09/26/2024
AI
Enterprise 企业
The Future of Voice: Our Thoughts On How It Will Transform Conversational AI
语音的未来:我们对它如何改变对话式人工智能的看法
Enterprise Partner Lisa Han delves into why LLMs and multi-modal chatbots are the next leap forward in the evolution of voice.
企业合作伙伴 Lisa Han 深入探讨了为什么LLMs和多模态聊天机器人是语音演变的下一个飞跃。
A little over a decade ago, the movie Her introduced us to Samantha, an AI-powered operating system whose human companion falls in love with her through the sound of her voice.
十多年前,电影《她》向我们介绍了萨曼莎,一个由人工智能驱动的操作系统,她的伴侣通过她的声音爱上了她。
Back in 2013, this felt like science fiction–maybe even fantasy. But today, it looks more like a product road map. Since ChatGPT launched 18 months ago, we’ve witnessed step-function changes in innovation across a range of modalities, with perhaps voice emerging as a key frontier. And just recently, Open AI launched advanced voice mode, a feature part of ChatGPT that enables near-human-like audio conversations. As such, we are on the brink of a voice revolution, bringing us closer to the Her experience.
回到 2013 年,这感觉像是科幻小说——甚至可能是幻想。但今天,它更像是一个产品路线图。自从 ChatGPT 在 18 个月前推出以来,我们见证了各个领域创新的阶跃式变化,也许语音正成为一个关键的前沿。就在最近,Open AI 推出了高级语音模式,这是 ChatGPT 的一项功能,使得接近人类的音频对话成为可能。因此,我们正处于语音革命的边缘,让我们更接近 Her 的体验。
Large Language Models (LLMs) and multi-modal chatbots are radically transforming how companies communicate with customers and vice versa. And at Lightspeed, we’ve had dozens of conversations with researchers and founders who are building the next generation of voice applications. Here’s our take on where the voice market is today and where it’s headed in the coming years.
大型语言模型(LLMs)和多模态聊天机器人正在彻底改变公司与客户之间的沟通方式,反之亦然。在 Lightspeed,我们与正在构建下一代语音应用的研究人员和创始人进行了数十次对话。以下是我们对当前语音市场状况及其未来发展方向的看法。
How business found its voice
商业如何找到自己的声音
Commercial voice applications have evolved dramatically over the last 50 years. The first interactive voice response (IVR) system appeared in the 1970s, requiring end users to use a keypad to navigate through voice prompts. In the last two decades, we’ve seen this traditional, touch-tone model give way to something smarter: voice-driven phone trees, allowing customers to use natural language commands instead of just pressing buttons.
商业语音应用在过去 50 年中发生了巨大的变化。第一个交互式语音响应(IVR)系统出现在 1970 年代,要求最终用户使用键盘通过语音提示进行导航。在过去的二十年中,我们看到这种传统的触摸音调模型让位于更智能的东西:语音驱动的电话树,允许客户使用自然语言命令,而不仅仅是按按钮。
Now, we are entering the era of LLM-based systems, where end users don’t just talk to software, but have conversations with it. These systems understand the nuances and context just like a human would.
现在,我们正进入基于LLM的系统时代,最终用户不仅与软件对话,而是与之进行交流。这些系统理解细微差别和上下文,就像人类一样。
The Voice AI Opportunity
语音人工智能的机会
Today, the IVR market alone is worth $6 billion, and that’s before we consider the broader landscape of voice applications such as audiobooks and podcasts, translation and dubbing, gaming, and companionship apps. We believe the market for voice applications will grow by approximately fourfold, thanks to improvements in latency, tonality, and responsiveness driven by emerging AI architectures.
今天,仅 IVR 市场的价值就达 60 亿美元,这还不包括有声书和播客、翻译和配音、游戏以及陪伴应用等更广泛的语音应用市场。我们相信,由于新兴人工智能架构推动的延迟、音调和响应能力的改善,语音应用市场将增长约四倍。
In the short term, the most successful voice companies will be focused on vertical apps in fields like healthcare and hospitality, as well as apps designed for relatively simple tasks like scheduling. Eventually, however, these new voice apps are poised to wedge their way into broader SaaS platforms, significantly expanding the total addressable market.
在短期内,最成功的语音公司将专注于医疗保健和酒店等领域的垂直应用,以及旨在执行相对简单任务(如日程安排)的应用。然而,最终,这些新的语音应用有望进入更广泛的 SaaS 平台,显著扩大可服务的总市场。
Multi-modal chatbots like ChatGPT 4o not only allow organizations to establish closer, more personalized connections with users, they’re also able to collect information around tone, intent, and emotional state, using that data to improve their services and drive new product development.
多模态聊天机器人如 ChatGPT 不仅允许组织与用户建立更紧密、更个性化的联系,还能够收集有关语气、意图和情感状态的信息,利用这些数据来改善服务并推动新产品开发。
The current state of voice AI
语音人工智能的当前状态
Currently, AI-driven voice apps rely on three basic reference architectures devoted to ingesting natural language, interpreting it, and generating an intelligent response:
目前,基于人工智能的语音应用依赖于三种基本参考架构,专注于获取自然语言、解释它并生成智能响应:
- Speech to Text (STT) ingestion. Capturing spoken words and translating them into text.
语音转文本(STT)摄取。捕捉口语并将其翻译成文本。 - Text-to-Text (TTT) reasoning. Utilizing an LLM to tokenize the text transcription and formulate a written response.
文本到文本(TTT)推理。利用一个LLM对文本转录进行标记并形成书面回应。 - Text-to-Speech (TTS) generation. Translating that written response into spoken language.
文本到语音(TTS)生成。将书面回复翻译成口语。
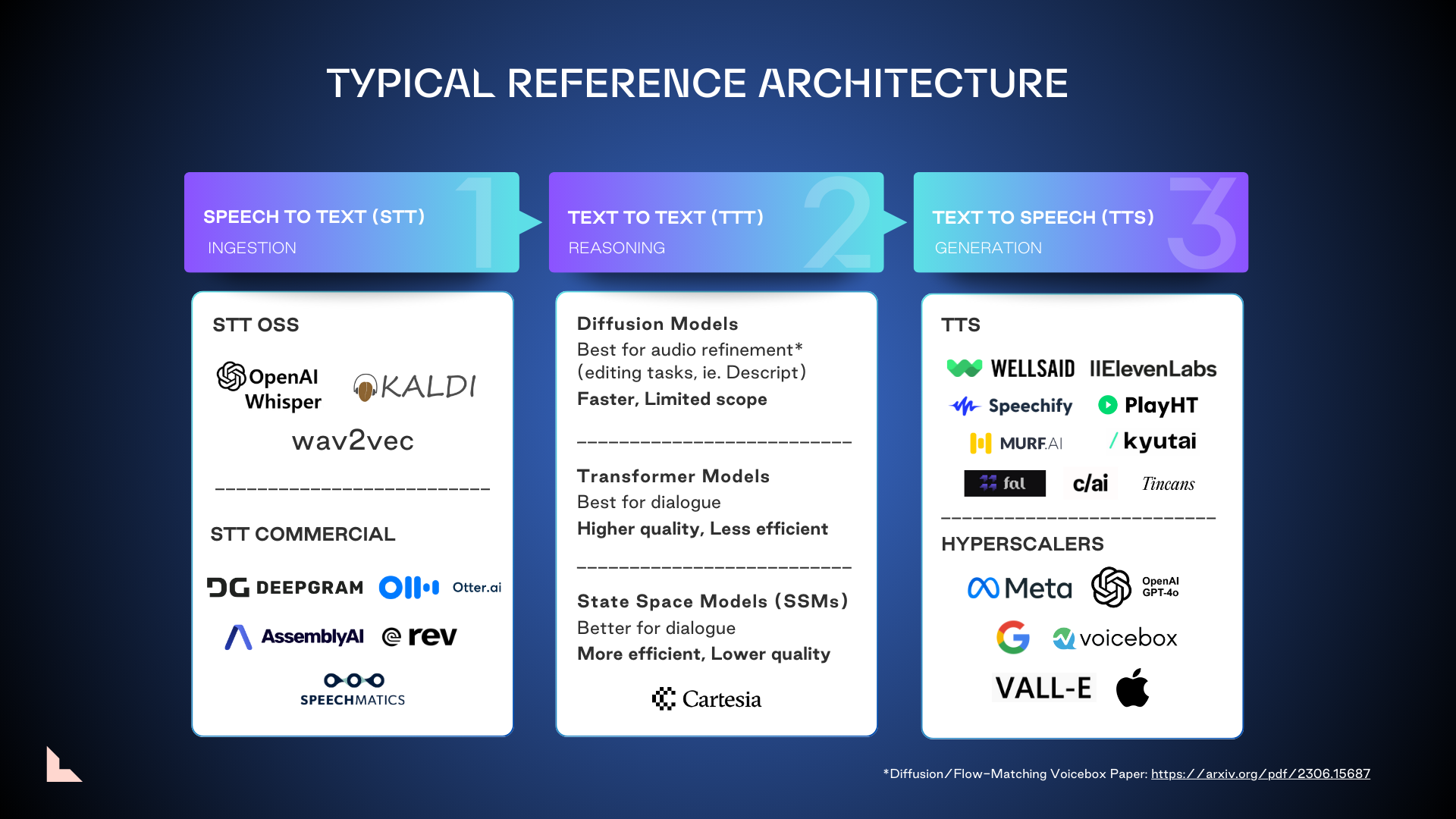
Text-to-text reasoning may involve two categories of models, each with its own strengths, weaknesses, and ideal use cases:
文本到文本的推理可能涉及两类模型,每类模型都有其自身的优点、缺点和理想的使用案例:
Category 1: Diffusion Models
类别 1:扩散模型
- Diffusion is an approach to generative modeling and can leverage either Transformers for denoising or SSMs (or both) as the model architecture. They are built by progressively introducing noise to a neural network’s training dataset, then teaching it to reverse this process. While diffusion models can sometimes leverage components of transformers, mainly for interpreting text inputs to condition outputs like images, audio, or video, the generative process itself remains distinctly diffusion-based. These models are faster than other models but more limited; they’re most useful for asynchronous editing and applications like audiobooks and podcasts. Given diffusion models lack reasoning capability, they are often viewed as “garnish” and combined with one or more other models.
扩散是一种生成建模的方法,可以利用变换器进行去噪或使用状态空间模型(或两者)作为模型架构。它们通过逐步向神经网络的训练数据集中引入噪声,然后教会它逆转这个过程来构建。虽然扩散模型有时可以利用变换器的组件,主要用于解释文本输入以条件输出如图像、音频或视频,但生成过程本身仍然明显基于扩散。这些模型比其他模型更快,但功能更有限;它们最适用于异步编辑和有声书、播客等应用。鉴于扩散模型缺乏推理能力,它们通常被视为“配料”,并与一个或多个其他模型结合使用。
Category 2: Autoregressive models like Transformers and State Space Models (SSMs)
类别 2:自回归模型,如变换器和状态空间模型 (SSMs)
- Transformer models work by remembering a sequence of inputs and transforming them into the desired outputs. They are best suited for scenarios requiring nuanced conversational abilities, such as 1:1 dialog or language translation. These models offer higher-quality outputs but require more memory and system resources.
变压器模型通过记住一系列输入并将其转换为所需的输出来工作。它们最适合需要细致对话能力的场景,例如一对一对话或语言翻译。这些模型提供更高质量的输出,但需要更多的内存和系统资源。 - SSMs respond to the current and most recent prior state of a conversation in time. This makes them faster and cheaper to maintain than memory-intensive transformer models. SSMs also offer lower latency and more lifelike voice reproduction, and they can ingest a much longer sequence of context than Transformers (it’s still to be determined as to whether or not they can really leverage that full sequence in a high-quality way). While they require less memory than transformers, the real challenge lies in leveraging their extended sequence processing for high-quality outputs.
SSM 在时间上响应对话的当前状态和最近的先前状态。这使得它们比内存密集型的变换器模型更快且更便宜。SSM 还提供更低的延迟和更逼真的语音再现,并且它们可以处理比变换器更长的上下文序列(尚待确定它们是否能够以高质量的方式真正利用整个序列)。虽然它们所需的内存少于变换器,但真正的挑战在于利用其扩展的序列处理来获得高质量的输出。
There have been significant strides across TTT, TTS, and S2S. Companies like Cartesia and Kyutai are making significant strides with state space models and open-source solutions. Meanwhile, hyperscalers like Meta Voicebox and OpenAI’s ChatGPT 4o are pushing the envelope with their TTS models.
在 TTT、TTS 和 S2S 方面取得了显著进展。像 Cartesia 和 Kyutai 这样的公司在状态空间模型和开源解决方案方面取得了重大进展。与此同时,像 Meta Voicebox 和 OpenAI 的 ChatGPT 4o 这样的超大规模公司正在推动他们的 TTS 模型的边界。
The next generation of voice AI
下一代语音人工智能
When it comes to the next wave of audio AI, there are four top contenders for new audio models, with varying levels of maturity.
当谈到下一波音频人工智能时,有四个顶级竞争者在新的音频模型中,成熟度各不相同。
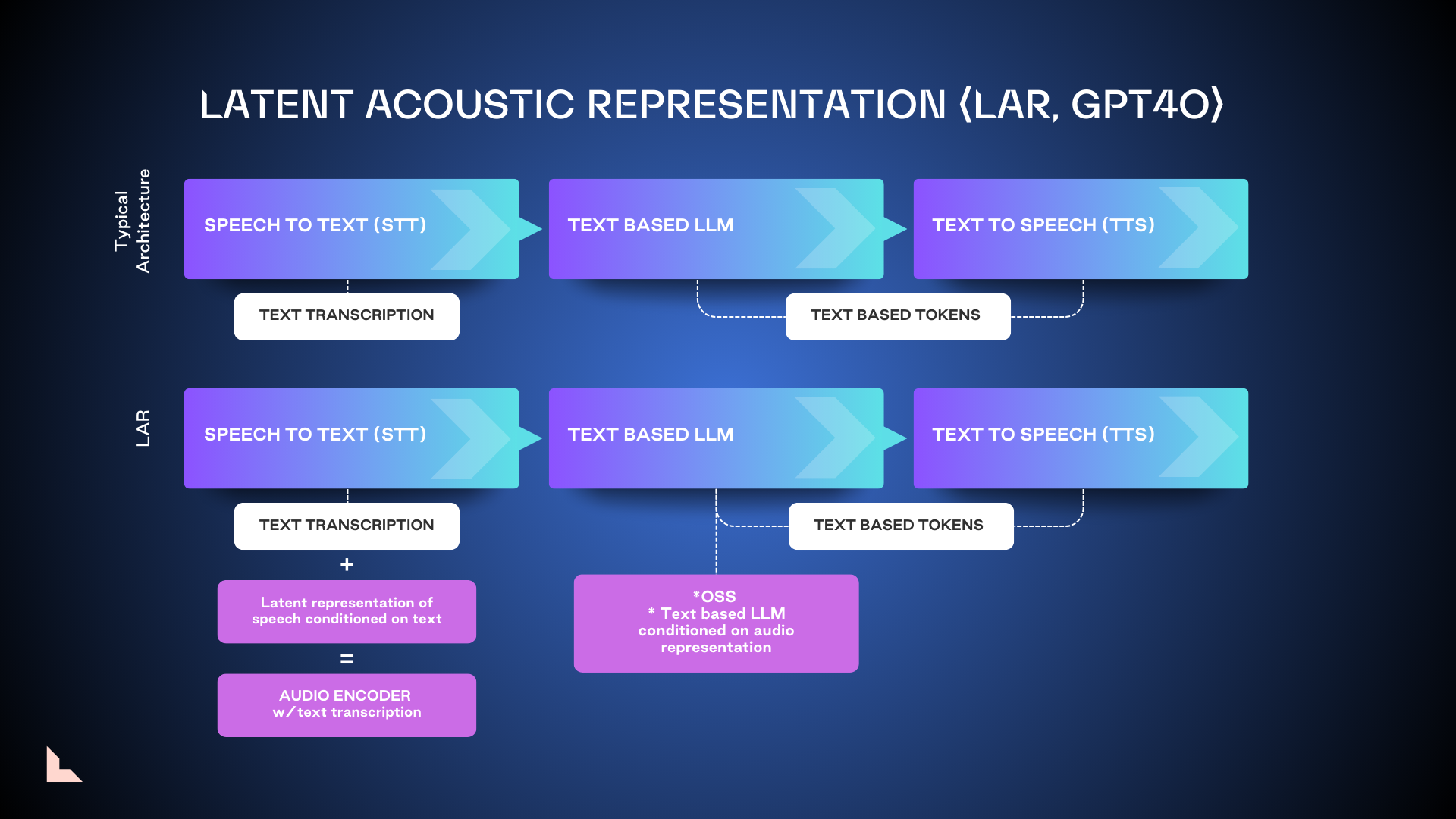
1. Latent Acoustic Representation (LAR)
1. 潜在声学表示 (LAR)
LAR, the model used as the foundation of GPT 4o, enriches acoustic context and delivers higher-quality outputs by not only converting audio into tokenized text, but also picking up metadata like acoustics, tone, and speaker intent. It is easier to train and can be brought to market faster, but not without its limitations.
LAR,作为 GPT 4o 的基础模型,通过不仅将音频转换为标记化文本,还捕捉声学、语调和说话者意图等元数据,丰富了声学上下文并提供了更高质量的输出。它更容易训练,并且可以更快地推向市场,但也有其局限性。
Because LAR is not trained end-to-end, it’s only suitable for very targeted use cases. Another drawback is that LAR needs to wait for recordings to finish before it can process them, leading to potential latency issues. We consider it a necessary interim step on the path toward tokenized speech models.
因为 LAR 不是端到端训练的,所以它只适合非常特定的用例。另一个缺点是 LAR 需要等待录音完成才能处理它们,这可能导致潜在的延迟问题。我们认为这是通往标记化语音模型的必要过渡步骤。
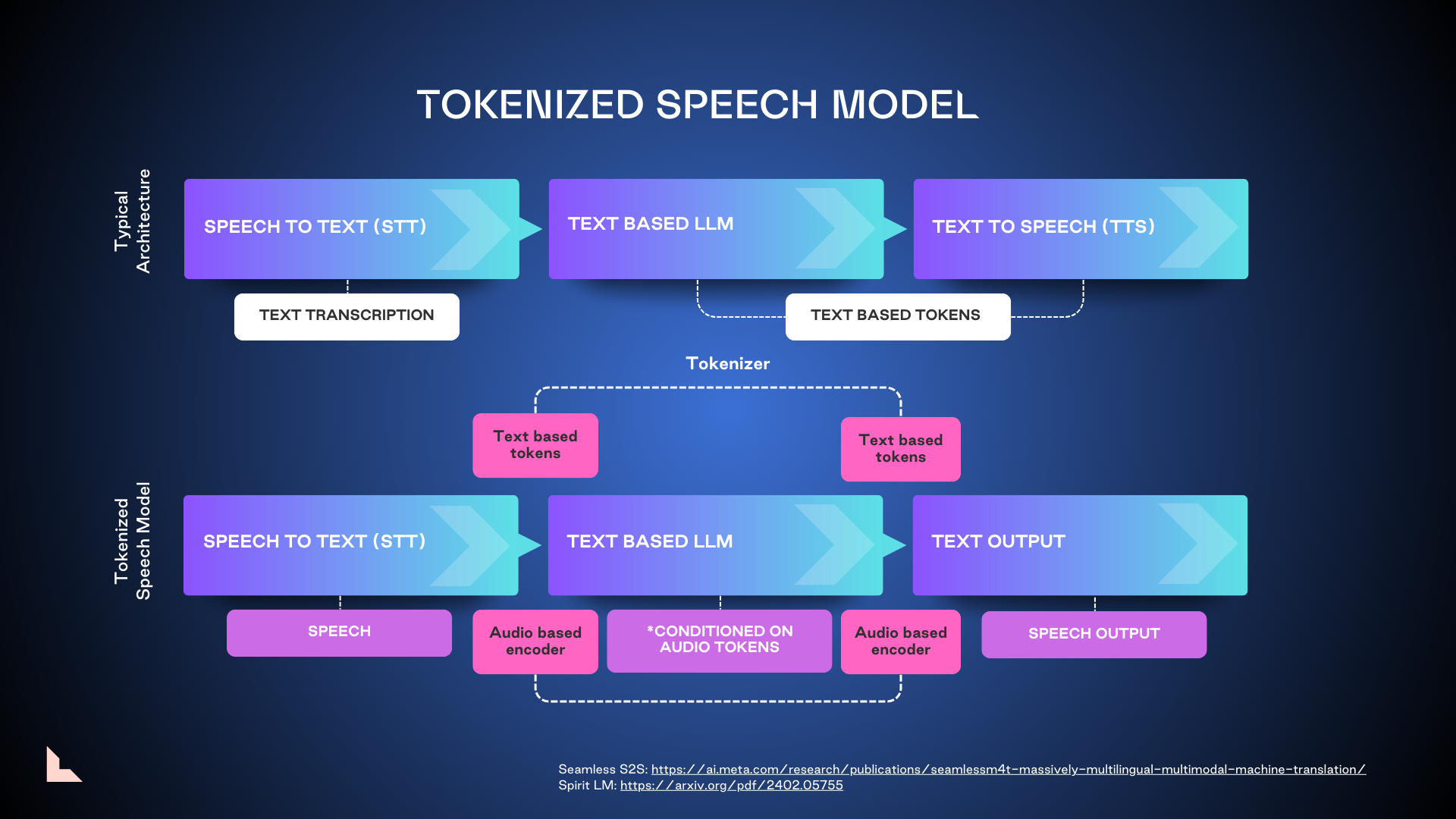
2. Tokenized speech model
2. 词元化语音模型
Tokenized speech represents a significant leap forward in voice AI technology. These models are already being incorporated into the next iterations of GPT 4.0 and Llama, using both text and audio-based encoders on either end to help yield more accurate outputs. But training these larger models is costly, and there are significant copyright concerns surrounding biometric speech processing. We expect this technology to be market-ready in the next two to three years.
分词语音代表了语音人工智能技术的重大进步。这些模型已经被纳入到 GPT 4.0 和 Llama 的下一版本中,使用文本和音频编码器来帮助产生更准确的输出。但训练这些更大模型的成本很高,并且围绕生物识别语音处理存在重大版权问题。我们预计这项技术将在未来两到三年内准备好进入市场。
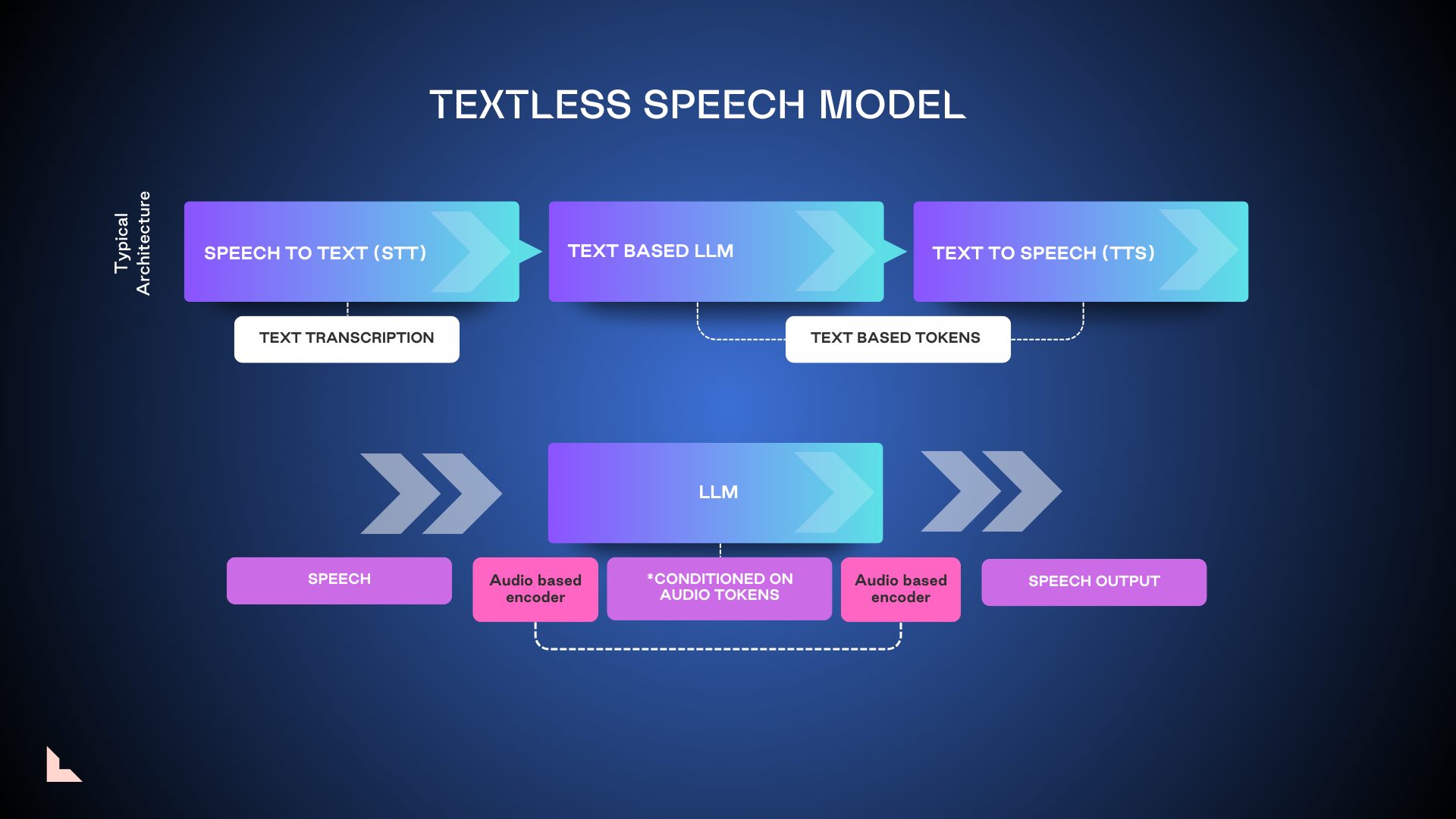
3. Textless speech model 3. 无文本语音模型
Textless models remove the initial step of transcribing spoken words into text, going directly from the spoken word into an LLM that’s been conditioned on audio tokens. The hope is that removing this step will reduce latency and enable a more human-like experience. However, the research to date indicates that textless models are much more resource-intensive, less performant, and less accurate than tokenized or LAR models.
无文本模型省去了将口语转录为文本的初始步骤,直接从口语进入经过音频标记条件化的LLM。希望通过去除这一步骤可以减少延迟,并实现更人性化的体验。然而,到目前为止的研究表明,无文本模型比标记化或 LAR 模型更消耗资源、性能更差且准确性更低。
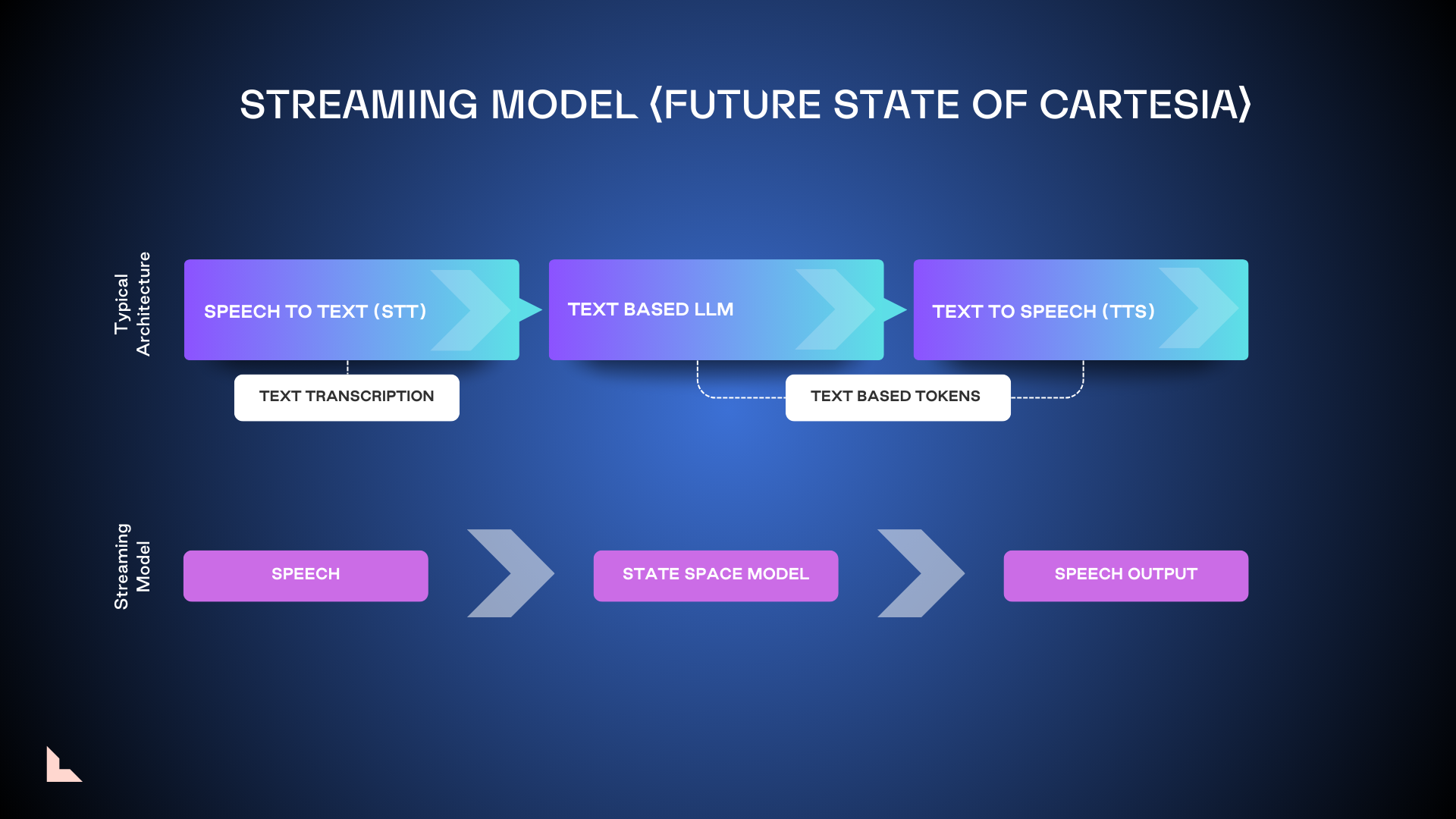
4. Streaming model 4. 流媒体模型
Streaming models ingest raw audio streams directly, no tokenization required. This allows developers to configure apps in an always-on state, without the need for conversational turn-taking. While this could potentially speed up voice processing, the always-on nature means it’s likely to be significantly more expensive to operate.
流媒体模型直接处理原始音频流,无需标记化。这使得开发者可以将应用程序配置为始终在线状态,而无需进行对话轮换。虽然这可能会加快语音处理速度,但始终在线的特性意味着其运营成本可能会显著更高。
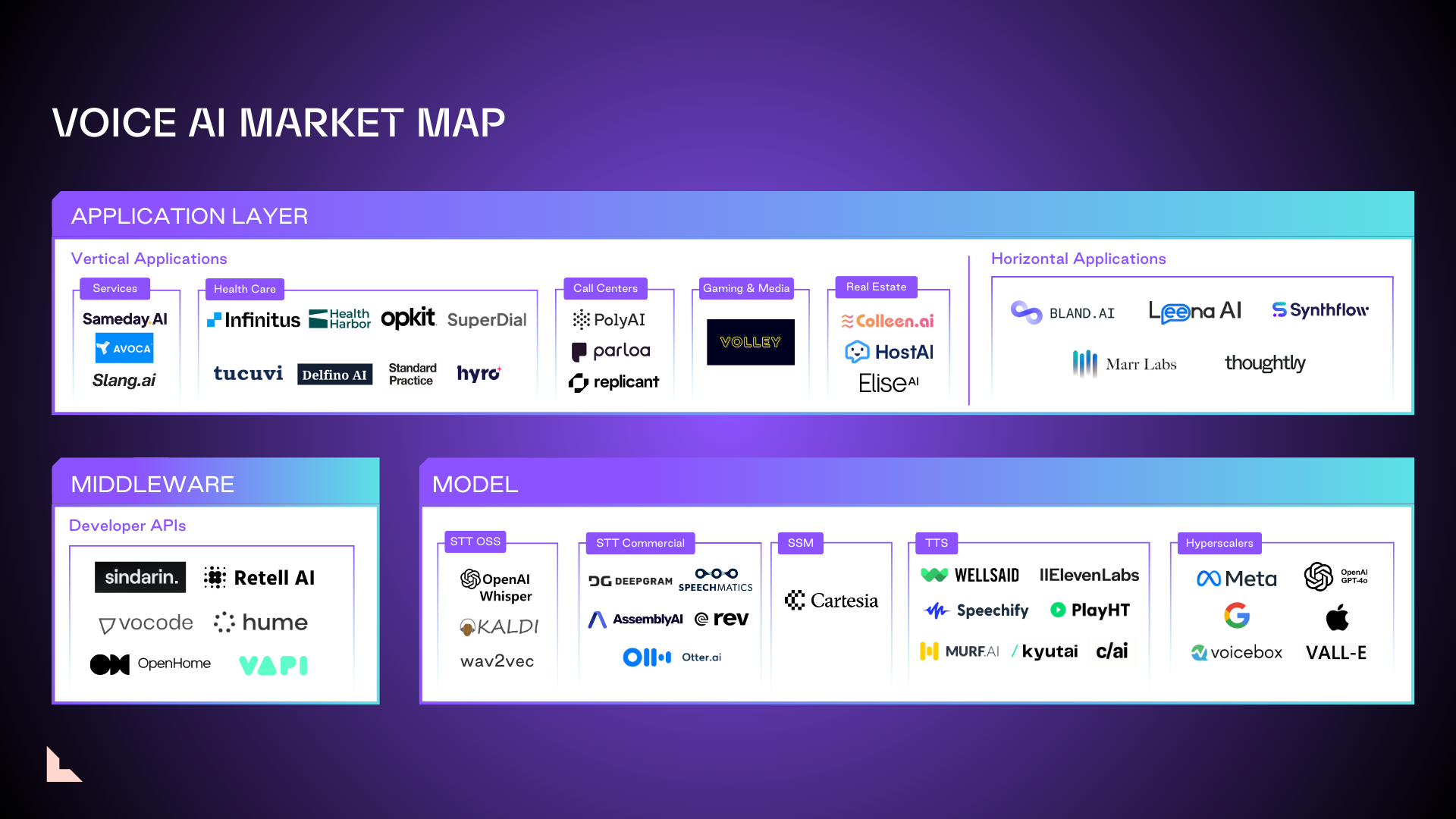
Where the voice AI market is headed and its challenges
语音人工智能市场的未来及其挑战
Having supported several leading voice AI companies, including Cartesia and Character AI, we believe there are three key challenges voice AI startups will need to overcome before they find their place in the market.
在支持了包括 Cartesia 和 Character AI 在内的几家领先的语音 AI 公司后,我们认为语音 AI 初创公司在找到市场定位之前需要克服三个关键挑战。
1. LLM first, but with humans in the loop: An important element in any human-AI interaction is recognizing when AI alone is not enough. Applications need the ability to escalate to human personnel seamlessly and efficiently before customers become frustrated. Companies also need the ability to trace root causes when voice apps fail or provide inaccurate information, which requires deep visibility into each layer of the technology.
1. LLM 首先,但要有人参与:任何人机交互中的一个重要元素是识别何时仅靠人工智能是不够的。应用程序需要能够在客户感到沮丧之前,无缝高效地升级到人类人员。公司还需要能够追踪语音应用失败或提供不准确信息时的根本原因,这需要对技术的每一层有深入的可见性。
2. Accelerating performance while lowering latency and cost: Providing near-real-time performance is a challenge for emerging architectures. Tuning generalized models on a per-customer basis at scale is important but can also be time- and resource-intensive. To elevate quality and intelligence, apps using transformer models will need to perform audio tokenization at scale. Reducing latency to sub 250 milliseconds is essential for a realistic conversational experience and is more easily achieved with self-assembling applications rather than full-stack architectures. Cost is always a factor: for voice agents at scale, a difference of a few cents per minute can be significant.
2. 加速性能,同时降低延迟和成本:为新兴架构提供近实时性能是一项挑战。根据每个客户的需求对通用模型进行调优在规模上是重要的,但也可能耗时且资源密集。为了提高质量和智能,使用变换器模型的应用程序需要在规模上进行音频标记化。将延迟降低到 250 毫秒以下对于实现真实的对话体验至关重要,并且通过自组装应用程序而不是全栈架构更容易实现。成本始终是一个因素:对于大规模的语音代理,每分钟几美分的差异可能是显著的。
3. Finding the right go-to-market strategy: At this stage, apps aimed at specific vertical markets have an edge over generalized multi-modal AI models. Enterprise-grade applications with strong concentrations in large verticals like healthcare or finance will be able to gain more traction early, though as new architectures emerge and prove their worth, that’s likely to change. A key to early success will be solving the last-mile problem, making the technology easily accessible to consumers and business users.
3. 寻找合适的市场进入策略:在这个阶段,针对特定垂直市场的应用程序相较于通用的多模态人工智能模型具有优势。专注于大型垂直市场(如医疗保健或金融)的企业级应用程序将能够更早获得关注,尽管随着新架构的出现并证明其价值,这种情况可能会改变。早期成功的关键在于解决最后一公里问题,使技术对消费者和商业用户易于获取。
We believe the most effective voice AI approach today uses a model that converts spoken language first into text and then tokenizes it–but one that can also ingest other audio content to deliver a richer, more life-like experience. However, the field is ripe for innovation. There’s still so much to explore, and more research is needed before we can determine if textless and streaming models can overcome their inherent limitations to find a place in the market.
我们相信,今天最有效的语音人工智能方法是使用一种模型,首先将口语转换为文本,然后进行分词——但这种模型也可以摄取其他音频内容,以提供更丰富、更逼真的体验。然而,这个领域充满了创新的机会。还有很多需要探索的内容,在我们能够确定无文本和流式模型是否能够克服其固有的局限性并在市场上找到立足之地之前,还需要更多的研究。
No matter how these technologies develop, we anticipate transformative applications in enterprise audio. People will begin to converse with companies in the same way they interact with their friends today. How organizations deploy voice AI will have an enormous influence on customer satisfaction and brand loyalty, with potentially positive or negative impacts, depending on the chosen tools and execution.
无论这些技术如何发展,我们都预期在企业音频中会出现变革性的应用。人们将开始以与朋友互动的方式与公司对话。组织如何部署语音人工智能将对客户满意度和品牌忠诚度产生巨大影响,具体影响可能是积极的或消极的,这取决于所选择的工具和执行方式。
We are not yet at the Her stage of voice technology, where people can develop deeply felt relationships through dialogs with machines, but we’re not that far off from it, either.
我们还没有达到与机器进行对话、建立深厚情感关系的“她”阶段,但我们也离这个阶段不远了。
JOIN US 加入我们
Voice technology will revolutionize how we work and play. If you’re a founder with a vision for technologies that can find a place in this exciting and fast-moving market, we’d love to connect. Say hi at lisa@lsvp.com.
语音技术将彻底改变我们的工作和娱乐方式。如果您是一位对能够在这个令人兴奋和快速发展的市场中找到立足之地的技术有愿景的创始人,我们很乐意与您联系。请通过 lisa@lsvp.com 打个招呼。
Many thanks to Karan Goel (Cartesia), Mati Staniszewski (Eleven Labs), Scott Stephenson (Deepgram), Yossi Adi (Facebook), as well as my colleagues Nnamdi Iregbulem and Raviraj Jain for their valuable contributions to this piece.
非常感谢 Karan Goel(Cartesia)、Mati Staniszewski(Eleven Labs)、Scott Stephenson(Deepgram)、Yossi Adi(Facebook),以及我的同事 Nnamdi Iregbulem 和 Raviraj Jain 对这篇文章的宝贵贡献。
Authors 作者


可能性随着你深入而增长。为未来的大胆建设者服务。

