It's hard to write code for computers, but it's even harder to write code for humans
写给计算机的代码很难写,但写给人看的代码更难写
Length: • 8 mins
• 8 分钟
Annotated by howie.serious
由 howie.serious 注释
Writing code for a computer is hard enough. You take something big and fuzzy, some large vague business outcome you want to achive. Then you break it down recursively and think about all the cases until you have clear logical statements a computer can follow. Computers are very good at following logical statements.
为计算机编写代码已经够难的了。你需要将一个模糊的大目标,即你想要实现的某个大型模糊的业务结果,进行分解。然后你递归地分解它,考虑所有的情况,直到你有了计算机可以遵循的清晰逻辑语句。计算机非常擅长遵循逻辑语句。
Now, let's crank it up a notch. Let's try to write code for humans!
现在,让我们提升一个档次。让我们尝试为人类编写代码!
I need to clarify what I mean. I'm talking about code that other humans will interact with. More specifically, I'm talking about the art of crafting joyful frameworks, libraries, APIs, SDKs, DSLs, embedded DSLs, or maybe even programming languages.
我需要澄清我的意思。我说的是其他人类会与之互动的代码。更具体地说,我说的是打造令人愉悦的框架、库、API、SDK、DSL、嵌入式 DSL,甚至可能是编程语言的艺术。
Writing this code is much harder, because you're not just telling a computer what to do, you're also grappling with another user's mental model of your code. Now it's equal part computer science and psychology of reasoning, or something. How do you get that person to understand your code?
编写这种代码要困难得多,因为你不仅仅是在告诉计算机该做什么,你还在处理另一个用户对你的代码的心理模型。现在这既是计算机科学的一部分,也是推理心理学的一部分,或者类似的东西。你如何让那个人理解你的代码?
Feynman famously said: Imagine how much harder physics would be if electrons had feelings. about something very different, but in a funny way I think this describes programming for humans a bit. The person interpreting your code actually has feelings!
费曼曾经著名地说过:想象一下,如果电子有感情,物理学会变得多么困难。 这是关于完全不同的事情,但有趣的是,我认为这有点描述了为人类编程。解释你代码的人实际上是有感情的!
Let's talk about some ways we can make it easier.
让我们谈谈一些可以让它变得更容易的方法。
Getting started is the product
开始是产品
It's obviously great to listen to your users and take their feedback into account. As it turns out, most of that feedback will come from power users who use your product all the time!
显然,听取用户的意见并考虑他们的反馈是很棒的。事实证明,大部分反馈将来自那些一直使用你产品的高级用户!
How does that affect the distribution of the feedback you're getting? Will it be skewed? And what does this picture of an airplane have to do with it?
这如何影响你收到的反馈分布?它会偏向某一方面吗?这张飞机的图片与此有何关系?
Of course, there's a survivorship bias going on here. There are users who don't use your tool because they never get started. You will typically never hear their feedback!
当然,这里存在一个幸存者偏差。有些用户从未开始使用你的工具,因此你通常不会听到他们的反馈!
Consumer products have had growth hackers for many years optimizing every part of the onboarding funnel. Dev tools should do the same. Getting started shouldn't be an afterthought after you built the product. Getting started is the product!
多年来,消费品一直有增长黑客在优化每个部分的引导漏斗。开发工具也应该这样做。开始不应该是在你构建产品之后的事后考虑。开始是产品!
And I mean this to the point where I think it's worth restructuring your entire product to enable fast onboarding. Get rid of mandatory config. Make it absurdly easy to set up API tokens. Remove all the friction. Make it possible for users to use your product on their laptop in a couple of minutes, tops.
我的意思是,我认为值得重构整个产品以实现快速上手。去掉强制配置。让设置 API 令牌变得极其容易。消除所有摩擦。让用户可以在几分钟内在他们的笔记本电脑上使用你的产品。
You might dismiss this as, I don't know, “who cares about lazy users”. Then let me lean back on my bean bag chair, open a bag of Doritos, and explain something:
你可能会对此不屑一顾,我不知道,“谁在乎懒惰的用户”。那么让我靠在豆袋椅上,打开一包多力多滋,解释一下:
There's currently 7,000,000,000 dev tools out there. Users don't have a ton of energy or patience to go deep and try to understand what's different about your LRU cache NPM package or whatever. Sorry!
目前有 7,000,000,000 个开发工具。用户没有太多精力或耐心去深入了解你的 LRU 缓存 NPM 包或其他东西的不同之处。抱歉!
Humans learn from examples, not from “core concepts”
人类从例子中学习,而不是从“核心概念”中学习
Humans are amazing pattern matching machines, in contrast to computers who obey Boolean logic and follow strict instructions. It's common to see documentation for dev tools structured like a computer program. It starts with defines a core data model and the relations and the atoms. It starts with “core concepts” and how to configure and how to run things.
人类是惊人的模式匹配机器,而计算机则遵循布尔逻辑和严格的指令。常见的情况是,开发工具的文档结构像一个计算机程序。它从定义核心数据模型及其关系和原子开始。它从“核心概念”以及如何配置和运行开始。
Humans don't learn about things this way.
人类不是通过这种方式学习事物的。
Two seconds after writing the above paragraph, I ran into this on Twitter which basically captures what I'm trying to say:
写完上面的段落两秒钟后,我在推特上遇到了这段话,基本上捕捉到了我想说的内容:

Too many programming books and tutorials are like “let’s build a house starting from scratch, brick by brick” when what I want to “here is a functioning house, let’s learn about it by changing something and then seeing what happens”
太多的编程书籍和教程都是“让我们从头开始,一砖一瓦地建造一座房子”,而我想要的是“这里有一座功能齐全的房子,让我们通过改变某些东西然后看看会发生什么来了解它”
Instead of writing an 5,000 word “core concepts” chronicle, may I suggest putting together a dozen examples instead. This has a few benefits:
与其写一篇 5000 字的“核心概念”编年史,不如我建议准备十几个例子。这有几个好处:
- Humans will look at the examples and learn how your tool works from that. This is how humans learn!
人类会查看示例并从中学习如何使用您的工具。这就是人类学习的方式! - A person with a problem in mind will look for a starting point that's close enough. The more potential starting points, the more likely they are to have something that's closer to what they need.
有问题的人会寻找一个足够接近的起点。潜在的起点越多,他们就越有可能找到更接近他们需要的东西。
Falling into the pit of success
掉进成功的陷阱
The sad but true part of programming is, the default mode is that you're fixing an error of some sort. This means that users are going to spend the majority of the time with your tool trying to figure out what's not working. Which is why pushing them back into success is so core.
编程中一个悲哀但真实的部分是,默认模式是你在修复某种错误。这意味着用户将花费大部分时间使用您的工具来弄清楚什么地方出了问题。这就是为什么将他们推回成功如此重要。
A succinct list: 一个简洁的列表:
- Developers getting to success faster are happy developers. They will like your tool.
开发人员更快地取得成功是快乐的开发人员。他们会喜欢你的工具。 - Developers banging their heads against errors are sad developers. They will blame your tool.
开发人员因错误而头疼是悲伤的开发人员。他们会责怪你的工具。
Think about every error as an opportunity to nudge a user towards the happy path. Put code snippets in the exceptions. Emit helpful warnings when users are likely to do something weird. Do what you got to do to make the user succeed.
将每个错误视为引导用户走向快乐路径的机会。在异常中放置代码片段。当用户可能做一些奇怪的事情时,发出有用的警告。做你必须做的事情来让用户成功。
Avoid conceptual overload
避免概念过载
Every new conceptual thing you have to understand before using the tool makes is a new friction point. If it's 2-3 things, that's fine. But no one is going to bother learning 8 new concepts.
在使用工具之前你必须理解的每一个新的概念事物都是一个新的摩擦点。如果是 2-3 个事物,那还好。但没有人会费心去学习 8 个新概念。
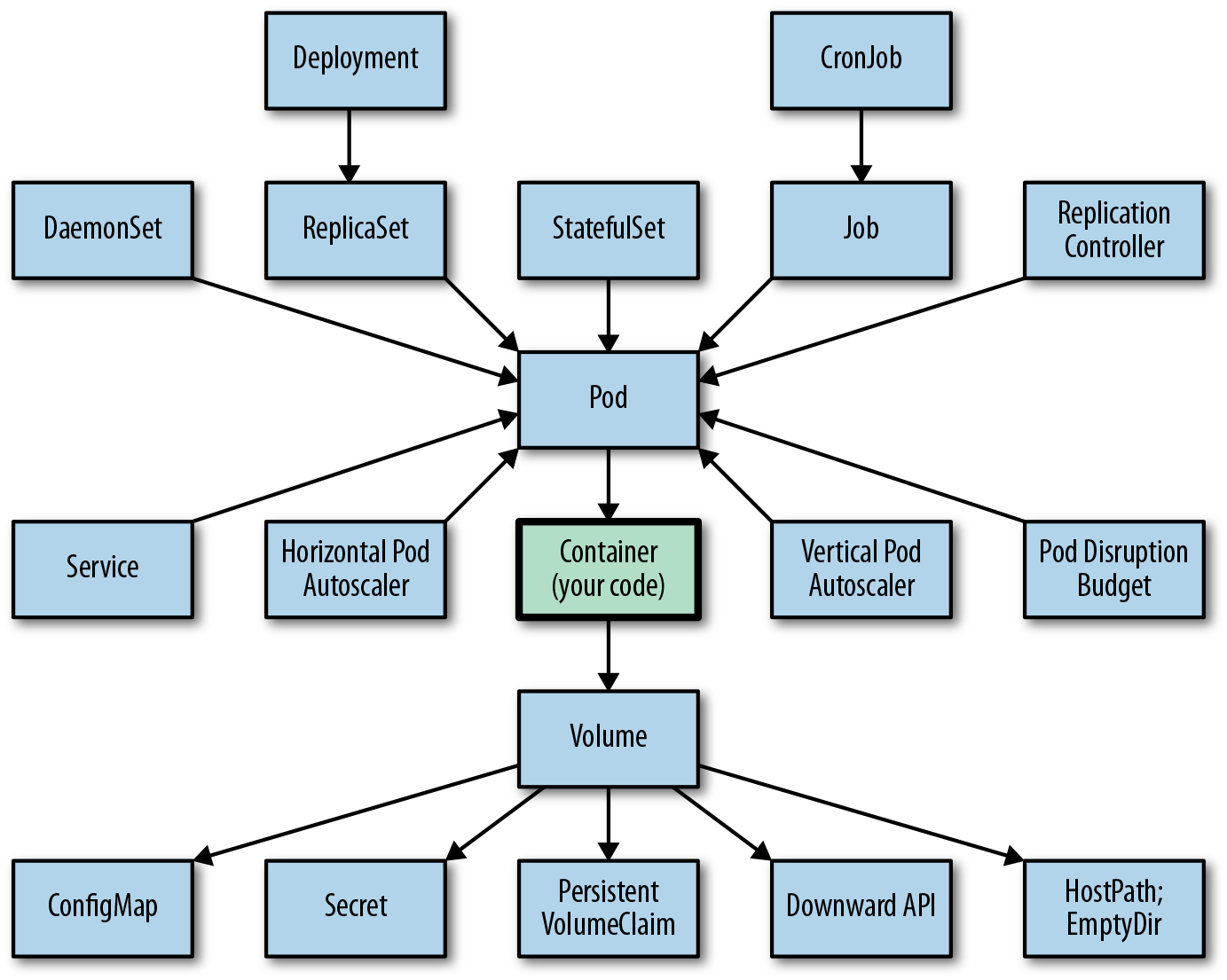
This example (Kubernetes) isn't even particularly egregious. You can get started just knowing a few of these. I mean you can find worse ones out there
这个例子(Kubernetes)并不是特别严重。你只需要知道其中的一些就可以开始。我是说,你可以找到更糟糕的例子。
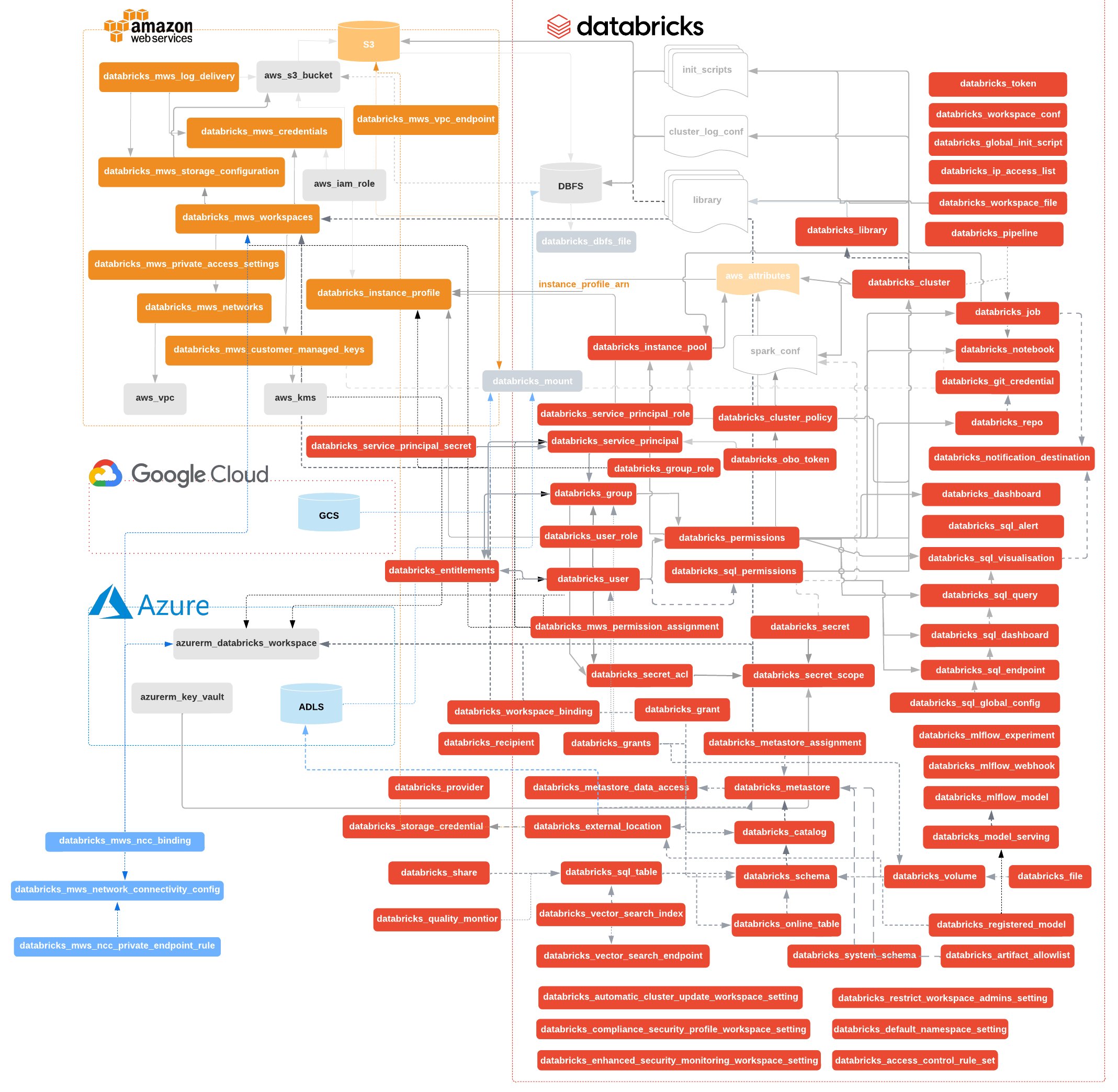
It's probably true you don't need the vast majority to get started. But still, my head hurts when I have to learn new things. Too many things!
可能确实如此,你不需要大多数东西就可以开始。但即便如此,当我必须学习新的东西时,我的头还是会痛。太多东西了!
There's something elegant about a framework with just 3-5 things that manages to be incredibly powerful. I remember the feeling when I tried React the first time and got over the conceptual hump after an hour or two. Just a few fairly simple building blocks that lets you build a whole cathedral. Magic stuff ✨.
有一个框架只有 3-5 个东西,却能变得非常强大,这其中有一种优雅。我记得第一次尝试 React 时,在一两个小时后克服了概念上的障碍的感觉。只是一些相当简单的构建块,却能让你建造整个大教堂。神奇的东西✨。
To be clear, the challenge isn't to reduce concepts. It's to retain the possible set of things you can build while reducing concepts. Or at least reducing the former less than the latter. I'm mentioning this because I picture some sort of a “dumb dev tools simplification doom loop” that goes something like this:
要明确的是,挑战不是减少概念。而是在减少概念的同时保留你能构建的可能集合。或者至少前者减少得比后者少。我提到这一点是因为我想象某种“愚蠢的开发工具简化末日循环”,大致是这样的:
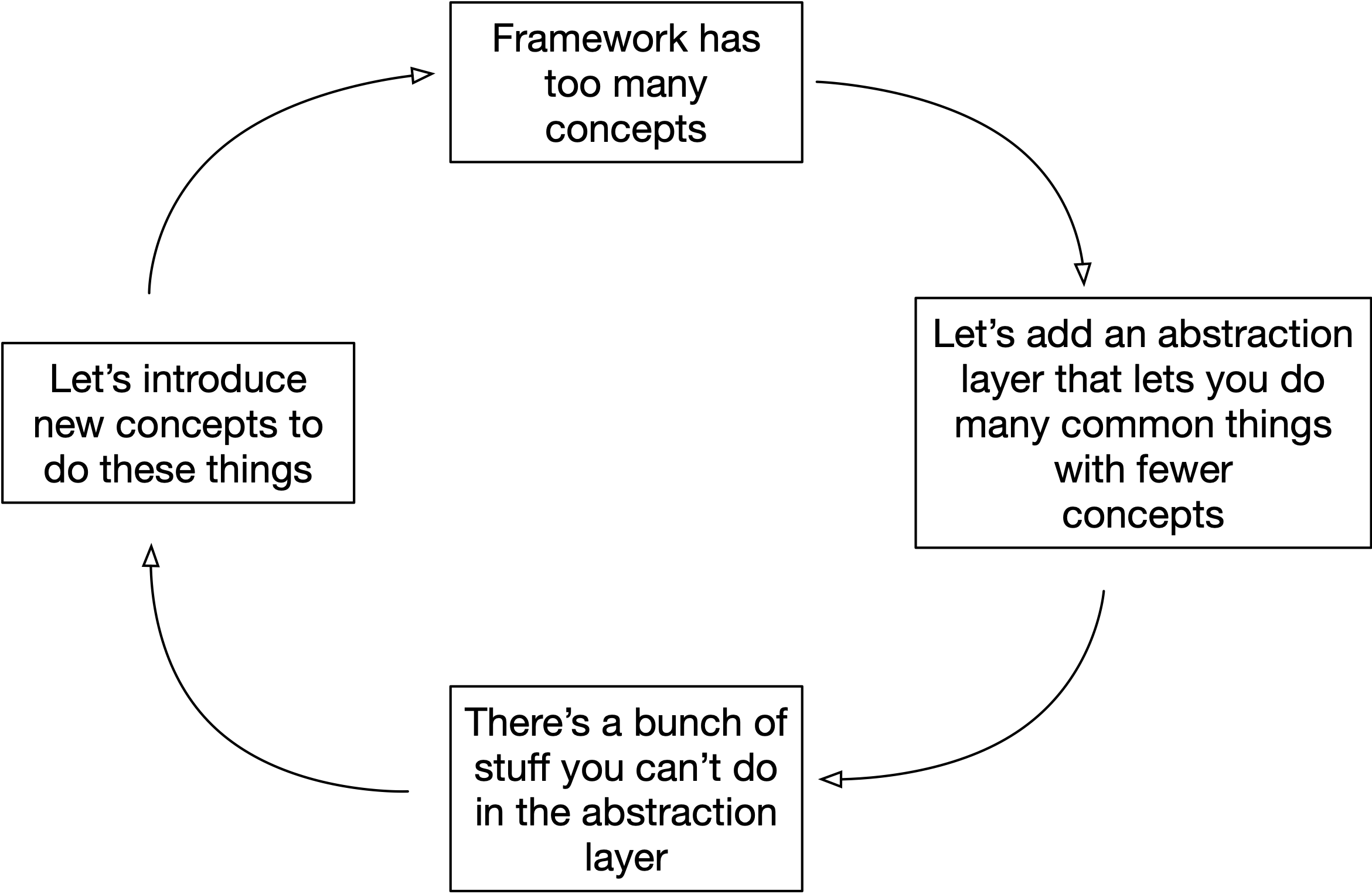
I don't know if this is a thing, but my point here is that there's a level of futility of “bad” simplification. You ultimately want to push the frontier describing the tradeoff between “complexity” (what you need to know) and “ability” (what you can build). Amazing tools are able to reduce complexity by 90% while keeping the ability the same, But I'll also take a tool that reduces the former by 90% and reduces the latter by 10%. That's still not bad!
我不知道这是否是一回事,但我这里的观点是,“糟糕”的简化有一定程度的徒劳。你最终想要推动描述“复杂性”(你需要知道的东西)和“能力”(你能构建的东西)之间权衡的前沿。惊人的工具能够在保持能力不变的情况下将复杂性减少 90%,但我也会接受一个将前者减少 90%而后者减少 10%的工具。那也不错!
Conceptual duck principle
概念鸭子原则
Somewhat related to the previous point, let's say in your framework you introduce a thing that takes some values and evalutes to a new values. What do you call it? A compute node? A valuator? A frobniscator?
有点相关的前一点,假设在你的框架中引入了一个接受一些值并计算出新值的东西。你怎么称呼它?计算节点?估值器?frobniscator?
No! You call it a function!
不!你称它为函数!

If it walks like a duck, and it quacks like a duck, it probably is a duck.
如果它走路像鸭子,叫声像鸭子,它可能就是一只鸭子。
Maybe it isn't exactly like a function in some subtle ways. Maybe the values are cached for instance. But that's close enough!
也许它在某些细微的方面并不完全像函数。比如,值可能被缓存。但这已经足够接近了!
Calling it a function means you latch onto a users pre-existing mental model of what a function does. Which will save you like, 90% of the explanation of how to think about this object.
把它称为函数意味着你会依赖用户对函数的预先存在的心理模型。这将节省你大约 90%的解释如何思考这个对象的时间。
Programmability 可编程性
People will do crazy things with your codebase. They will take your things and put it inside a for-loop inside a function inside something else. People are creative!
人们会用你的代码库做疯狂的事情。他们会把你的东西放在一个 for 循环里面,再放在一个函数里面,再放在其他东西里面。人们很有创造力!
You want almost everything in your framework to be “programmable” for this reason.
出于这个原因,你希望框架中的几乎所有东西都是“可编程的”。
This is a whole class of issues that are related in subtle ways and can be solved in similar ways. Let users call things directly in code rather than going through a CLI. Avoid config and turn it into an SDK or an API. Make things easily to parametrize so you can create n things not just 1.
这是一个与微妙方式相关的问题类别,可以用类似的方式解决。让用户直接在代码中调用东西,而不是通过 CLI。避免配置并将其转化为 SDK 或 API。使事物易于参数化,这样你可以创建n个东西,而不仅仅是 1 个。
One weird benefit of this is it often lets users discover new use cases for you. Harness people's desire to “hack” on top of your framework. There will be some mild bloodshed coming from those users, but don't chastise them! They might be on the verge of discovering something unexpected.
这种奇怪的好处之一是,它经常让用户发现你的新用例。利用人们想要在你的框架上“黑客”的欲望。那些用户会有一些轻微的流血事件,但不要责备他们!他们可能正处于发现意想不到的东西的边缘。
Be extra judicious about magic, defaults, and syntactic sugar
对魔法、默认值和语法糖要格外谨慎
Let's say you're building a tool that executes a Jupyter notebook in the cloud. So you have a function run_notebook that takes a list of cells (with computer code) or something.
假设你正在构建一个在云中执行 Jupyter 笔记本的工具。所以你有一个函数run_notebook,它接受一个包含计算机代码的单元格列表或其他东西。
How does the user specify which container image they should use? You have a few different options:
用户如何指定他们应该使用哪个容器镜像?你有几种不同的选择:
- An argument
image=...that always has to be provided.
一个参数image=...,它总是必须提供。 - An argument
image=...that defaults to some base image with “most” data science libraries pre-installed, but that they user can override.
一个参数image=...,默认使用预装了“多数”数据科学库的基础镜像,但用户可以覆盖它。 - You inspect the code in the cells and pick an image in a “magic” way based on what dependencies are needed.
你检查单元格中的代码,并以“神奇”的方式根据所需的依赖项选择一个镜像。 - Same as above, but you also let users optionally specify a specific image.
与上面相同,但你也允许用户可选地指定一个特定的镜像。
What should you use? If you want to minimize the amount of typing for users, while supporting the widest possible set of use cases, go for the last option. But here are some issues with all options except the first one:
你应该使用什么?如果你想最小化用户的输入量,同时支持尽可能广泛的用例,请选择最后一个选项。但除了第一个选项外,所有选项都有一些问题:
- Let's be real — the magic will break in some % of situations.
让我们现实一点——这种“神奇”的方法在某些情况下会失效。 - Users reading code that relies on defaults will not realize that things are customizeable.
阅读依赖于默认值的代码的用户不会意识到这些东西是可以定制的。
Unless defaults apply in 97%+ of the time, and unless magic applies 99% of the time, be careful about introducing it. These are not exact numbers obviously, but my point is, you need to be very very judicious.
除非默认值在 97%以上的情况下适用,并且除非魔法在 99%的情况下适用,否则要小心引入它们。这些显然不是精确的数字,但我的意思是,你需要非常非常谨慎。
It's tempting to think that job as a tool provider is to minimize the amount of code a user has to write. But coding isn't golf!
认为作为工具提供者的工作是最小化用户必须编写的代码量是很诱人的。但编程不是高尔夫!
I think about this a bit about how I think about Perl vs Python. Perl tried very hard to optimize for shortest code until every program looked like a strong of special characters and nothing else. Then Python came and it's code was 50% longer. It never tried to be the shortest! But it turned out Python code was super readable and thus much more understandable. And people read code 10x more times than they write it.
我对 Perl 和 Python 的看法有点类似。Perl 非常努力地优化代码的最短长度,直到每个程序看起来像一串特殊字符,别无其他。然后 Python 出现了,它的代码长了 50%。它从未试图成为最短的!但事实证明,Python 代码非常可读,因此更容易理解。而且人们阅读代码的次数是编写代码的 10 倍。
Syntactic sugar belongs in a similar category. It's tempting to introduce a special syntax for the most common use cases. But it often obscures the consistency and makes it less clear how to customize code. For similar reasons, unless the syntactic sugar applies 99%+ of the time, it's probably not a good idea to introduce it.
语法糖属于类似的类别。引入一种特殊语法来处理最常见的用例是很诱人的。但它往往会掩盖一致性,使得如何定制代码变得不那么清晰。出于类似的原因,除非语法糖在 99%以上的情况下适用,否则引入它可能不是一个好主意。
Writing code for humans is hard
为人类编写代码很难
We are coming to an end, but there are so many more things I could keep going on about:
我们即将结束,但还有很多事情我可以继续谈论:
- Most things (but not everything) should be immutable
大多数事情(但不是所有事情)都应该是不可变的 - Avoid “scaffolding” (code generation)
避免“脚手架”(代码生成) - Make the feedback loops incredibly fast
使反馈循环极快 - Make deprecations easy for users to deal with
让用户轻松处理弃用功能 - Use automated testing for code snippets in docs and examples
使用自动化测试来测试文档和示例中的代码片段
Probably a lot more. Those are maybe things for a future blog post! Including what I think is maybe the most fascinating thing: why large companies are generally incapable of delivering great developer experiences.
可能还有更多。这些可能是未来博客文章的内容!包括我认为也许是最有趣的事情:为什么大公司通常无法提供出色的开发者体验。
I sometimes think the challenge of designing for the 1st time user is similar to making a pop song. The producer will listen to the song a thousand times. But still the 999th time they hear it, they need to imagine what it sounds like to a person that hears it the first time, which seems… super hard.
我有时认为为第一次用户设计的挑战类似于制作流行歌曲。制作人会听这首歌一千次。但即使是第 999 次听,他们仍然需要想象第一次听到这首歌的人会觉得它是什么样子,这似乎……超级难。
This is probably why I ended up building dev tools rather than producing pop songs.
这可能就是为什么我最终构建了开发工具而不是制作流行歌曲。
Update: this post made it to Hacker News.
更新:这篇文章登上了 Hacker News。
Tagged with: software, programming
标签:软件, 编程