’s AI architecture while also putting itself at a huge disadvantage. Others are cautious about implementing Nvidia’s NVLink, with initial systems going without it, but when Grace Hopper arrives, it will practically be mandatory.
通过拒绝实施 Nvidia 的 NVLink 架构,亚马逊实际上扼杀了 Nvidia AI 架构最大的卖点之一,同时也使自己处于巨大的劣势。其他公司在实施 Nvidia 的 NVLink 时持谨慎态度,初始系统没有采用,但当 Grace Hopper 到来时,这几乎是强制性的。
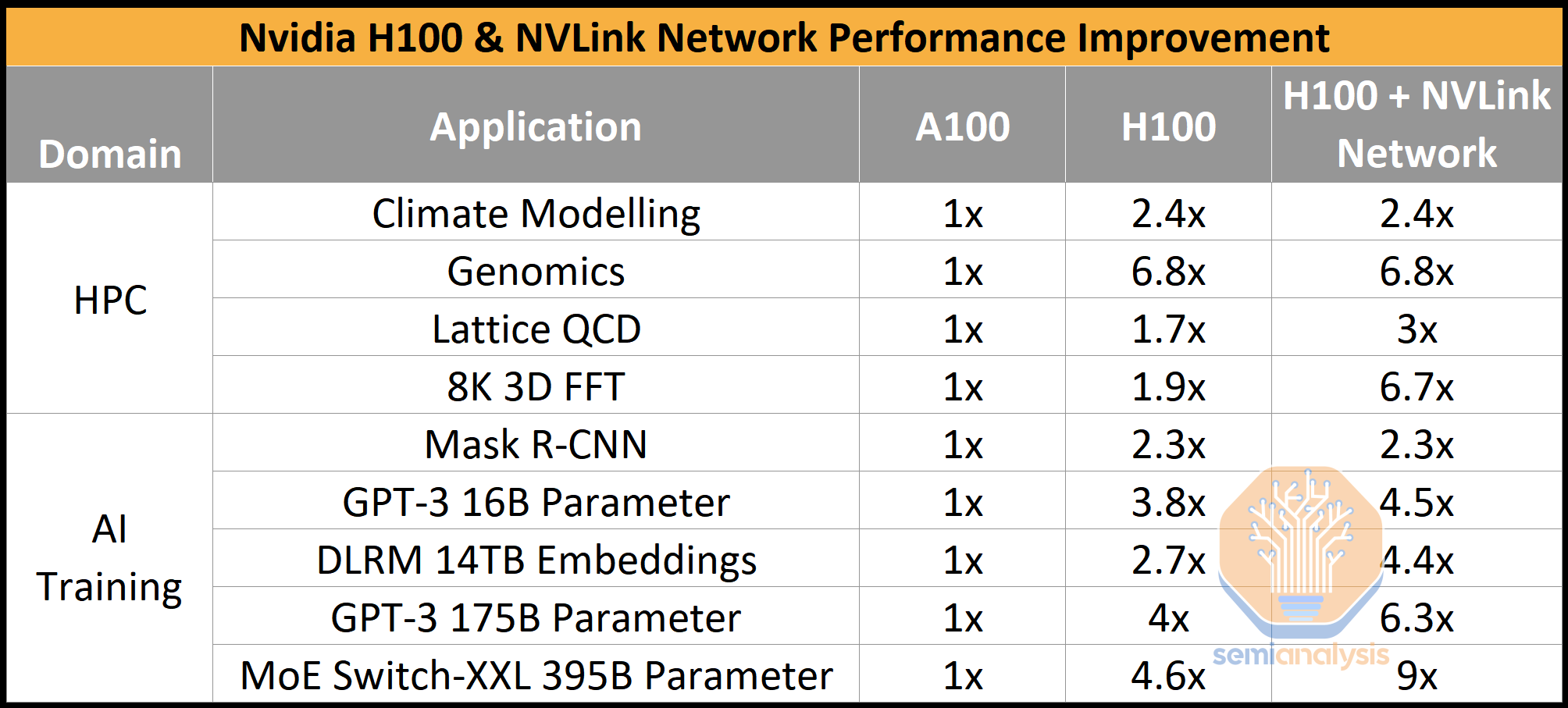
Nvidia 预测性能 - A100 集群:HDR IB 网络,H100 集群:NDR IB 网络,带有 NVLink 网络(如有指示) - GPU 数量:气候建模 1K,LQCD 1K,基因组学 8,3D-FFT 256,MRCNN 8(批次 32),GPT-3 16B 512(批次 256),DLRM 128(批次 64k),GPT-3 175B 16k(批次 512),MoE 8k(批次 512,每个 GPU 一个专家)
Me Too Clouds 我也是云
At least some other clouds will implement out-of-node NVLink. That’s where the discussion of prioritization now comes in. AI GPUs face tremendous shortages, for at least a full year. This is one of the most pivotal times for AI, and it may mark the haves and the have-nots.
至少其他一些云服务将实现节点外的 NVLink。这就是优先级讨论的所在。AI GPU 面临着巨大的短缺,至少持续一年。这是 AI 最关键的时刻之一,可能会标志着有与没有之间的差距。
Nvidia is a complete monopoly right now. Why would Nvidia prioritize Amazon for these GPUs, when they know Amazon will move to their in-house chips as quickly as they can, for as many compute workloads as they can? Why would Nvidia ship tons of GPUs to the cloud that is not using any of their networking, thereby reducing their share of wallet?
英伟达目前是一个完全的垄断。为什么英伟达会优先考虑亚马逊的这些 GPU,明明知道亚马逊会尽快转向自家芯片,尽可能多地用于计算工作负载?为什么英伟达会向不使用其任何网络的云服务运输大量 GPU,从而减少他们的市场份额?
Instead, Nvidia prioritizes the me-too clouds. Amazon does get meaningful volume, but nowhere close to where demand is. Amazon’s H100 GPU shipments relative to public cloud shipments is a significantly lower than their share of the public cloud. Those other clouds also can’t satisfy demand, but they get a bigger percentage of the GPUs they ask Nvidia for, and as such, firms looking for GPUs for training or inference will move to those clouds. Nvidia is the kingmaker right now, and they are capitalizing on it. They have to spread the balance of power out to prevent compute share from clustering towards Amazon.
相反,英伟达优先考虑那些跟风的云服务。亚马逊确实获得了可观的量,但远未达到需求的水平。亚马逊的 H100 GPU 出货量相对于公共云出货量显著低于其在公共云中的份额。其他云服务同样无法满足需求,但它们获得的 GPU 比例更大,因此,寻求用于训练或推理的 GPU 的公司将转向这些云服务。英伟达目前是行业的主导者,他们正在利用这一点。他们必须分散权力平衡,以防计算份额向亚马逊集中。
Not only are many of these other clouds unable to scale to the point where they have their own AI silicon, they are also mostly further behind. Even giants like Microsoft are much further behind in the push to in-house networking and AI hardware. Furthermore, by giving larger allocations to the me-too clouds, it will also give Nvidia a higher share of the wallet by the virtue of them implementing their networking, whether NIC, DPU, InfiniBand switch, Ethernet switch, or NVLink.
不仅这些其他云服务无法扩展到拥有自己的 AI 硅芯片的程度,它们在这方面也大多落后得更远。即使是像微软这样的巨头,在内部网络和 AI 硬件的推进上也远远落后。此外,通过给予这些跟风云服务更大的分配,Nvidia 也将因它们实施自己的网络(无论是 NIC、DPU、InfiniBand 交换机、以太网交换机还是 NVLink)而获得更高的市场份额。
Oracle's Gen 2 Cloud is quite different than the other hyperscalers. We have an RDMA network, a nonblocking RDMA network. Our network is very much faster than the other guys' network. What this means is if you're running a large group of Nvidia GPUs in a cluster doing a large AI problem at Oracle, we can build these AI clusters, these Nvidia GPU clusters, and run them.
甲骨文的第二代云与其他超大规模云服务提供商大相径庭。我们拥有一个 RDMA 网络,一个非阻塞的 RDMA 网络。我们的网络速度远快于其他公司的网络。这意味着,如果您在甲骨文的集群中运行一大组 Nvidia GPU 来处理大型 AI 问题,我们可以构建这些 AI 集群,这些 Nvidia GPU 集群,并进行运行。We can build those things dynamically because we use -- our standard network supports the clustering, the large clustering of GPUs and allows them to communicate very quickly. So we can create these groups of GPUs. We can marshal them together. The other guys can't do that.
我们可以动态构建这些东西,因为我们的标准网络支持 GPU 的大规模集群,并允许它们快速通信。因此,我们可以创建这些 GPU 组。我们可以将它们集中在一起。其他人做不到这一点。They can build clusters, but they actually literally are physically building a new cluster. They're building new hardware. Our existing hardware, standard network, allows us to group these things together dynamically, these GPUs together dynamically, to attack AI problems. No one else can do that.
他们可以构建集群,但实际上他们确实是在物理上构建一个新的集群。他们正在构建新的硬件。我们现有的硬件、标准网络,允许我们动态地将这些东西组合在一起,这些 GPU 动态地组合在一起,以解决 AI 问题。没有其他人可以做到这一点。Larry Ellison, Chairman and founder of Oracle
拉里·埃里森,甲骨文公司董事长兼创始人
Larry is exaggerating a bit here, but he is mostly right on the networking side. Note Oracle is using mostly ethernet with Bluefield DPUs and ConnectX NICs, although there are plans to adopt out-of-node NVLink, especially with Grace Hopper and within the Nvidia Cloud. Other clouds such as Coreweave, Lambda, and Equinix are also getting far outsized shipment numbers of Nvidia’s GPUs relative to their market shares.
拉里在这里有点夸大,但他在网络方面大体上是正确的。请注意,Oracle 主要使用以太网与 Bluefield DPU 和 ConnectX NIC,尽管有计划采用节点外的 NVLink,特别是在 Grace Hopper 和 Nvidia Cloud 中。其他云服务如 Coreweave、Lambda 和 Equinix 相对于其市场份额也获得了远超出预期的 Nvidia GPU 出货量。
Other minor cloud players, such as IBM Cloud, are also getting some shipments, but they are not deploying any Nvidia’s networking. IBM is selling AI as a service to enterprises more effectively than AWS is, which speaks a lot about how far behind AWS really is here. IBM Cloud is, of course, behind in many other ways, so not a legitimate competitor by any means. Microsoft is using Infiniband networking and will adopt NVLink out of node when it ramps as well.
其他小型云服务提供商,如 IBM Cloud,也在获得一些发货,但他们并没有部署任何 Nvidia 的网络。IBM 在向企业销售 AI 作为服务方面比 AWS 更有效,这充分说明了 AWS 在这方面的落后。IBM Cloud 在许多其他方面当然也落后,因此绝对不是一个真正的竞争对手。微软正在使用 Infiniband 网络,并将在其扩展时采用 NVLink。
Amazon is losing share in AI due to the lower share of Nvidia H100 clusters. Amazon’s ability to grow in the hottest vertical is capped more so than the other clouds. While Amazon’s biggest bull case is that they are indexed to some of the highest growth tech sectors by being their infrastructure provider, these same customers may also have to go elsewhere to get GPUs for AI training and inference or AI APIs to deploy AI in their SAAS.
亚马逊在人工智能领域的市场份额正在下降,原因是 Nvidia H100 集群的份额较低。亚马逊在最热门的垂直市场中的增长能力受到的限制比其他云服务商更大。尽管亚马逊最大的看涨理由是作为一些增长最快的科技行业的基础设施提供商,但这些客户可能也需要去其他地方获取用于人工智能训练和推理的 GPU 或用于在其 SAAS 中部署人工智能的 AI API。
Nvidia Cloud 英伟达云
We will dive deeply into Nvidia’s cloud in another piece in the future, but they are also prioritizing GPU shipments to those clouds who are playing ball with them on their cloud pivot too. Nvidia is using some of the clouds, like a relatively lower margin DGX as a service operation + balance sheet. This includes Microsoft, Oracle, Google, and some minor players such as Coreweave, Equinix, and Lambda. Amazon is sticking out like a sore thumb.
我们将在未来的另一篇文章中深入探讨 Nvidia 的云,但他们也在优先向那些与他们在云转型上合作的云服务商发货 GPU。Nvidia 正在利用一些云服务,比如相对较低利润的 DGX 作为服务运营+资产负债表。这包括微软、甲骨文、谷歌以及一些小型参与者,如 Coreweave、Equinix 和 Lambda。亚马逊显得格外突出。
Nvidia’s AI as a service will be available in every major cloud vendor’s cloud except Amazon. This is another incremental point that will drive Amazon’s computing share of AI lower than their share of storage, and general-purpose compute.
英伟达的人工智能服务将会在除亚马逊之外的每个主要云服务提供商的云中提供。这是另一个将推动亚马逊在人工智能计算份额低于其存储和通用计算份额的增量因素。
Microsoft 微软
Microsoft, in general, has chosen the better strategy of being amicable and friendly with the world’s most valuable semiconductor companies.
微软总体上选择了与全球最有价值的半导体公司保持友好和友善的更好策略。
Microsoft, with its ruthlessly commercial attitude and extensive range of enterprise-oriented services, has been particularly adept at leveraging its cloud offerings to drive sales of higher-margin service products. While this has kept SAAS companies wary of Microsoft in the same way Walmart and other enterprises are wary of Amazon, Microsoft's strength lies in its ability to cross-sell and bundle services.
微软以其无情的商业态度和广泛的企业导向服务,特别擅长利用其云服务推动高利润服务产品的销售。这使得 SAAS 公司对微软保持警惕,就像沃尔玛和其他企业对亚马逊保持警惕一样。微软的优势在于其交叉销售和捆绑服务的能力。
Microsoft is offering seamless integration of cloud-based products that cater to various enterprise needs. This integration not only drives customer loyalty but also fosters a more comprehensive ecosystem that creates a strong competitive advantage and lock-in.
微软提供无缝集成的基于云的产品,以满足各种企业需求。这种集成不仅推动了客户忠诚度,还促进了一个更全面的生态系统,创造了强大的竞争优势和锁定效应。
There is a fundamental feedback loop that Microsoft has that perhaps no other company does. No other company has access to enterprise data in the way Microsoft does. Not all of Microsoft’s services are leadership today, but when you look at their unique control in all other aspects, it will quickly start to become apparent that even trailing areas such as Dynamics CRM/ERP could gain share over time versus the titans of Salesforce and SAP.
微软拥有一个基本的反馈循环,或许没有其他公司具备。没有其他公司能够像微软那样访问企业数据。并非微软的所有服务今天都是领导者,但当你观察他们在其他所有方面的独特控制时,很快就会显现出,即使是像 Dynamics CRM/ERP 这样的滞后领域,随着时间的推移,也可能在与 Salesforce 和 SAP 的竞争中获得市场份额。
Office, Outlook, OneDrive, Microsoft 365, Dynamics, PowerBI, LinkedIn, and GitHub are all parts of the equation. The gas really hits the peddle when Microsoft can leverage these together with multi-modal large language models from OpenAI. Co-pilot in GitHub is already in a tremendously powerful position vs the likes of Gitlab long term due to this. This trend will only extend as Bing Search APIs can be used by enterprises on their existing files.
办公室、Outlook、OneDrive、Microsoft 365、Dynamics、PowerBI、LinkedIn 和 GitHub 都是这个方程的一部分。当微软能够将这些与 OpenAI 的多模态大型语言模型结合起来时,真正的推动力就会出现。由于这一点,GitHub 中的 Co-pilot 在长期内已经处于相对于 Gitlab 的极其强大的位置。随着企业可以在其现有文件上使用 Bing 搜索 API,这一趋势只会进一步延伸。
If you saw the Microsoft Office Co-pilot event, holy cow. How can Amazon of their customers ever offer something even close? Most enterprises will end up giving Microsoft even more access to their enterprise’s dataset. The unified experience across the entire spectrum of platforms makes it difficult for customers to switch to alternative solutions in any individual space because all-Microsoft solutions are going to drive more productivity and bundling. Microsoft integrating AI into all facets of its product suite will grow its cloud and SAAS share.
如果你看了微软 Office Co-pilot 活动,真是太惊人了。亚马逊的客户怎么可能提供接近的东西呢?大多数企业最终会给予微软更多对其企业数据集的访问权限。跨整个平台的统一体验使得客户在任何单一领域转向替代解决方案变得困难,因为全微软解决方案将推动更多的生产力和捆绑。微软将人工智能整合到其产品套件的各个方面,将增加其云和 SAAS 市场份额。
Ultimately, this will enable Microsoft to grab a bigger share of computing dollars.
最终,这将使微软能够获得更大份额的计算资金。
Google 谷歌
Google is far ahead of Amazon on AI silicon. In some ways, they are even ahead of Nvidia too. One such example is their coherent fabric, which has been deployed in 4,000 TPU pods since 2021, whereas Nvidia only started in 2023 with 256 GPU pods. Furthermore, Google is not betting it all internally. They are working closely with Nvidia by supporting Nvidia’s Cloud and AI as service offerings.
谷歌在人工智能硅芯片方面远远领先于亚马逊。在某些方面,他们甚至领先于英伟达。一个这样的例子是他们的连贯网络,自 2021 年以来已在 4000 个 TPU 集群中部署,而英伟达直到 2023 年才开始使用 256 个 GPU 集群。此外,谷歌并没有完全依赖内部开发。他们与英伟达紧密合作,支持英伟达的云计算和人工智能服务。
Google also has a good shot at succeeding in AI as service offerings across search, workspace, email, APIs, and more. Google is still a leader in AI despite what the pundits say, and the renewed effort ever since the ChatGPT and Bing wake-up call is reinvigorating the organization on commercial products. Google also has a structural cost advantage on the compute and networking required for these tasks that no one other than Nvidia can replicate.
谷歌在搜索、工作区、电子邮件、API 等服务提供方面也有很好的机会在人工智能领域取得成功。尽管评论人士有不同看法,谷歌仍然是人工智能的领导者,自从 ChatGPT 和必应的警示以来,谷歌的重振努力正在为商业产品注入活力。谷歌在这些任务所需的计算和网络方面也具有结构性成本优势,除了英伟达,没有其他公司能够复制这一点。
While we spoke a lot about training above, it should be noted that the coherent network is incredibly important for inference too.
虽然我们在上面谈了很多关于培训的内容,但需要注意的是,连贯的网络对于推理也非常重要。
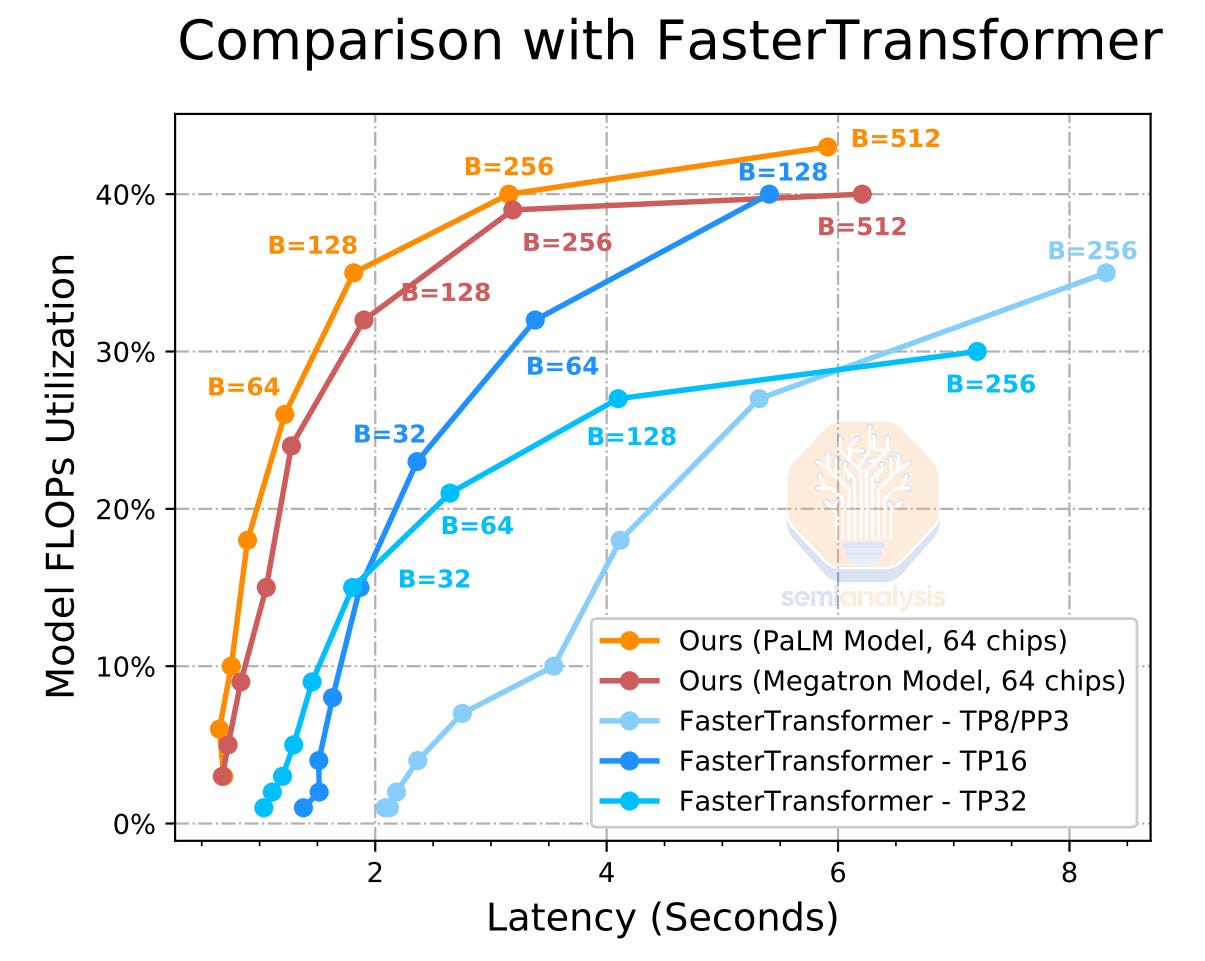
Google has shows that you have to have a high-speed coherent fabric to even run large models like PaLM effectively.
谷歌显示,要有效运行像 PaLM 这样的大型模型,您必须拥有高速一致的网络。
Inference is not done on a single GPU/TPU today. For example, ChatGPT runs on 8xA100 boxes, and an obvious cost improvement for them will be to move to multi-server AI clusters. Google has shown that you get higher utilization rates (cost improvements) and lower latency (better user experience) by moving beyond a single server for serving a large language model. Multi-server inference will require these coherent fabrics to scale past the memory wall, especially as mixture of expert models balloon memory requirements.
推理今天并不是在单个 GPU/TPU 上进行的。例如,ChatGPT 运行在 8 个 A100 服务器上,显而易见的成本改进将是转向多服务器 AI 集群。谷歌已经表明,通过超越单一服务器来服务大型语言模型,可以获得更高的利用率(成本改进)和更低的延迟(更好的用户体验)。多服务器推理将需要这些一致的架构来突破内存瓶颈,特别是当专家模型的混合膨胀内存需求时。
Amazon does not have this internally as Google does, and they aren’t willing to play ball with Nvidia to implement this either.
亚马逊内部没有像谷歌那样的资源,他们也不愿意与英伟达合作来实现这一点。
Google is even deploying Nvidia's nee L4 inference GPU for video and image AIs first, which speaks volumes about the partnership given Google has TPU.
谷歌甚至首先部署了英伟达的新 L4 推理 GPU 用于视频和图像 AI,这充分说明了双方的合作关系,因为谷歌拥有 TPU。
Conclusion 结论
As the cloud computing market continues to evolve, Amazon faces significant challenges in maintaining its current dominance over computing. The rise of commodity competition on the infrastructure side from me-too clouds, the lack of ability to enter the service market like Microsoft Azure, Google Cloud Platform, and Nvidia cloud, and refusal due to implement the best AI infrastructure due to cultural and business reasons will all be incredibly tough challenges.
随着云计算市场的不断发展,亚马逊在维持其当前的计算主导地位方面面临重大挑战。来自同类云服务的基础设施竞争的崛起,无法像微软 Azure、谷歌云平台和英伟达云那样进入服务市场,以及由于文化和商业原因拒绝实施最佳 AI 基础设施,这些都将是极其艰巨的挑战。
Amazon cannot shift towards the Software-as-a-Service model. Furthermore, they are a share donor in AI infrastructure. While Amazon will continue to be tremendously profitable as they are indexed to many higher-growth customers in compute and storage, they will be a slower grower than competitors for the next phase of computing. We do not believe that Amazon will be able to maintain its leadership position in the computing.
亚马逊无法转向软件即服务模型。此外,他们在人工智能基础设施中是一个股份捐赠者。虽然亚马逊将继续非常盈利,因为他们与许多高增长的计算和存储客户挂钩,但在下一个计算阶段,他们的增长速度将比竞争对手慢。我们不相信亚马逊能够维持其在计算领域的领导地位。
Book a meeting with SemiAnalysis
与 SemiAnalysis 预约会议
Schedule a meeting 安排会议














Why are Trainium and Inferentia not well-suited for large language models? Is this specifically because of the EFA vs. NVLink choice?
Trainium 和 Inferentia 为什么不适合大型语言模型?这是否特别与 EFA 与 NVLink 的选择有关?
8 条回复来自 Dylan Patel 及其他人
Good stuff, some comments/questions:
好的东西,有一些评论/问题:
1) I'd question the underlying premise that these LLM models will be deployed at their as-is giant size. Given how fast GPT3.5 Turbo at 90% lower cost came along, I suspect we'll see all these LLMs get pruned/distilled down to something much more manageable. Fair to say the need for NVLink across DGX systems become less of an issue if the LLM models that are ultimately deployed at scale are much smaller? Say 10-50B parameters instead of 100-500B?
1) 我会质疑这些LLM模型将以其原始巨型规模部署的基本前提。考虑到 GPT3.5 Turbo 以 90%更低的成本快速出现,我怀疑我们会看到所有这些LLMs被修剪/提炼成更易于管理的东西。如果最终大规模部署的LLM模型要小得多,比如 10-50B 参数而不是 100-500B,那么在 DGX 系统之间对 NVLink 的需求是否就不那么重要了?
2) I'd also question the underlying premise that these LLMs won't be commoditized quickly (that AWS will take years to catch up). A) they can always inorganically acquire that capability (which is sort of what MSFT did with OpenAI), B) Stanford's Alpaca showcased how easy it is to copy these LLM models (which claims GPT 3.5 performance at 7B param size). Thoughts on commoditization risk?
2) 我也质疑这些LLMs不会迅速商品化的基本前提(即 AWS 需要多年才能赶上)。A) 他们总是可以通过非有机方式获得这种能力(这有点像 MSFT 与 OpenAI 的做法),B) 斯坦福的 Alpaca 展示了复制这些LLM模型是多么简单(声称在 7B 参数大小下达到 GPT 3.5 的性能)。对商品化风险的看法?
3) How does AWS Inferentia2 (previewed at 2022 AWS Reinvent) stack up against Grace+H100 inference in terms of price performance, any guesses based on what you know/heard?
3) AWS Inferentia2(在 2022 AWS Reinvent 上预览)在价格性能方面与 Grace+H100 推理相比如何,基于你所知道/听到的,有什么猜测吗?
3)
1 条回复来自迪伦·帕特尔