
Generative AI’s Act o1 生成式 AI 的 Act o1
代理推理时代开始
Two years into the Generative AI revolution, research is progressing the field from “thinking fast”—rapid-fire pre-trained responses—to “thinking slow”— reasoning at inference time. This evolution is unlocking a new cohort of agentic applications.
生成式人工智能革命已经过去两年了,该领域的研究正在从“快速思考”(快速预训练响应)发展到“慢速思考”(推理时推理)。这一演变正在释放一批新的代理应用程序。
On the second anniversary of our essay “Generative AI: A Creative New World,” the AI ecosystem looks very different, and we have some predictions for what’s on the horizon.
在我们的文章“生成人工智能:创意新世界”发表两周年之际,人工智能生态系统看起来非常不同,我们对即将发生的事情有一些预测。
The foundation layer of the Generative AI market is stabilizing in an equilibrium with a key set of scaled players and alliances, including Microsoft/OpenAI, AWS/Anthropic, Meta and Google/DeepMind. Only scaled players with economic engines and access to vast sums of capital remain in play. While the fight is far from over (and keeps escalating in a game-theoretic fashion), the market structure itself is solidifying, and it’s clear that we will have increasingly cheap and plentiful next-token predictions.
生成式 AI 市场的基础层正在与一组关键的规模化参与者和联盟保持平衡,包括 Microsoft/OpenAI、AWS/Anthropic、Meta 和 Google/DeepMind。只有拥有经济引擎并能获得大量资本的规模化企业才能继续发挥作用。虽然战斗还远未结束(并且以博弈论的方式不断升级),但市场结构本身正在巩固,而且很明显,我们将拥有越来越便宜和丰富的下一个代币预测。
As the LLM market structure stabilizes, the next frontier is now emerging. The focus is shifting to the development and scaling of the reasoning layer, where “System 2” thinking takes precedence. Inspired by models like AlphaGo, this layer aims to endow AI systems with deliberate reasoning, problem-solving and cognitive operations at inference time that go beyond rapid pattern matching. And new cognitive architectures and user interfaces are shaping how these reasoning capabilities are delivered to and interact with users.
随着LLM市场结构的稳定,下一个前沿正在出现。重点正在转向推理层的开发和扩展,其中“系统 2”思维优先。受 AlphaGo 等模型的启发,这一层旨在赋予人工智能系统在推理时进行深思熟虑的推理、解决问题和认知操作,而不仅仅是快速模式匹配。新的认知架构和用户界面正在塑造这些推理能力如何交付给用户并与用户交互。
What does all of this mean for founders in the AI market? What does this mean for incumbent software companies? And where do we, as investors, see the most promising layer for returns in the Generative AI stack?
这一切对人工智能市场的创始人意味着什么?这对现有软件公司意味着什么?作为投资者,我们在哪里看到生成式人工智能堆栈中最有希望获得回报的层?
In our latest essay on the state of the Generative AI market, we’ll explore how the consolidation of the foundational LLM layer has set the stage for the race to scale these higher-order reasoning and agentic capabilities, and discuss a new generation of “killer apps” with novel cognitive architectures and user interfaces.
在我们关于生成人工智能市场状况的最新文章中,我们将探讨基础LLM层的巩固如何为扩展这些高阶推理和代理能力的竞赛奠定基础,并讨论新一代“杀手级应用程序”具有新颖的认知架构和用户界面。
Strawberry Fields Forever
永远的草莓地
The most important model update of 2024 goes to OpenAI with o1, formerly known as Q* and also known as Strawberry. This is not just a reassertion of OpenAI’s rightful place atop the model quality leaderboards, but also a notable improvement on the status quo architecture. More specifically, this is the first example of a model with true general reasoning capabilities, which they’ve achieved with inference-time compute.
2024 年最重要的模型更新是 OpenAI 和 o1,以前称为 Q*,也称为 Strawberry。这不仅重申了 OpenAI 在模型质量排行榜上的应有地位,而且也是对现状架构的显着改进。更具体地说,这是具有真正通用推理能力的模型的第一个示例,他们通过推理时间计算实现了这一能力。
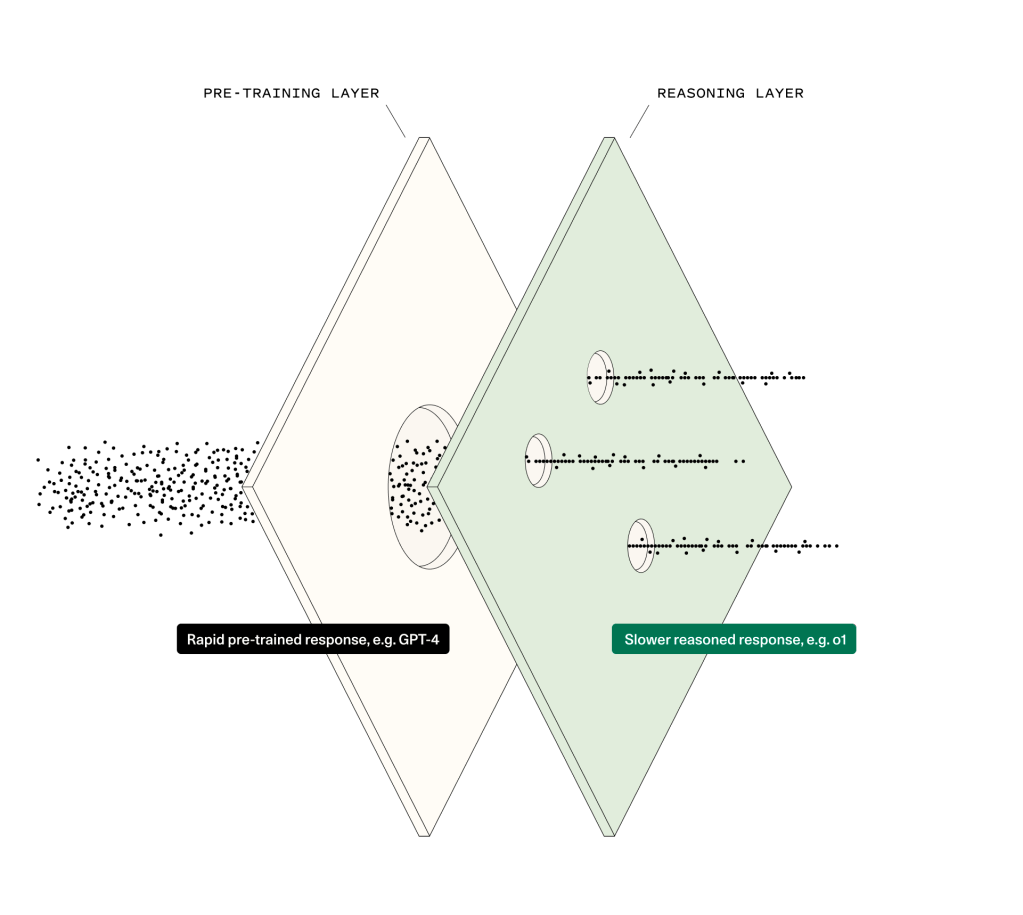
What does that mean? Pre-trained models are doing next token prediction on an enormous amount of data. They rely on “training-time compute.” An emergent property of scale is basic reasoning, but this reasoning is very limited. What if you could teach a model to reason more directly? This is essentially what’s happening with Strawberry. When we say “inference-time compute” what we mean is asking the model to stop and think before giving you a response, which requires more compute at inference time (hence “inference-time compute”). The “stop and think” part is reasoning.
这意味着什么?预先训练的模型正在对大量数据进行下一个标记预测。他们依赖于“训练时计算”。规模的一个突现属性是基本推理,但这种推理非常有限。如果你可以教模型更直接地推理怎么办?这基本上就是草莓发生的情况。当我们说“推理时计算”时,我们的意思是要求模型在给出响应之前停下来思考,这需要在推理时进行更多计算(因此是“推理时计算”)。 “停下来思考”部分是推理。
AlphaGo x LLMs
So what is the model doing when it stops and thinks?
那么当模型停下来思考时它在做什么呢?
Let’s first take a quick detour to March 2016 in Seoul. One of the most seminal moments in deep learning history took place here: AlphaGo’s match against legendary Go master Lee Sedol. This wasn’t just any AI-vs-human match—it was the moment the world saw AI do more than just mimic patterns. It was thinking.
让我们先快速回顾一下 2016 年 3 月的首尔。深度学习历史上最具影响力的时刻之一就发生在这里:AlphaGo 与传奇围棋大师李世石的比赛。这不仅仅是一场人工智能与人类的比赛——这是世界看到人工智能不仅仅能模仿模式的那一刻。它正在思考。
What made AlphaGo different from previous gameplay AI systems, like Deep Blue? Like LLMs, AlphaGo was first pre-trained to mimic human experts from a database of roughly 30 million moves from previous games and more from self-play. But rather than provide a knee jerk response that comes out of the pre-trained model, AlphaGo takes the time to stop and think. At inference time, the model runs a search or simulation across a wide range of potential future scenarios, scores those scenarios, and then responds with the scenario (or answer) that has the highest expected value. The more time AlphaGo is given, the better it performs. With zero inference-time compute, the model can’t beat the best human players. But as the inference time scales, AlphaGo gets better and better—until it surpasses the very best humans.
AlphaGo 与之前的游戏人工智能系统(如深蓝)有何不同?与LLMs一样,AlphaGo 首先经过预先训练,以模仿人类专家的数据库,该数据库包含之前游戏中的大约 3000 万步棋以及更多来自自我对弈的棋步。但 AlphaGo 并没有提供来自预训练模型的下意识反应,而是花时间停下来思考。在推理时,模型会在各种潜在的未来场景中运行搜索或模拟,对这些场景进行评分,然后以具有最高预期值的场景(或答案)进行响应。 AlphaGo 给予的时间越多,它的表现就越好。在零推理时间计算的情况下,该模型无法击败最好的人类玩家。但随着推理时间的延长,AlphaGo 会变得越来越好,直到超越最优秀的人类。
Let’s bring it back to the LLM world. What’s hard about replicating AlphaGo here is constructing the value function, or the function by which the responses are scored. If you’re playing Go, it’s more straightforward: you can simulate the game all the way to the end, see who wins, and then calculate an expected value of the next move. If you’re coding, it’s somewhat straightforward: you can test the code and see if it works. But how do you score the first draft of an essay? Or a travel itinerary? Or a summary of key terms in a long document? This is what makes reasoning hard with current methods, and it’s why Strawberry is comparatively strong on domains proximate to logic (e.g. coding, math, the sciences) and not as strong in domains that are more open-ended and unstructured (e.g. writing).
让我们把它带回LLM世界。在这里复制 AlphaGo 的困难在于构建价值函数,或者对响应进行评分的函数。如果你正在下围棋,那就更简单了:你可以一路模拟比赛到最后,看看谁赢了,然后计算下一步的预期值。如果您正在编码,那就有点简单了:您可以测试代码并查看它是否有效。但是如何给论文初稿打分呢?或者旅游行程?或者是长文档中关键术语的摘要?这就是为什么目前的方法很难进行推理,这就是为什么草莓在接近逻辑的领域(例如编码、数学、科学)相对较强,而在更开放和非结构化的领域(例如写作)则不那么强。
While the actual implementation of Strawberry is a closely guarded secret, the key ideas involve reinforcement learning around the chains of thought generated by the model. Auditing the model’s chains of thought suggests that something fundamental and exciting is happening that actually resembles how humans think and reason. For example, o1 is showing the ability to backtrack when it gets stuck as an emergent property of scaling inference time. It is also showing the ability to think about problems the way a human would (e.g. visualize the points on a sphere to solve a geometry problem) and to think about problems in new ways (e.g. solving problems in programming competitions in a way that humans would not).
And there is no shortage of new ideas to push forward inference-time compute (e.g. new ways of calculating the reward function, new ways of closing the generator/verifier gap) that research teams are working on as they try to improve the model’s reasoning capabilities. In other words, deep reinforcement learning is cool again, and it’s enabling an entire new reasoning layer.
System 1 vs System 2 Thinking
This leap from pre-trained instinctual responses (”System 1”) to deeper, deliberate reasoning (“System 2”) is the next frontier for AI. It’s not enough for models to simply know things—they need to pause, evaluate and reason through decisions in real time.
Think of pre-training as the System 1 layer. Whether a model is pre-trained on millions of moves in Go (AlphaGo) or petabytes of internet-scale text (LLMs), its job is to mimic patterns—whether that’s human gameplay or language. But mimicry, as powerful as it is, isn’t true reasoning. It can’t properly think its way through complex novel situations, especially those out of sample.
This is where System 2 thinking comes in, and it’s the focus of the latest wave of AI research. When a model “stops to think,” it isn’t just generating learned patterns or spitting out predictions based on past data. It’s generating a range of possibilities, considering potential outcomes and making a decision based on reasoning.
For many tasks, System 1 is more than enough. As Noam Brown pointed out on our latest episode of Training Data, thinking for longer about what the capital of Bhutan is doesn’t help—you either know it or you don’t. Quick, pattern-based recall works perfectly here.
But when we look at more complex problems—like breakthroughs in mathematics or biology—quick, instinctive responses don’t cut it. These advances required deep thinking, creative problem-solving and—most importantly—time. The same is true for AI. To tackle the most challenging, meaningful problems, AI will need to evolve beyond quick in-sample responses and take its time to come up with the kind of thoughtful reasoning that defines human progress.

A New Scaling Law: The Inference Race is On
The most important insight from the o1 paper is that there’s a new scaling law in town.
Pre-training LLMs follows a well understood scaling law: the more compute and data you spend on pre-training the model, the better it performs.
The o1 paper has opened up an entire new plane for scaling compute: the more inference-time (or “test-time”) compute you give the model, the better it reasons.
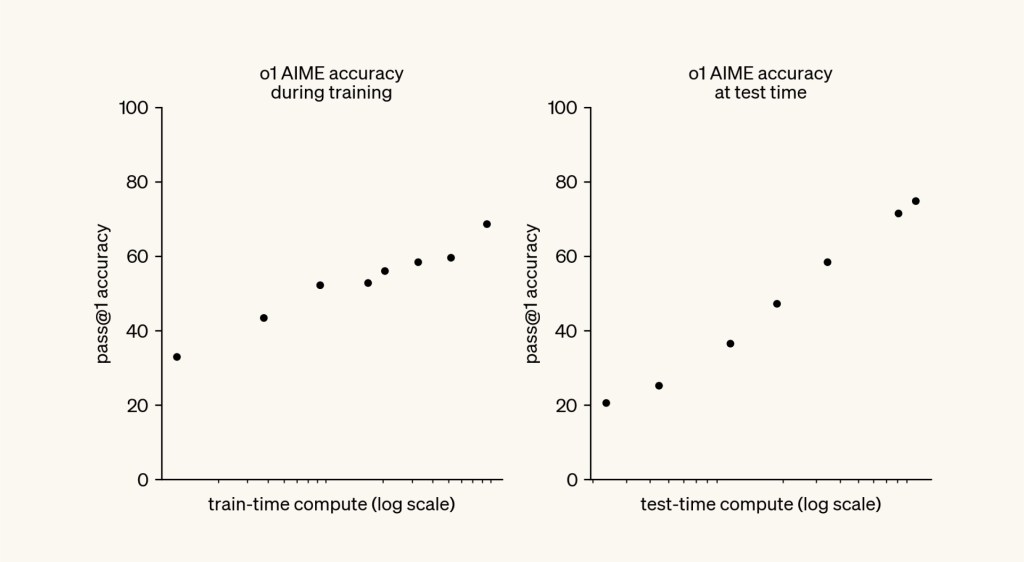
Source: OpenAI o1 technical report
What happens when the model can think for hours? Days? Decades? Will we solve the Riemann Hypothesis? Will we answer Asimov’s last question?
This shift will move us from a world of massive pre-training clusters toward inference clouds—environments that can scale compute dynamically based on the complexity of the task.
One Model to Rule Them All?
What happens as OpenAI, Anthropic, Google and Meta scale their reasoning layers and develop more and more powerful reasoning machines? Will we have one model to rule them all?
One hypothesis at the outset of the Generative AI market was that a single model company would become so powerful and all-encompassing that it would subsume all other applications. This prediction has been wrong so far in two ways.
First, there is plenty of competition at the model layer, with constant leapfrogging for SOTA capabilities. It’s possible that someone figures out continuous self-improvement with broad domain self play and achieves takeoff, but at the moment we have seen no evidence of this. Quite to the contrary, the model layer is a knife-fight, with price per token for GPT-4 coming down 98% since the last dev day.
Second, the models have largely failed to make it into the application layer as breakout products, with the notable exception of ChatGPT. The real world is messy. Great researchers don’t have the desire to understand the nitty gritty end-to-end workflows of every possible function in every possible vertical. It is both appealing and economically rational for them to stop at the API, and let the developer universe worry about the messiness of the real world. Good news for the application layer.
The Messy Real World: Custom Cognitive Architectures
The way you plan and prosecute actions to reach your goals as a scientist is vastly different from how you would work as a software engineer. Moreover, it’s even different as a software engineer at different companies.
As the research labs further push the boundaries on horizontal general-purpose reasoning, we still need application or domain-specific reasoning to deliver useful AI agents. The messy real world requires significant domain and application-specific reasoning that cannot efficiently be encoded in a general model.
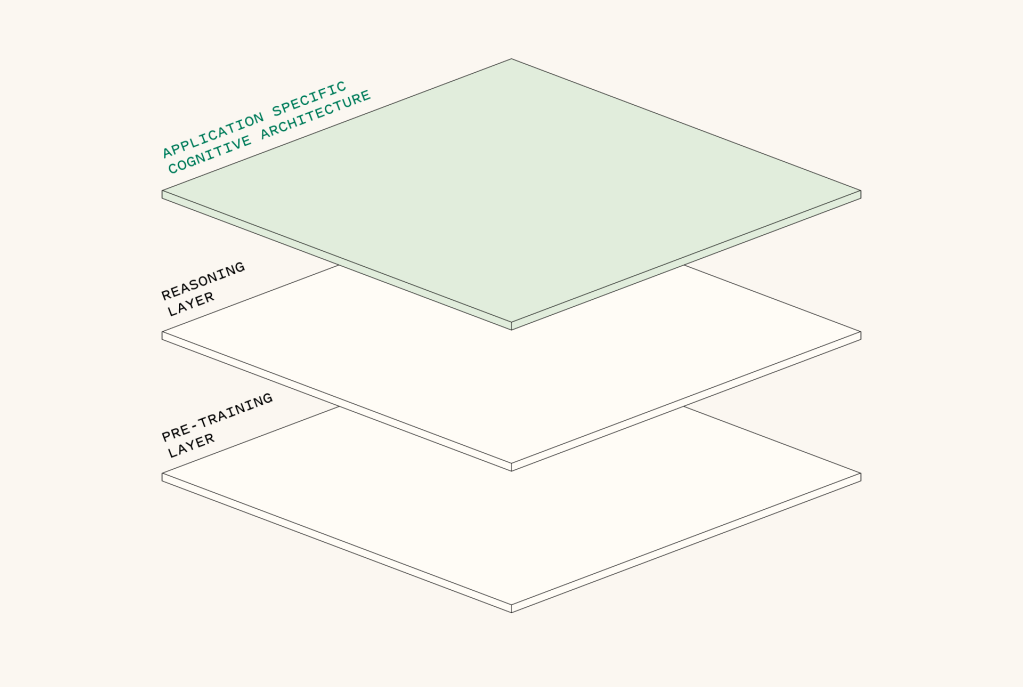
Enter cognitive architectures, or how your system thinks: the flow of code and model interactions that takes user input and performs actions or generates a response.
For example, in the case of Factory, each of their “droid” products has a custom cognitive architecture that mimics the way that a human thinks to solve a specific task, like reviewing pull requests or writing and executing a migration plan to update a service from one backend to another. The Factory droid will break down all of the dependencies, propose the relevant code changes, add unit tests and pull in a human to review. Then after approval, run the changes across all of the files in a dev environment and merge the code if all the tests pass. Just like how a human might do it—in a set of discrete tasks rather than one generalized, black box answer.
What’s Happening with Apps?
Imagine you want to start a business in AI. What layer of the stack do you target? Do you want to compete on infra? Good luck beating NVIDIA and the hyperscalers. Do you want to compete on the model? Good luck beating OpenAI and Mark Zuckerberg. Do you want to compete on apps? Good luck beating corporate IT and global systems integrators. Oh. Wait. That actually sounds pretty doable!
Foundation models are magic, but they’re also messy. Mainstream enterprises can’t deal with black boxes, hallucinations and clumsy workflows. Consumers stare at a blank prompt and don’t know what to ask. These are opportunities in the application layer.
Two years ago, many application layer companies were derided as “just a wrapper on top of GPT-3.” Today those wrappers turn out to be one of the only sound methods to build enduring value. What began as “wrappers” have evolved into “cognitive architectures.”
Application layer AI companies are not just UIs on top of a foundation model. Far from it. They have sophisticated cognitive architectures that typically include multiple foundation models with some sort of routing mechanism on top, vector and/or graph databases for RAG, guardrails to ensure compliance, and application logic that mimics the way a human might think about reasoning through a workflow.
Service-as-a-Software
The cloud transition was software-as-a-service. Software companies became cloud service providers. This was a $350B opportunity.
Thanks to agentic reasoning, the AI transition is service-as-a-software. Software companies turn labor into software. That means the addressable market is not the software market, but the services market measured in the trillions of dollars.
What does it mean to sell work? Sierra is a good example. B2C companies put Sierra on their website to talk with customers. The job-to-be-done is to resolve a customer issue. Sierra gets paid per resolution. There is no such thing as “a seat”. You have a job to be done. Sierra does it. They get paid accordingly.
This is the true north for many AI companies. Sierra benefits from having a graceful failure mode (escalation to a human agent). Not all companies are so lucky. An emerging pattern is to deploy as a copilot first (human-in-the-loop) and use those reps to earn the opportunity to deploy as an autopilot (no human in the loop). GitHub Copilot is a good example of this.
A New Cohort of Agentic Applications
With Generative AI’s budding reasoning capabilities, a new class of agentic applications is starting to emerge.
What shape do these application layer companies take? Interestingly, these companies look different than their cloud predecessors:
- Cloud companies targeted the software profit pool. AI companies target the services profit pool.
- Cloud companies sold software ($ / seat). AI companies sell work ($ / outcome)
- Cloud companies liked to go bottoms-up, with frictionless distribution. AI companies are increasingly going top-down, with high-touch, high-trust delivery models.
We are seeing a new cohort of these agentic applications emerge across all sectors of the knowledge economy. Here are some examples.
- Harvey: AI lawyer
- Glean: AI work assistant
- Factory: AI software engineer
- Abridge: AI medical scribe
- XBOW: AI pentester
- Sierra: AI customer support agent
By bringing the marginal cost of delivering these services down—in line with the plummeting cost of inference—these agentic applications are expanding and creating new markets.
Take XBOW, for example. XBOW is building an AI “pentester.” A “pentest” or penetration test is a simulated cyberattack on a computer system that companies perform in order to evaluate their own security systems. Before Generative AI, companies hired pentesters only in limited circumstances (e.g. when required for compliance), because human pentesting is expensive: it’s a manual task performed by a highly skilled human. However, XBOW is now demonstrating automated pentests built on the latest reasoning LLMs that match the performance of the most highly skilled human pentesters. This multiplies the pentesting market and opens up the possibility of continuous pentesting for companies of all shapes and sizes.
What does this mean for the SaaS universe?
Earlier this year we met with our Limited Partners. Their top question was “will the AI transition destroy your existing cloud companies?”
We began with a strong default of “no.” The classic battle between startups and incumbents is a horse race between startups building distribution and incumbents building product. Can the young companies with cool products get to a bunch of customers before the incumbents who own the customers come up with cool products? Given that so much of the magic in AI is coming from the foundation models, our default assumption has been no—the incumbents will do just fine, because those foundation models are just as accessible to them as they are to the startup universe, and they have the preexisting advantages of data and distribution. The primary opportunity for startups is not to replace incumbent software companies—it’s to go after automatable pools of work.
That being said, we are no longer so sure. See above re: cognitive architectures. There’s an enormous amount of engineering required to turn the raw capabilities of a model into a compelling, reliable, end-to-end business solution. What if we’re just dramatically underestimating what it means to be “AI native”?
Twenty years ago the on-prem software companies scoffed at the idea of SaaS. “What’s the big deal? We can run our own servers and deliver this stuff over the internet too!” Sure, conceptually it was simple. But what followed was a wholesale reinvention of the business. EPD went from waterfalls and PRDs to agile development and AB testing. GTM went from top-down enterprise sales and steak dinners to bottoms-up PLG and product analytics. Business models went from high ASPs and maintenance streams to high NDRs and usage-based pricing. Very few on-prem companies made the transition.
What if AI is an analogous shift? Could the opportunity for AI be both selling work and replacing software?
With Day.ai, we have seen a glimpse of the future. Day is an AI native CRM. Systems integrators make billions of dollars configuring Salesforce to meet your needs. With nothing but access to your email and calendar and answers to a one-page questionnaire, Day automatically generates a CRM that is perfectly tailored to your business. It doesn’t have all the bells and whistles (yet), but the magic of an auto-generated CRM that remains fresh with zero human input is already causing people to switch.
The Investment Universe
Where are we spending our cycles as investors? Where is funding being deployed? Here’s our quick take.
Infrastructure
This is the domain of hyperscalers. It’s being driven by game theoretic behavior, not microeconomics. Terrible place for venture capitalists to be.
Models
This is the domain of hyperscalers and financial investors. Hyperscalers are trading balance sheets for income statements, investing money that’s just going to round-trip back to their cloud businesses in the form of compute revenue. Financial investors are skewed by the “wowed by science” bias. These models are super cool and these teams are incredibly impressive. Microeconomics be damned!
Developer tools and infrastructure software
Less interesting for strategics and more interesting for venture capitalists. ~15 companies with $1Bn+ of revenue were created at this layer during the cloud transition, and we suspect the same could be true with AI.
Apps
The most interesting layer for venture capital. ~20 application layer companies with $1Bn+ in revenue were created during the cloud transition, another ~20 were created during the mobile transition, and we suspect the same will be true here.

Closing Thoughts
In Generative AI’s next act, we expect to see the impact of reasoning R&D ripple into the application layer. These ripples are fast and deep. Most of the cognitive architectures to date incorporate clever “unhobbling” techniques; now that these capabilities are becoming baked deeper into the models themselves, we expect that agentic applications will become much more sophisticated and robust, quickly.
Back in the research lab, reasoning and inference-time compute will continue to be a strong theme for the foreseeable future. Now that we have a new scaling law, the next race is on. But for any given domain, it is still hard to gather real-world data and encode domain and application-specific cognitive architectures. This is again where last-mile app providers may have the upper hand in solving the diverse set of problems in the messy real world.
Thinking ahead, multi-agent systems, like Factory’s droids, may begin to proliferate as ways of modeling reasoning and social learning processes. Once we can do work, we can have teams of workers accomplishing so much more.
What we’re all eagerly awaiting is Generative AI’s Move 37, that moment when – like in AlphaGo’s second game against Lee Sedol – a general AI system surprises us with something superhuman, something that feels like independent thought. This does not mean that the AI “wakes up” (AlphaGo did not) but that we have simulated processes of perception, reasoning and action that the AI can explore in truly novel and useful ways. This may in fact be AGI, and if so it will not be a singular occurrence, it will merely be the next phase of technology.

