Accelerate 1.0.0 加速 1.0.0
发布于 2024 年 9 月 13 日








What is Accelerate today?
今天 Accelerate 是什么?
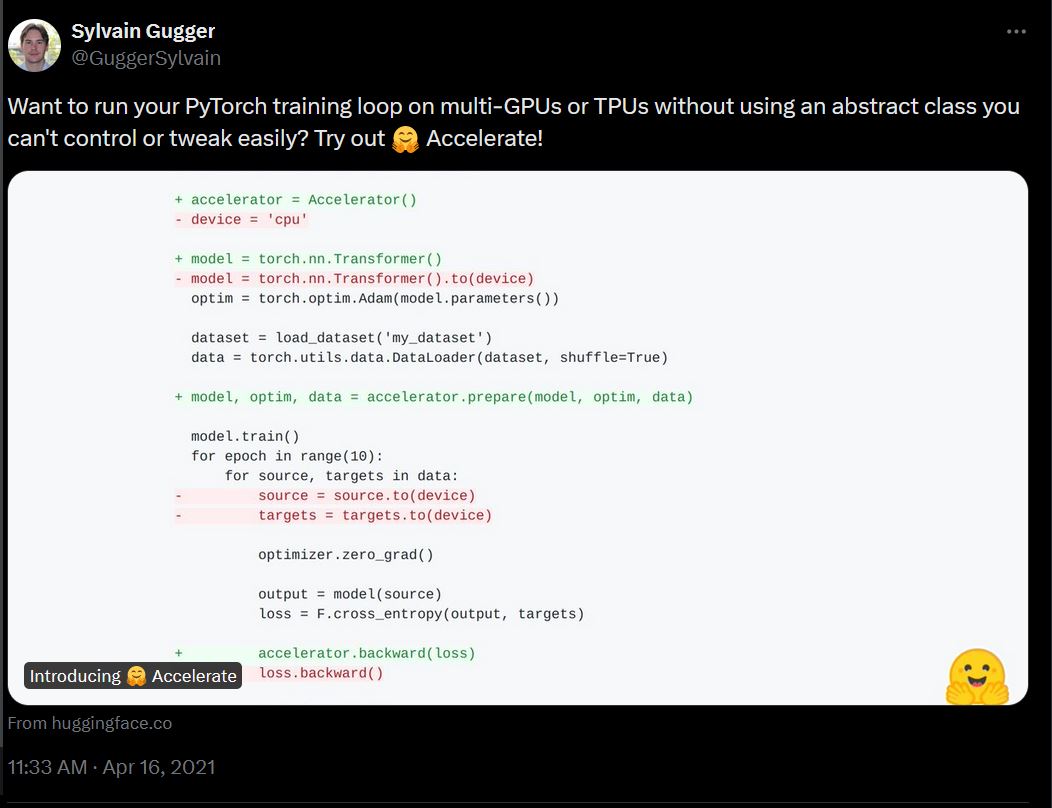
3.5 years ago, Accelerate was a simple framework aimed at making training on multi-GPU and TPU systems easier
by having a low-level abstraction that simplified a raw PyTorch training loop:
3.5 年前,Accelerate 是一个简单的框架,旨在通过提供一个低级抽象来简化在多 GPU 和 TPU 系统上的训练,从而使原始的 PyTorch 训练循环更简单:
Since then, Accelerate has expanded into a multi-faceted library aimed at tackling many common problems with
large-scale training and large models in an age where 405 billion parameters (Llama) are the new language model size. This involves:
从那时起,Accelerate 已经扩展为一个多方面的库,旨在解决大规模训练和大模型时代的许多常见问题,在这个时代,4050 亿参数(Llama)已成为新的语言模型规模。这包括:
- A flexible low-level training API, allowing for training on six different hardware accelerators (CPU, GPU, TPU, XPU, NPU, MLU) while maintaining 99% of your original training loop
一个灵活的低级训练 API,允许在六种不同的硬件加速器(CPU、GPU、TPU、XPU、NPU、MLU)上进行训练,同时保持 99%的原始训练循环 - An easy-to-use command-line interface aimed at configuring and running scripts across different hardware configurations
一个易于使用的命令行界面,旨在配置和在不同的硬件配置上运行脚本 - The birthplace of Big Model Inference or
device_map="auto", allowing users to not only perform inference on LLMs with multi-devices but now also aiding in training LLMs on small compute through techniques like parameter-efficient fine-tuning (PEFT)
大模型推理的诞生地,或device_map="auto",使用户不仅能够在多设备上进行LLMs推理,现在还通过参数高效微调(PEFT)等技术帮助在小计算上训练LLMs
These three facets have allowed Accelerate to become the foundation of nearly every package at Hugging Face, including transformers, diffusers, peft, trl, and more!
这三个方面使 Accelerate 成为 Hugging Face 几乎所有包的基础,包括 transformers , diffusers , peft , trl 等!
As the package has been stable for nearly a year, we're excited to announce that, as of today, we've published the first release candidates for Accelerate 1.0.0!
由于该包已经稳定了近一年,我们很高兴地宣布,从今天起,我们发布了 Accelerate 1.0.0 的第一个候选版本!
This blog will detail:
这篇博客将详细介绍:
- Why did we decide to do 1.0?
我们为什么决定做 1.0? - What is the future for Accelerate, and where do we see PyTorch as a whole going?
Accelerate 的未来是什么,我们如何看待整个 PyTorch 的发展方向? - What are the breaking changes and deprecations that occurred, and how can you migrate over easily?
发生了哪些重大变化和弃用,如何轻松迁移?
Why 1.0? 为什么是 1.0?
The plans to release 1.0.0 have been in the works for over a year. The API has been roughly at a point where we wanted,
centering on the Accelerator side, simplifying much of the configuration and making it more extensible. However, we knew
there were a few missing pieces before we could call the "base" of Accelerate "feature complete":
发布 1.0.0 的计划已经进行了超过一年。API 已经大致达到了我们想要的水平,主要集中在 Accelerator 方面,简化了大部分配置并使其更具扩展性。然而,我们知道在宣布 Accelerate 的“基础”“功能完整”之前,还有一些缺失的部分:
- Integrating FP8 support of both MS-AMP and
TransformersEngine(read more here and here)
集成对 MS-AMP 和TransformersEngine的 FP8 支持(更多信息请参阅此处和此处) - Supporting orchestration of multiple models when using DeepSpeed (Experimental)
在使用 DeepSpeed 时支持多个模型的编排(实验性) torch.compilesupport for the big model inference API (requirestorch>=2.5)
支持大模型推理 API(需要torch>=2.5)- Integrating
torch.distributed.pipeliningas an alternative distributed inference mechanic
将torch.distributed.pipelining集成作为替代的分布式推理机制 - Integrating
torchdata.StatefulDataLoaderas an alternative dataloader mechanic
将torchdata.StatefulDataLoader集成作为替代的数据加载机制
With the changes made for 1.0, accelerate is prepared to tackle new tech integrations while keeping the user-facing API stable.
随着 1.0 版本的改动,accelerate 已准备好应对新的技术集成,同时保持用户界面 API 的稳定性。
The future of Accelerate
加速的未来
Now that 1.0 is almost done, we can focus on new techniques coming out throughout the community and find integration paths into Accelerate, as we foresee some radical changes in the PyTorch ecosystem very soon:
现在 1.0 版本即将完成,我们可以专注于社区中出现的新技术,并找到将其集成到加速中的路径,因为我们预见到 PyTorch 生态系统很快会发生一些根本性的变化:
- As part of the multiple-model DeepSpeed support, we found that while generally how DeepSpeed is currently could work, some heavy changes to the overall API may eventually be needed as we work to support simple wrappings to prepare models for any multiple-model training scenario.
作为多模型 DeepSpeed 支持的一部分,我们发现虽然目前 DeepSpeed 的工作方式总体上可以,但随着我们努力支持简单的包装以准备任何多模型训练场景,可能最终需要对整体 API 进行一些重大更改。 - With torchao and torchtitan picking up steam, they hint at the future of PyTorch as a whole. Aiming at more native support for FP8 training, a new distributed sharding API, and support for a new version of FSDP, FSDPv2, we predict that much of the internals and general usage API of Accelerate will need to change (hopefully not too drastic) to meet these needs as the frameworks slowly become more stable.
随着 torchao 和 torchtitan 的势头增强,它们暗示了 PyTorch 作为一个整体的未来。旨在为 FP8 训练提供更多原生支持,一个新的分布式分片 API,以及对新版本 FSDP(FSDPv2)的支持,我们预测加速的内部和一般使用 API 将需要进行一些更改(希望不会太剧烈)以满足这些需求,因为这些框架逐渐变得更加稳定。 - Riding on
torchao/FP8, many new frameworks are bringing in different ideas and implementations on how to make FP8 training work and be stable (transformer_engine,torchao,MS-AMP,nanotron, to name a few). Our aim with Accelerate is to house each of these implementations in one place with easy configurations to let users explore and test out each one as they please, intending to find the ones that wind up being the most stable and flexible. It's a rapidly accelerating (no pun intended) field of research, especially with NVIDIA's FP4 training support on the way, and we want to make sure that not only can we support each of these methods but aim to provide solid benchmarks for each to show their tendencies out-of-the-box (with minimal tweaking) compared to native BF16 training
在torchao/FP8 的基础上,许多新框架正在引入不同的想法和实现,以使 FP8 训练工作并保持稳定(transformer_engine,torchao,MS-AMP,nanotron,仅举几例)。我们的目标是通过 Accelerate 将这些实现集中在一个地方,并提供简单的配置,让用户可以根据自己的喜好探索和测试每一个实现,旨在找到最稳定和灵活的实现。这是一个快速发展的研究领域,尤其是随着 NVIDIA 的 FP4 训练支持即将到来,我们希望确保不仅能够支持每种方法,而且旨在为每种方法提供坚实的基准,以展示它们在开箱即用(只需少量调整)的情况下与原生 BF16 训练相比的倾向性。
We're incredibly excited about the future of distributed training in the PyTorch ecosystem, and we want to make sure that Accelerate is there every step of the way, providing a lower barrier to entry for these new techniques. By doing so, we hope the community will continue experimenting and learning together as we find the best methods for training and scaling larger models on more complex computing systems.
我们对 PyTorch 生态系统中分布式训练的未来感到非常兴奋,我们希望确保 Accelerate 在每一步都能提供支持,为这些新技术提供更低的进入门槛。通过这样做,我们希望社区将继续一起实验和学习,因为我们找到了在更复杂的计算系统上训练和扩展更大模型的最佳方法。
How to try it out
如何尝试
To try the first release candidate for Accelerate today, please use one of the following methods:
要尝试今天的加速器第一个候选版本,请使用以下方法之一:
- pip:
pip install --pre accelerate
- Docker:
docker pull huggingface/accelerate:gpu-release-1.0.0rc1
Valid release tags are:
有效的发布标签是:
gpu-release-1.0.0rc1cpu-release-1.0.0rc1gpu-fp8-transformerengine-release-1.0.0rc1gpu-deepspeed-release-1.0.0rc1
Migration assistance 迁移协助
Below are the full details for all deprecations that are being enacted as part of this release:
以下是此版本中正在实施的所有弃用的完整详细信息:
- Passing in
dispatch_batches,split_batches,even_batches, anduse_seedable_samplerto theAccelerator()should now be handled by creating anaccelerate.utils.DataLoaderConfiguration()and passing this to theAccelerator()instead (Accelerator(dataloader_config=DataLoaderConfiguration(...)))
传递dispatch_batches、split_batches、even_batches和use_seedable_sampler到Accelerator()现在应该通过创建一个accelerate.utils.DataLoaderConfiguration()并将其传递给Accelerator()来处理(Accelerator(dataloader_config=DataLoaderConfiguration(...))) Accelerator().use_fp16andAcceleratorState().use_fp16have been removed; this should be replaced by checkingaccelerator.mixed_precision == "fp16"
Accelerator().use_fp16和AcceleratorState().use_fp16已被移除;这应该替换为检查accelerator.mixed_precision == "fp16"Accelerator().autocast()no longer accepts acache_enabledargument. Instead, anAutocastKwargs()instance should be used which handles this flag (among others) passing it to theAccelerator(Accelerator(kwargs_handlers=[AutocastKwargs(cache_enabled=True)]))
Accelerator().autocast()不再接受cache_enabled参数。取而代之,应使用AutocastKwargs()实例,该实例处理此标志(及其他标志)并将其传递给Accelerator(Accelerator(kwargs_handlers=[AutocastKwargs(cache_enabled=True)]))。accelerate.utils.is_tpu_availableshould be replaced withaccelerate.utils.is_torch_xla_available
accelerate.utils.is_tpu_available应该替换为accelerate.utils.is_torch_xla_availableaccelerate.utils.modeling.shard_checkpointshould be replaced withsplit_torch_state_dict_into_shardsfrom thehuggingface_hublibrary
accelerate.utils.modeling.shard_checkpoint应该替换为split_torch_state_dict_into_shards来自huggingface_hub库accelerate.tqdm.tqdm()no longer acceptsTrue/Falseas the first argument, and instead,main_process_onlyshould be passed in as a named argument
accelerate.tqdm.tqdm()不再接受True/False作为第一个参数,而应改为传递main_process_only作为命名参数ACCELERATE_DISABLE_RICHis no longer a valid environmental variable, and instead, one should manually enablerichtraceback by settingACCELERATE_ENABLE_RICH=1- The FSDP setting
fsdp_backward_prefetch_policyhas been replaced withfsdp_backward_prefetch
Closing thoughts
Thank you so much for using Accelerate; it's been amazing watching a small idea turn into over 100 million downloads and nearly 300,000 daily downloads over the last few years.
With this release candidate, we hope to give the community an opportunity to try it out and migrate to 1.0 before the official release.
Please stay tuned for more information by keeping an eye on the github and on socials!
请继续关注我们的 GitHub 和社交媒体,以获取更多信息!







