
Overview of Algorithms 算法概述
An algorithm must be seen to be believed.
算法必须被看到才能相信。– Donald Knuth - 唐纳德·克努斯
This book covers the information needed to understand, classify, select, and implement important algorithms. In addition to explaining their logic, this book also discusses data structures, development environments, and production environments that are suitable for different classes of algorithms. This is the second edition of this book. In this edition, we especially focus on modern machine learning algorithms that are becoming more and more important. Along with the logic, practical examples of the use of algorithms to solve actual everyday problems are also presented.
本书涵盖了理解、分类、选择和实施重要算法所需的信息。除了解释它们的逻辑之外,本书还讨论了适用于不同类算法的数据结构、开发环境和生产环境。这是本书的第二版。在本版中,我们特别关注变得越来越重要的现代机器学习算法。除了逻辑之外,还提供了使用算法解决实际日常问题的实际示例。
This chapter provides an insight into the fundamentals of algorithms. It starts with a section on the basic concepts needed to understand the workings of different algorithms. To provide a historical perspective, this section summarizes how people started using algorithms to mathematically formulate a certain class of problems. It also mentions the limitations of different algorithms. The next section explains the various ways to specify the logic of an algorithm. As Python is used in this book to write the algorithms, how to set up a Python environment to run the examples is explained. Then, the various ways that an algorithm’s performance can be quantified and compared against other algorithms are discussed. Finally, this chapter discusses various ways a particular implementation of an algorithm can be validated.
本章介绍了算法基础知识。它从需要理解不同算法工作原理的基本概念部分开始。为了提供历史视角,本节总结了人们如何开始使用算法来数学地表达某一类问题。它还提到了不同算法的局限性。接下来的部分解释了指定算法逻辑的各种方法。由于本书中使用 Python 编写算法,因此解释了如何设置 Python 环境来运行示例。然后,讨论了衡量算法性能并与其他算法进行比较的各种方法。最后,本章讨论了验证算法特定实现的各种方法。
To sum up, this chapter covers the following main points:
总的来说,本章涵盖了以下主要要点:
- What is an algorithm?
什么是算法? - The phases of an algorithm
算法的阶段 - Development environment 开发环境
- Algorithm design techniques
算法设计技术 - Performance analysis 性能分析
- Validating an algorithm 验证算法
What is an algorithm?
什么是算法?
In the simplest terms, an algorithm is a set of rules for carrying out some calculations to solve a problem. It is designed to yield results for any valid input according to precisely defined instructions. If you look up the word algorithm in a dictionary (such as American Heritage), it defines the concept as follows:
简单来说,算法是一组用于执行某些计算以解决问题的规则。它旨在根据精确定义的指令为任何有效输入产生结果。如果您在词典(如《美国传统词典》)中查找算法一词,它会定义该概念如下:
An algorithm is a finite set of unambiguous instructions that, given some set of initial conditions, can be performed in a prescribed sequence to achieve a certain goal and that has a recognizable set of end conditions.
算法是一组有限的明确指令,给定一些初始条件后,可以按照规定的顺序执行,以实现特定目标,并具有可识别的一组结束条件。
Designing an algorithm is an effort to create a mathematical recipe in the most efficient way that can effectively be used to solve a real-world problem. This recipe may be used as the basis for developing a more reusable and generic mathematical solution that can be applied to a wider set of similar problems.
设计算法是一种努力,旨在以最有效的方式创建数学配方,以有效地解决现实世界的问题。这个配方可以作为开发更可重用和通用的数学解决方案的基础,可以应用于更广泛的类似问题集。
The phases of an algorithm
The different phases of developing, deploying, and finally, using an algorithm are illustrated in Figure 1.1:
开发、部署和最终使用算法的不同阶段如图 1.1 所示。
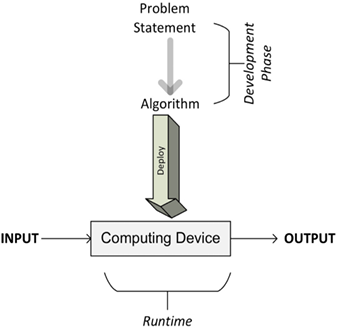
Figure 1.1: The different phases of developing, deploying, and using an algorithm
图 1.1:开发、部署和使用算法的不同阶段
As we can see, the process starts with understanding the requirements from the problem statement that details what needs to be done. Once the problem is clearly stated, it leads us to the development phase.
正如我们所看到的,流程始于理解问题陈述中详细说明需要完成的要求。一旦问题明确陈述,便引领我们进入开发阶段。
The development phase consists of two phases:
开发阶段包括两个阶段:
- The design phase: In the design phase, the architecture, logic, and implementation details of the algorithm are envisioned and documented. While designing an algorithm, we keep both accuracy and performance in mind. While searching for the best solution to a given problem, in many cases, we will end up having more than one candidate algorithm. The design phase of an algorithm is an iterative process that involves comparing different candidate algorithms. Some algorithms may provide simple and fast solutions but may compromise accuracy. Other algorithms may be very accurate but may take considerable time to run due to their complexity. Some of these complex algorithms may be more efficient than others. Before making a choice, all the inherent tradeoffs of the candidate algorithms should be carefully studied. Particularly for a complex problem, designing an efficient algorithm is important. A correctly designed algorithm will result in an efficient solution that will be capable of providing both satisfactory performance and reasonable accuracy at the same time.
设计阶段:在设计阶段,算法的架构、逻辑和实现细节被构想并记录下来。在设计算法时,我们会同时考虑准确性和性能。在寻找给定问题的最佳解决方案时,在许多情况下,我们最终会有多个候选算法。算法的设计阶段是一个迭代过程,涉及比较不同的候选算法。一些算法可能提供简单快速的解决方案,但可能会牺牲准确性。其他算法可能非常准确,但由于复杂性而需要较长时间才能运行。其中一些复杂算法可能比其他算法更有效。在做出选择之前,应仔细研究候选算法的所有固有权衡。特别是对于复杂问题,设计高效的算法是重要的。正确设计的算法将导致一个高效的解决方案,能够同时提供令人满意的性能和合理的准确性。 - The coding phase: In the coding phase, the designed algorithm is converted into a computer program. It is important that the computer program implements all the logic and architecture suggested in the design phase.
编码阶段:在编码阶段,设计好的算法被转换为计算机程序。重要的是,计算机程序要实现设计阶段建议的所有逻辑和架构。
The requirements of the business problem can be divided into functional and non-functional requirements. The requirements that directly specify the expected features of the solutions are called the functional requirements. Functional requirements detail the expected behavior of the solution. On the other hand, the non-functional requirements are about the performance, scalability, usability, and accuracy of the algorithm. Non-functional requirements also establish the expectations about the security of the data. For example, let us consider that we are required to design an algorithm for a credit card company that can identify and flag fraudulent transactions. Function requirements in this example will specify the expected behavior of a valid solution by providing the details of the expected output given a certain set of input data. In this case, the input data may be the details of the transaction, and the output may be a binary flag that labels a transaction as fraudulent or non-fraudulent. In this example, the non-functional requirements may specify the response time of each of the predictions. Non-functional requirements will also set the allowable thresholds for accuracy. As we are dealing with financial data in this example, the security requirements related to user authentication, authorization, and data confidentiality are also expected to be part of non-functional requirements.
业务问题的需求可以分为功能性和非功能性需求。直接指定解决方案预期功能的需求称为功能性需求。功能性需求详细说明解决方案的预期行为。另一方面,非功能性需求涉及算法的性能、可伸缩性、可用性和准确性。非功能性需求还建立了关于数据安全的期望。例如,让我们考虑一个要为信用卡公司设计算法以识别和标记欺诈交易的需求。在这个例子中,功能性需求将通过提供特定输入数据集的预期输出细节来指定有效解决方案的预期行为。在这种情况下,输入数据可能是交易的详细信息,输出可能是将交易标记为欺诈或非欺诈的二进制标志。在这个例子中,非功能性需求可能会指定每个预测的响应时间。非功能性需求还将设定准确性的允许阈值。 在这个示例中,由于我们处理的是财务数据,与用户身份验证、授权和数据保密性相关的安全要求也被期望作为非功能性需求的一部分。
Note that functional and non-functional requirements aim to precisely define what needs to be done. Designing the solution is about figuring out how it will be done. And implementing the design is developing the actual solution in the programming language of your choice. Coming up with a design that fully meets both functional and non-functional requirements may take lots of time and effort. The choice of the right programming language and development/production environment may depend on the requirements of the problem. For example, as C/C++ is a lower-level language than Python, it may be a better choice for algorithms needing compiled code and lower-level optimization.
请注意,功能性和非功能性需求旨在精确定义需要完成的工作。设计解决方案是为了弄清楚如何完成。实施设计是使用您选择的编程语言开发实际解决方案。设计出一个完全满足功能性和非功能性需求的方案可能需要大量的时间和精力。选择正确的编程语言和开发/生产环境可能取决于问题的需求。例如,由于 C/C++比 Python 是一种更低级别的语言,因此对于需要编译代码和更低级别优化的算法,它可能是更好的选择。
Once the design phase is completed and the coding is complete, the algorithm is ready to be deployed. Deploying an algorithm involves the design of the actual production environment in which the code will run. The production environment needs to be designed according to the data and processing needs of the algorithm. For example, for parallelizable algorithms, a cluster with an appropriate number of computer nodes will be needed for the efficient execution of the algorithm. For data-intensive algorithms, a data ingress pipeline and the strategy to cache and store data may need to be designed. Designing a production environment is discussed in more detail in Chapter 15, Large-Scale Algorithms, and Chapter 16, Practical Considerations.
设计阶段完成并编码完成后,算法即可部署。部署算法涉及设计实际生产环境,其中代码将运行。生产环境需要根据算法的数据和处理需求进行设计。例如,对于可并行化的算法,需要一个具有适当数量计算节点的集群,以便有效执行算法。对于数据密集型算法,可能需要设计数据进入管道以及缓存和存储数据的策略。有关设计生产环境的讨论详见第 15 章《大规模算法》和第 16 章《实际考虑事项》。
Once the production environment is designed and implemented, the algorithm is deployed, which takes the input data, processes it, and generates the output as per the requirements.
一旦生产环境设计和实施完成,算法就会部署,它会获取输入数据,处理数据,并根据要求生成输出。
Development environment 开发环境
Once designed, algorithms need to be implemented in a programming language as per the design. For this book, we have chosen the programming language Python. We chose it because Python is flexible and is an open-source programming language. Python is also one of the languages that you can use in various cloud computing infrastructures, such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP).
一旦设计完成,算法需要根据设计在编程语言中实现。对于本书,我们选择了编程语言 Python。我们选择 Python 是因为它灵活且是一种开源编程语言。Python 也是您可以在各种云计算基础设施中使用的语言之一,例如亚马逊网络服务(AWS)、微软 Azure 和谷歌云平台(GCP)。
The official Python home page is available at https://www.python.org/, which also has instructions for installation and a useful beginner’s guide.
官方 Python 主页位于 https://www.python.org/,上面还提供了安装说明和一个有用的初学者指南。
A basic understanding of Python is required to better understand the concepts presented in this book.
阅读本书需要对 Python 有基本的了解。
For this book, we expect you to use the most recent version of Python 3. At the time of writing, the most recent version is 3.10, which is what we will use to run the exercises in this book.
对于本书,我们希望您使用最新版本的 Python 3。在撰写本文时,最新版本是 3.10,这也是我们将用来运行本书中的练习。
We will be using Python throughout this book. We will also be using Jupyter Notebook to run the code. The rest of the chapters in this book assume that Python is installed and Jupyter Notebook has been properly configured and is running.
本书将始终使用 Python。我们还将使用 Jupyter Notebook 来运行代码。本书的其余章节假定 Python 已安装,并且 Jupyter Notebook 已正确配置并正在运行。
Python packages Python 软件包
Python is a general-purpose language. It follows the philosophy of “batteries included,” which means that there is a standard library that is available, without making the user download separate packages. However, the standard library modules only provide the bare minimum functionality. Based on the specific use case you are working on, additional packages may need to be installed. The official third-party repository for Python packages is called PyPI, which stands for Python Package Index. It hosts Python packages both as source distribution and pre-compiled code. Currently, there are more than 113,000 Python packages hosted at PyPI. The easiest way to install additional packages is through the pip package management system. pip is a nerdy recursive acronym, which are abundant in Python culture. pip stands for Pip Installs Python. The good news is that starting from version 3.4 of Python, pip is installed by default. To check the version of pip, you can type on the command line:
Python 是一种通用语言。它遵循“电池全装”哲学,这意味着有一个标准库可供使用,无需用户下载单独的软件包。然而,标准库模块仅提供最基本的功能。根据您正在处理的特定用例,可能需要安装额外的软件包。Python 软件包的官方第三方存储库称为 PyPI,代表 Python 软件包索引。它托管 Python 软件包的源分发和预编译代码。目前,PyPI 托管了超过 113,000 个 Python 软件包。安装额外软件包的最简单方法是通过 pip 软件包管理系统。 pip 是一个书呆子递归首字母缩略语,在 Python 文化中很常见。 pip 代表 Pip Installs Python。好消息是,从 Python 的 3.4 版本开始, pip 会默认安装。要检查 pip 的版本,您可以在命令行上输入:
This pip command can be used to install additional packages:
此 pip 命令可用于安装额外的软件包:
The packages that have already been installed need to be periodically updated to get the latest functionality. This is achieved by using the upgrade flag:
已安装的软件包需要定期更新以获得最新功能。这可以通过使用 upgrade 标志来实现:
And to install a specific version of a Python package:
安装特定版本的 Python 软件包:
Adding the right libraries and versions has become part of setting up the Python programming environment. One feature that helps with maintaining these libraries is the ability to create a requirements file that lists all the packages that are needed. The requirements file is a simple text file that contains the name of the libraries and their associated versions. A sample of the requirements file looks as follows:
添加正确的库和版本已经成为设置 Python 编程环境的一部分。一个有助于维护这些库的功能是能够创建一个要求文件,列出所有需要的软件包。要求文件是一个简单的文本文件,包含库的名称及其相关版本。要求文件的示例如下:
scikit-learn==0.24.1
tensorflow==2.5.0
tensorboard==2.5.0
By convention, the requirements.txt is placed in the project’s top-level directory.
按照惯例, requirements.txt 被放置在项目的顶层目录中。
Once created, the requirements file can be used to set up the development environment by installing all the Python libraries and their associated versions by using the following command:
一旦创建完成,可以使用以下命令来设置开发环境,通过安装所有 Python 库及其关联版本来使用要求文件:
Now let us look into the main packages that we will be using in this book.
现在让我们来看一下本书中将要使用的主要软件包。
The SciPy ecosystem SciPy 生态系统
Scientific Python (SciPy)—pronounced sigh pie—is a group of Python packages created for the scientific community. It contains many functions, including a wide range of random number generators, linear algebra routines, and optimizers.
Scientific Python(SciPy)—发音为 sigh pie—是为科学界创建的一组 Python 软件包。它包含许多函数,包括各种随机数生成器、线性代数例程和优化器。
SciPy is a comprehensive package and, over time, people have developed many extensions to customize and extend the package according to their needs. SciPy is performant as it acts as a thin wrapper around optimized code written in C/C++ or Fortran.
SciPy 是一个综合性软件包,随着时间的推移,人们开发了许多扩展来根据自己的需求定制和扩展软件包。SciPy 的性能很高,因为它作为一个薄包装器,围绕着用 C/C++ 或 Fortran 编写的优化代码。
The following are the main packages that are part of this ecosystem:
以下是该生态系统的主要软件包:
- NumPy: For algorithms, the ability to create multi-dimensional data structures, such as arrays and matrices, is really important. NumPy offers a set of array and matrix data types that are important for statistics and data analysis. Details about NumPy can be found at http://www.numpy.org/.
NumPy:对于算法而言,能够创建多维数据结构(如数组和矩阵)非常重要。NumPy 提供了一组对统计和数据分析至关重要的数组和矩阵数据类型。有关 NumPy 的详细信息,请访问 http://www.numpy.org/。 - scikit-learn: This machine learning extension is one of the most popular extensions of SciPy. Scikit-learn provides a wide range of important machine learning algorithms, including classification, regression, clustering, and model validation. You can find more details about scikit-learn at http://scikit-learn.org/.
scikit-learn:这个机器学习扩展是 SciPy 最受欢迎的扩展之一。Scikit-learn 提供了广泛的重要机器学习算法,包括分类、回归、聚类和模型验证。您可以在 http://scikit-learn.org/找到有关 scikit-learn 的更多详细信息。 - pandas: pandas contains the tabular complex data structure that is used widely to input, output, and process tabular data in various algorithms. The pandas library contains many useful functions and it also offers highly optimized performance. More details about pandas can be found at http://pandas.pydata.org/.
pandas:pandas 包含了广泛使用的表格复杂数据结构,用于在各种算法中输入、输出和处理表格数据。pandas 库包含许多有用的函数,同时还提供高度优化的性能。有关 pandas 的更多详细信息,请访问 http://pandas.pydata.org/。 - Matplotlib: Matplotlib provides tools to create powerful visualizations. Data can be presented as line plots, scatter plots, bar charts, histograms, pie charts, and so on. More information can be found at https://matplotlib.org/.
Matplotlib:Matplotlib 提供了创建强大可视化的工具。数据可以呈现为折线图、散点图、条形图、直方图、饼图等形式。更多信息请访问 https://matplotlib.org/。
Using Jupyter Notebook 使用 Jupyter Notebook
We will be using Jupyter Notebook and Google’s Colaboratory as the IDE. More details about the setup and the use of Jupyter Notebook and Colab can be found in Appendix A and B.
我们将使用 Jupyter Notebook 和 Google 的 Colaboratory 作为 IDE。有关 Jupyter Notebook 和 Colab 的设置和使用的更多细节,请参阅附录 A 和 B。
Algorithm design techniques
算法设计技术
An algorithm is a mathematical solution to a real-world problem. When designing an algorithm, we keep the following three design concerns in mind as we work on designing and fine-tuning the algorithms:
算法是对现实世界问题的数学解决方案。在设计算法时,我们会牢记以下三个设计关注点,以便在设计和优化算法时进行工作:
- Concern 1: Is this algorithm producing the result we expected?
关注点 1:这个算法是否产生了我们预期的结果? - Concern 2: Is this the most optimal way to get these results?
关注点 2:这是否是获得这些结果的最佳方式? - Concern 3: How is the algorithm going to perform on larger datasets?
关注点 3:算法在更大数据集上的表现如何?
It is important to understand the complexity of the problem itself before designing a solution for it. For example, it helps us to design an appropriate solution if we characterize the problem in terms of its needs and complexity.
在为问题设计解决方案之前,了解问题本身的复杂性是非常重要的。例如,如果我们能够根据问题的需求和复杂性来描述问题,那么这有助于我们设计出一个合适的解决方案。
Generally, the algorithms can be divided into the following types based on the characteristics of the problem:
通常,根据问题特征,算法可以分为以下类型:
- Data-intensive algorithms: Data-intensive algorithms are designed to deal with a large amount of data. They are expected to have relatively simplistic processing requirements. A compression algorithm applied to a huge file is a good example of data-intensive algorithms. For such algorithms, the size of the data is expected to be much larger than the memory of the processing engine (a single node or cluster), and an iterative processing design may need to be developed to efficiently process the data according to the requirements.
数据密集型算法:数据密集型算法旨在处理大量数据。预期其处理要求相对简单。应用于大文件的压缩算法是数据密集型算法的一个很好的例子。对于这样的算法,数据的大小预计会远远大于处理引擎(单个节点或集群)的内存,可能需要开发迭代处理设计,以根据要求高效处理数据。 - Compute-intensive algorithms: Compute-intensive algorithms have considerable processing requirements but do not involve large amounts of data. A simple example is the algorithm to find a very large prime number. Finding a strategy to divide the algorithm into different phases so that at least some of the phases are parallelized is key to maximizing the performance of the algorithm.
计算密集型算法:计算密集型算法具有相当大的处理要求,但不涉及大量数据。一个简单的例子是查找一个非常大的质数的算法。找到一种将算法分解为不同阶段的策略,以便至少有一些阶段是并行化的,是最大化算法性能的关键。 - Both data and compute-intensive algorithms: There are certain algorithms that deal with a large amount of data and also have considerable computing requirements. Algorithms used to perform sentiment analysis on live video feeds are a good example of where both the data and the processing requirements are huge in accomplishing the task. Such algorithms are the most resource-intensive algorithms and require careful design of the algorithm and intelligent allocation of available resources.
既数据密集又计算密集的算法:存在一些算法处理大量数据,同时具有相当大的计算需求。用于对实时视频流执行情感分析的算法是一个很好的例子,其中数据和处理需求都很大以完成任务。这类算法是最消耗资源的算法,需要仔细设计算法并智能分配可用资源。
To characterize the problem in terms of its complexity and needs, it helps if we study its data and compute dimensions in more depth, which we will do in the following section.
为了从复杂性和需求方面描述问题,有助于我们更深入地研究数据和计算维度,这将在下一节中进行。
The data dimension 数据维度
To categorize the data dimension of the problem, we look at its volume, velocity, and variety (the 3Vs), which are defined as follows:
为了对问题的数据维度进行分类,我们看其数据量、速度和多样性(即 3V),定义如下:
- Volume: The volume is the expected size of the data that the algorithm will process.
体积:体积是算法将处理的数据的预期大小。 - Velocity: The velocity is the expected rate of new data generation when the algorithm is used. It can be zero.
速度:速度是算法使用时新数据生成的预期速率。它可以为零。 - Variety: The variety quantifies how many different types of data the designed algorithm is expected to deal with.
种类:种类量化了设计算法预计要处理多少不同类型的数据。
Figure 1.2 shows the 3Vs of the data in more detail. The center of this diagram shows the simplest possible data, with a small volume and low variety and velocity. As we move away from the center, the complexity of the data increases. It can increase in one or more of the three dimensions.
图 1.2 显示了数据的 3V 更详细的信息。该图的中心显示了最简单的数据,具有较小的容量、低多样性和速度。随着我们远离中心,数据的复杂性增加。它可以在三个维度中的一个或多个维度上增加。
For example, in the dimension of velocity, we have the batch process as the simplest, followed by the periodic process, and then the near real-time process. Finally, we have the real-time process, which is the most complex to handle in the context of data velocity. For example, a collection of live video feeds gathered by a group of monitoring cameras will have a high volume, high velocity, and high variety and may need an appropriate design to have the ability to store and process data effectively:
例如,在速度维度上,我们有批处理作为最简单的,其次是周期性处理,然后是准实时处理。最后,我们有实时处理,这在数据速度的背景下是最复杂的处理。例如,由一组监控摄像头收集的实时视频流集合将具有高容量、高速度和高多样性,并且可能需要适当的设计来具有有效存储和处理数据的能力:
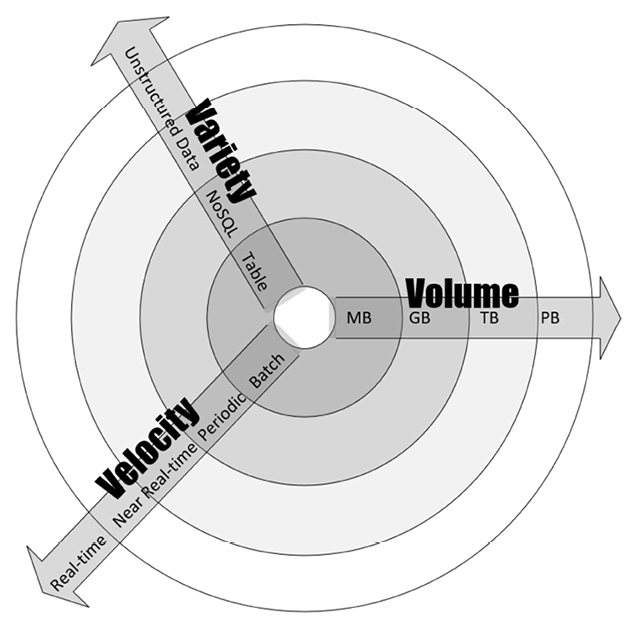
Figure 1.2: 3Vs of Data: Volume, Velocity, and Variety
图 1.2:数据的 3V:Volume(容量)、Velocity(速度)和 Variety(多样性)
Let us consider three examples of use cases having three different types of data:
让我们考虑三个使用案例的例子,这三个案例涉及三种不同类型的数据:
- First, consider a simple data-processing use case where the input data is a .
csvfile. In this case, the volume, velocity, and variety of the data will be low.
首先,考虑一个简单的数据处理用例,其中输入数据是一个 .csv文件。在这种情况下,数据的容量、速度和多样性将会很低。 - Second, consider the use case where the input data is the live stream of a security video camera. Now the volume, velocity, and variety of the data will be quite high and should be kept in mind while designing an algorithm for it.
其次,考虑输入数据为安全视频摄像头的实时流的使用情况。现在数据的数量、速度和多样性将会非常高,在设计算法时应牢记这一点。 - Third, consider the use case of a typical sensor network. Let us assume that the data source of the sensor network is a mesh of temperature sensors installed in a large building. Although the velocity of the data being generated is typically very high (as new data is being generated very quickly), the volume is expected to be quite low (as each data element is typically only 16-bits long consisting of an 8-bit measurement plus 8-bit metadata such as a timestamp and the geo-coordinates.
第三,考虑典型传感器网络的使用情况。假设传感器网络的数据源是安装在大型建筑物中的温度传感器网格。尽管生成的数据速度通常非常快(因为新数据生成速度很快),但体积预计会相当小(因为每个数据元素通常只有 16 位长,包括 8 位测量值和 8 位元数据,如时间戳和地理坐标)。
The processing requirements, storage needs, and suitable software stack selection will be different for all the above three examples and, in general, are dependent on the volume, velocity, and variety of the data sources. It is important to first characterize data as the first step of designing an algorithm.
以上三个示例的处理要求、存储需求和适当的软件堆栈选择将有所不同,通常取决于数据源的数量、速度和多样性。首先对数据进行表征是设计算法的第一步,这一点非常重要。
The compute dimension 计算维度
To characterize the compute dimension, we analyze the processing needs of the problem at hand. The processing needs of an algorithm determine what sort of design is most efficient for it. For example, complex algorithms, in general, require lots of processing power. For such algorithms, it may be important to have multi-node parallel architecture. Modern deep algorithms usually involve considerable numeric processing and may need the power of GPUs or TUPs as discussed in Chapter 16, Practical Considerations.
为了描述计算维度,我们分析手头问题的处理需求。算法的处理需求决定了最适合它的设计类型。例如,一般而言,复杂算法需要大量的处理能力。对于这类算法,拥有多节点并行架构可能很重要。现代深度算法通常涉及大量的数值处理,可能需要 GPU 或 TUP 的强大性能,如第 16 章“实际考虑”中所讨论的。
Performance analysis 性能分析
Analyzing the performance of an algorithm is an important part of its design. One of the ways to estimate the performance of an algorithm is to analyze its complexity.
分析算法的性能是其设计的重要部分。估计算法性能的一种方法是分析其复杂性。
Complexity theory is the study of how complicated algorithms are. To be useful, any algorithm should have three key features:
复杂性理论是研究复杂算法的学科。为了有用,任何算法都应具备三个关键特征:
- Should be correct: A good algorithm should produce the correct result. To confirm that an algorithm is working correctly, it needs to be extensively tested, especially testing edge cases.
应该是正确的:一个好的算法应该产生正确的结果。要确认算法是否正常工作,需要进行广泛的测试,特别是测试边缘情况。 - Should be understandable: A good algorithm should be understandable. The best algorithm in the world is not very useful if it’s too complicated for us to implement on a computer.
应该易于理解:一个好的算法应该易于理解。即使世界上最好的算法,如果对我们来说在计算机上实现起来太复杂,也就不太有用。 - Should be efficient: A good algorithm should be efficient. Even if an algorithm produces the correct result, it won’t help us much if it takes a thousand years or if it requires 1 billion terabytes of memory.
应该高效:一个好的算法应该是高效的。即使一个算法能够产生正确的结果,如果它需要一千年的时间或者需要一百亿太字节的内存,那也不会对我们有太大帮助。
There are two possible types of analysis to quantify the complexity of an algorithm:
有两种可能的分析类型来量化算法的复杂性:
- Space complexity analysis: Estimates the runtime memory requirements needed to execute the algorithm.
空间复杂度分析:估计执行算法所需的运行时内存需求。 - Time complexity analysis: Estimates the time the algorithm will take to run.
时间复杂度分析:估计算法运行所需的时间。
Let us study them one by one:
让我们逐一研究它们:
Space complexity analysis
空间复杂度分析
Space complexity analysis estimates the amount of memory required by the algorithm to process input data. While processing the input data, the algorithm needs to store the transient temporary data structures in memory. The way the algorithm is designed affects the number, type, and size of these data structures. In an age of distributed computing and with increasingly large amounts of data that needs to be processed, space complexity analysis is becoming more and more important. The size, type, and number of these data structures will dictate the memory requirements for the underlying hardware. Modern in-memory data structures used in distributed computing need to have efficient resource allocation mechanisms that are aware of the memory requirements at different execution phases of the algorithm. Complex algorithms tend to be iterative in nature. Instead of bringing all the information into the memory at once, such algorithms iteratively populate the data structures. To calculate the space complexity, it is important to first classify the type of iterative algorithm we plan to use. An iterative algorithm can use one of the following three types of iterations:
空间复杂度分析估计算法处理输入数据所需的内存量。在处理输入数据时,算法需要将瞬时临时数据结构存储在内存中。算法的设计方式会影响这些数据结构的数量、类型和大小。在分布式计算时代和需要处理的数据量越来越大的情况下,空间复杂度分析变得越来越重要。这些数据结构的大小、类型和数量将决定底层硬件的内存需求。在分布式计算中使用的现代内存数据结构需要具有高效的资源分配机制,能够意识到算法不同执行阶段的内存需求。复杂算法往往是迭代性质的。这类算法不会一次性将所有信息加载到内存中,而是迭代地填充数据结构。要计算空间复杂度,首先需要对计划使用的迭代算法类型进行分类。迭代算法可以使用以下三种类型的迭代之一:
- Converging Iterations: As the algorithm proceeds through iterations, the amount of data it processes in each individual iteration decreases. In other words, space complexity decreases as the algorithm proceeds through its iterations. The main challenge is to tackle the space complexity of the initial iterations. Modern scalable cloud infrastructures such as AWS and Google Cloud are best suited to run such algorithms.
迭代收敛:随着算法进行迭代,每个单独迭代处理的数据量会减少。换句话说,随着算法进行迭代,空间复杂度会降低。主要挑战是解决初始迭代的空间复杂度。现代可扩展的云基础设施,如 AWS 和 Google Cloud,最适合运行这类算法。 - Diverging Iterations: As the algorithm proceeds through iterations, the amount of data it processes in each individual iteration increases. As the space complexity increases with the algorithm’s progress through iterations, it is important to set constraints to prevent the system from becoming unstable. The constraints can be set by limiting the number of iterations and/or by setting a limit on the size of initial data.
迭代分歧:随着算法在迭代过程中的进行,每个单独迭代中处理的数据量增加。随着算法在迭代中的进展,空间复杂度增加,设置约束以防止系统变得不稳定变得重要。这些约束可以通过限制迭代次数和/或设置初始数据大小的限制来实现。 - Flat Iterations: As the algorithm proceeds through iterations, the amount of data it processes in each individual iteration remains constant. As space complexity does not change, elasticity in infrastructure is not needed.
平面迭代:随着算法在迭代中进行,每个单独迭代中处理的数据量保持不变。由于空间复杂度不变,因此不需要基础设施的弹性。
To calculate the space complexity, we need to focus on one of the most complex iterations. In many algorithms, as we converge towards the solution, the resource needs are gradually reduced. In such cases, initial iterations are the most complex and give us a better estimate of space complexity. Once chosen, we estimate the total amount of memory used by the algorithm, including the memory used by its transient data structures, execution, and input values. This will give us a good estimate of the space complexity of an algorithm.
为了计算空间复杂度,我们需要关注其中最复杂的迭代之一。在许多算法中,随着我们收敛于解决方案,资源需求逐渐减少。在这种情况下,初始迭代是最复杂的,并为我们提供了空间复杂度的更好估计。一旦选择了,我们估计算法使用的总内存量,包括其瞬时数据结构、执行和输入值使用的内存。这将为我们提供算法的空间复杂度的良好估计。
The following are guidelines to minimize the space complexity:
以下是最小化空间复杂度的准则:
- Whenever possible, try to design an algorithm as iterative.
尽可能地,尝试将算法设计为迭代。 - While designing an iterative algorithm, whenever there is a choice, prefer a larger number of iterations over a smaller number of iterations. A fine-grained larger number of iterations is expected to have less space complexity.
在设计迭代算法时,每当有选择时,更倾向于选择较多次迭代而非较少次迭代。预计细粒度的较多次迭代将具有较低的空间复杂度。 - Algorithms should bring only the information needed for current processing into memory. Whatever is not needed should be flushed out from the memory.
算法应该只将当前处理所需的信息加载到内存中。不需要的信息应该从内存中清除。
Space complexity analysis is a must for the efficient design of algorithms. If proper space complexity analysis is not conducted while designing a particular algorithm, insufficient memory availability for the transient temporary data structures may trigger unnecessary disk spillovers, which could potentially considerably affect the performance and efficiency of the algorithm.
空间复杂度分析对于算法的高效设计至关重要。如果在设计特定算法时未进行适当的空间复杂度分析,可能会导致瞬时临时数据结构的内存不足,触发不必要的磁盘溢出,从而可能显著影响算法的性能和效率。
In this chapter, we will look deeper into time complexity. Space complexity will be discussed in Chapter 15, Large-Scale Algorithms, in more detail, where we will deal with large-scale distributed algorithms with complex runtime memory requirements.
在本章中,我们将更深入地探讨时间复杂度。空间复杂度将在第 15 章《大规模算法》中更详细地讨论,在那里我们将处理具有复杂运行时内存需求的大规模分布式算法。
Time complexity analysis
时间复杂度分析
Time complexity analysis estimates how long it will take for an algorithm to complete its assigned job based on its structure. In contrast to space complexity, time complexity is not dependent on any hardware that the algorithm will run on. Time complexity analysis solely depends on the structure of the algorithm itself. The overall goal of time complexity analysis is to try to answer these important two questions:
时间复杂度分析根据算法的结构估计算法完成其分配的工作需要多长时间。与空间复杂度相比,时间复杂度不依赖于算法将在其上运行的任何硬件。时间复杂度分析仅取决于算法本身的结构。时间复杂度分析的总体目标是尝试回答以下两个重要问题:
- Will this algorithm scale? A well-designed algorithm should be fully capable of taking advantage of the modern elastic infrastructure available in cloud computing environments. An algorithm should be designed in a way such that it can utilize the availability of more CPUs, processing cores, GPUs, and memory. For example, an algorithm used for training a model in a machine learning problem should be able to use distributed training as more CPUs are available.
这个算法是否具备可扩展性?一个设计良好的算法应该能够充分利用云计算环境中现代弹性基础设施的优势。算法应该以一种能够利用更多 CPU、处理核心、GPU 和内存的方式进行设计。例如,在机器学习问题中用于训练模型的算法应该能够利用分布式训练,因为有更多的 CPU 可用。
Such algorithms should also take advantage of GPUs and additional memory if made available during the execution of the algorithm.
这些算法在执行过程中应充分利用 GPU 和额外的内存(如果可用)。
- How well will this algorithm handle larger datasets?
这个算法能很好地处理更大的数据集吗?
To answer these questions, we need to determine the effect on the performance of an algorithm as the size of the data is increased and make sure that the algorithm is designed in a way that not only makes it accurate but also scales well. The performance of an algorithm is becoming more and more important for larger datasets in today’s world of “big data.”
为了回答这些问题,我们需要确定随着数据规模的增加对算法性能的影响,并确保算法设计不仅使其准确无误,而且具有良好的可扩展性。在当今“大数据”世界中,算法的性能对于更大的数据集变得越来越重要。
In many cases, we may have more than one approach available to design the algorithm. The goal of conducting time complexity analysis, in this case, will be as follows:
在许多情况下,我们可能有多种方法可供设计算法。在这种情况下进行时间复杂度分析的目标将如下:
“Given a certain problem and more than one algorithm, which one is the most efficient to use in terms of time efficiency?”
针对特定问题和多种算法,哪一种在时间效率方面最高效?
There can be two basic approaches to calculating the time complexity of an algorithm:
计算算法时间复杂度有两种基本方法:
- A post-implementation profiling approach: In this approach, different candidate algorithms are implemented, and their performance is compared.
一种实施后的分析方法:在这种方法中,实现了不同的候选算法,并对它们的性能进行比较。 - A pre-implementation theoretical approach: In this approach, the performance of each algorithm is approximated mathematically before running an algorithm.
一个预实施的理论方法:在这种方法中,在运行算法之前,通过数学逼近每个算法的性能。
The advantage of the theoretical approach is that it only depends on the structure of the algorithm itself. It does not depend on the actual hardware that will be used to run the algorithm, the choice of the software stack chosen at runtime, or the programming language used to implement the algorithm.
理论方法的优势在于它仅取决于算法本身的结构。它不依赖于将用于运行算法的实际硬件、运行时选择的软件堆栈或实现算法所使用的编程语言。
Estimating the performance
估算性能
The performance of a typical algorithm will depend on the type of data given to it as an input. For example, if the data is already sorted according to the context of the problem we are trying to solve, the algorithm may perform blazingly fast. If the sorted input is used to benchmark this particular algorithm, then it will give an unrealistically good performance number, which will not be a true reflection of its real performance in most scenarios. To handle this dependency of algorithms on the input data, we have different types of cases to consider when conducting a performance analysis.
典型算法的性能将取决于输入的数据类型。例如,如果数据已根据我们尝试解决的问题的上下文进行了排序,算法可能会执行得非常快。如果已排序的输入用于基准测试特定算法,那么它将提供一个不真实的良好性能数字,这不会真实反映其在大多数情况下的实际性能。为了处理算法对输入数据的依赖性,我们在进行性能分析时需要考虑不同类型的情况。
The best case 最佳案例
In the best case, the data given as input is organized in a way that the algorithm will give its best performance. Best-case analysis gives the upper bound of the performance.
在最理想的情况下,作为输入的数据以一种方式组织,使得算法能够发挥最佳性能。最佳情况分析提供了性能的上限。
The worst case 最坏情况
The second way to estimate the performance of an algorithm is to try to find the maximum possible time it will take to get the job done under a given set of conditions. This worst-case analysis of an algorithm is quite useful as we are guaranteeing that regardless of the conditions, the performance of the algorithm will always be better than the numbers that come out of our analysis. Worst-case analysis is especially useful for estimating the performance when dealing with complex problems with larger datasets. Worst-case analysis gives the lower bound of the performance of the algorithm.
估算算法性能的第二种方法是尝试找到在给定条件下完成工作所需的最长时间。对算法的最坏情况分析非常有用,因为我们保证无论条件如何,算法的性能始终优于我们分析得出的数字。最坏情况分析在处理具有更大数据集的复杂问题时尤为有用。最坏情况分析给出了算法性能的下限。
The average case 平均情况
This starts by dividing the various possible inputs into various groups. Then, it conducts the performance analysis from one of the representative inputs from each group. Finally, it calculates the average of the performance of each of the groups.
这是通过将各种可能的输入分成不同的组开始的。然后,它从每个组中的一个代表性输入进行性能分析。最后,它计算每个组的性能平均值。
Average-case analysis is not always accurate as it needs to consider all the different combinations and possibilities of input to the algorithm, which is not always easy to do.
平均情况分析并不总是准确的,因为它需要考虑算法的所有不同组合和可能性,这并不总是容易的。
Big O notation 大 O 符号
Big O notation was first introduced by Bachmann in 1894 in a research paper to approximate an algorithm’s growth. He wrote:
大 O 符号是由巴赫曼于 1894 年在一篇研究论文中首次引入,用于近似算法的增长。他写道:
“… with the symbol O(n) we express a magnitude whose order in respect to n does not exceed the order of n” (Bachmann 1894, p. 401).
“… 用符号 O(n) 表示一个数量级,其相对于 n 的阶数不超过 n 的阶数”(Bachmann 1894,第 401 页)。
Big-O notation provides a way to describe the long-term growth rate of an algorithm’s performance. In simpler terms, it tells us how the runtime of an algorithm increases as the input size grows. Let’s break it down with the help of two functions, f(n) and g(n). If we say f = O(g), what we mean is that as n approaches infinity, the ratio ![]() stays limited or bounded. In other words, no matter how large our input gets, f(n) will not grow disproportionately faster than g(n).
stays limited or bounded. In other words, no matter how large our input gets, f(n) will not grow disproportionately faster than g(n).
大 O 符号提供了一种描述算法性能长期增长率的方式。简单来说,它告诉我们算法的运行时间随着输入规模增长而增加的方式。让我们通过两个函数 f(n)和 g(n)来解释。如果我们说 f = O(g),这意味着当 n 趋近于无穷大时,比值 ![]() 保持有限或有界。换句话说,无论输入有多大,f(n)的增长速度不会比 g(n)快得多。
保持有限或有界。换句话说,无论输入有多大,f(n)的增长速度不会比 g(n)快得多。
Let’s look at particular functions:
让我们来看看特定的功能:
f(n) = 1000n2 + 100n + 10
and
g(n) = n2
Note that both functions will approach infinity as n approaches infinity. Let’s find out if f = O(g) by applying the definition.
请注意,随着 n 趋近于无穷大,两个函数都会趋近于无穷大。让我们通过应用定义来确定 f = O(g)。
First, let us calculate ![]() ,
,
首先,让我们计算 ![]() ,
,
which will be equal to ![]() =
= ![]() = (1000 +
= (1000 + ![]() ).
).
这将等于 ![]() =
= ![]() = (1000 +
= (1000 + ![]() )。
)。
It is clear that ![]() is bounded and will not approach infinity as n approaches infinity.
is bounded and will not approach infinity as n approaches infinity.
很明显, ![]() 是有界的,并且当 n 趋向无穷大时不会趋近于无穷大。
是有界的,并且当 n 趋向无穷大时不会趋近于无穷大。
Thus f(n) = O(g) = O(n2).
因此 f(n) = O(g) = O(n 2 ).
(n2) represents that the complexity of this function increases as the square of input n. If we double the number of input elements, the complexity is expected to increase by 4.
(n 2 ) 表示此函数的复杂度随输入 n 的平方增加。如果我们将输入元素数量加倍,预计复杂度将增加 4 倍。
Note the following 4 rules when dealing with Big-O notation.
处理大 O 符号时,请注意以下 4 条规则。
Rule 1: 规则 1:
Let us look into the complexity of loops in algorithms. If an algorithm performs a certain sequence of steps n times, then it has O(n) performance.
让我们来看算法中循环的复杂性。如果一个算法执行一系列步骤 n 次,那么它的性能为 O(n)。
Rule 2: 规则 2:
Let us look into the nested loops of the algorithms. If an algorithm performs a function that has a loop of n1 steps, and for each loop it performs another n2 steps, the algorithm’s total performance is O(n1 × n2).
让我们来看看算法中的嵌套循环。如果一个算法执行一个包含 n 1 步的循环的函数,并且对于每个循环它执行另外 n 2 步,那么算法的总性能为 O(n 1 × n 2 )。
For example, if an algorithm has both outer and inner loops having n steps, then the complexity of the algorithm will be represented by:
例如,如果一个算法同时具有外部和内部循环,每个循环有 n 个步骤,那么该算法的复杂度将表示为:
O(n*n) = O(n2)
Rule 3: 规则 3:
If an algorithm performs a function f(n) that takes n1 steps and then performs another function g(n) that takes n2 steps, the algorithm’s total performance is O(f(n)+g(n)).
如果一个算法执行一个函数 f(n),需要 n 1 步,然后执行另一个函数 g(n),需要 n 2 步,那么算法的总性能是 O(f(n)+g(n))。
Rule 4: 规则 4:
If an algorithm takes O(g(n) + h(n)) and the function g(n) is greater than h(n) for large n, the algorithm’s performance can be simplified to O(g(n)).
如果一个算法的时间复杂度为 O(g(n) + h(n)),且对于大的 n,函数 g(n) 大于 h(n),那么该算法的性能可以简化为 O(g(n))。
It means that O(1+n) = O(n).
这意味着 O(1+n) = O(n)。
And O(n2+ n3) = O(n2).
而 O(n 2 + n 3 ) = O(n 2 )。
Rule 5: 规则 5:
When calculating the complexity of an algorithm, ignore constant multiples. If k is a constant, O(kf(n)) is the same as O(f(n)).
在计算算法复杂度时,忽略常数倍数。如果 k 是一个常数,O(kf(n)) 和 O(f(n)) 是相同的。
Also, O(f(k × n)) is the same as O(f(n)).
同时,O(f(k × n)) 等同于 O(f(n))。
Thus O(5n2) = O(n2).
因此 O(5n 2 ) = O(n 2 ).
And O((3n2)) = O(n2).
而 O((3n 2 )) = O(n 2 ).
Note that: 请注意:
- The complexity quantified by Big O notation is only an estimate.
Big O 符号表示的复杂度仅仅是一个估计。 - For smaller sizes of data, we do not care about the time complexity. n0 in the graph defines the threshold above which we are interested in finding the time complexity. The shaded area describes this area of interest where we will analyze the time complexity.
对于较小的数据大小,我们不关心时间复杂度。图中的 n 0 定义了我们感兴趣的时间复杂度查找阈值。阴影区域描述了我们将分析时间复杂度的这一兴趣区域。 - T(n) time complexity is more than the original function. A good choice of T(n) will try to create a tight upper bound for F(n).
T(n)时间复杂度高于原始函数。选择良好的 T(n)将尝试为 F(n)创建一个紧密的上界。
The following table summarizes the different kinds of Big O notation types discussed in this section:
以下表格总结了本节讨论的不同类型的大 O 符号表示法:
|
Complexity Class 复杂度类 |
Name |
Example Operations 示例操作 |
|
|
Constant |
Append, get item, set item. |
|
|
Logarithmic |
Finding an element in a sorted array. |
|
|
Linear |
Copy, insert, delete, iteration |
|
|
Quadratic |
Nested loops 嵌套循环 |
Constant time (O(1)) complexity
常数时间(O(1))复杂度
If an algorithm takes the same amount of time to run, independent of the size of the input data, it is said to run in constant time. It is represented by O(1). Let’s take the example of accessing the nth element of an array. Regardless of the size of the array, it will take constant time to get the results. For example, the following function will return the first element of the array and has a complexity of O(1):
如果算法运行所需的时间不受输入数据大小的影响,则称其为常数时间运行。它用 O(1)表示。让我们以访问数组的第 n th 元素为例。无论数组的大小如何,获取结果都将花费恒定的时间。例如,以下函数将返回数组的第一个元素,并具有 O(1)的复杂度:
Note that: 请注意:
- The addition of a new element to a stack is done by using
pushand removing an element from a stack is done by usingpop. Regardless of the size of the stack, it will take the same time to add or remove an element.
通过使用push将新元素添加到堆栈中,通过使用pop将元素从堆栈中移除。无论堆栈的大小如何,添加或移除元素所需的时间都是相同的。 - When accessing the element of the hashtable, note that it is a data structure that stores data in an associative format, usually as key-value pairs.
访问哈希表的元素时,请注意它是一种数据结构,通常以键-值对的形式存储数据。
Linear time (O(n)) complexity
线性时间(O(n))复杂度
An algorithm is said to have a complexity of linear time, represented by O(n), if the execution time is directly proportional to the size of the input. A simple example is to add the elements in a single-dimensional data structure:
如果执行时间与输入大小成正比,则称算法具有线性时间复杂度,表示为 O(n)。一个简单的例子是对单维数据结构中的元素进行相加:
Note the main loop of the algorithm. The number of iterations in the main loop increases linearly with an increasing value of n, producing an O(n) complexity in the following figure:
请注意算法的主循环。主循环中的迭代次数随着 n 值的增加而线性增加,在下图中产生 O(n) 复杂度。
Some other examples of array operations are as follows:
一些数组操作的其他示例如下:
- Searching an element 搜索一个元素
- Finding the minimum value among all the elements of an array
在数组的所有元素中找到最小值
Quadratic time (O(n2)) complexity
二次时间(O(n2))复杂度
An algorithm is said to run in quadratic time if the execution time of an algorithm is proportional to the square of the input size; for example, a simple function that sums up a two-dimensional array, as follows:
如果算法的执行时间与输入规模的平方成正比,则称该算法运行在二次时间内;例如,一个简单的函数,用于计算二维数组的总和,如下所示:
Note the nested inner loop within the other main loop. This nested loop gives the preceding code the complexity of O(n2):
请注意在另一个主循环内部嵌套的内部循环。这个嵌套循环使前面的代码具有 O(n 2 )的复杂度。
Another example is the bubble sort algorithm (which will be discussed in Chapter 2, Data Structures Used in Algorithms).
另一个例子是冒泡排序算法(将在第 2 章《算法中使用的数据结构》中讨论)。
Logarithmic time (O(logn)) complexity
对数时间(O(logn))复杂度
An algorithm is said to run in logarithmic time if the execution time of the algorithm is proportional to the logarithm of the input size. With each iteration, the input size decreases by constant multiple factors. An example of a logarithmic algorithm is binary search. The binary search algorithm is used to find a particular element in a one-dimensional data structure, such as a Python list. The elements within the data structure need to be sorted in descending order. The binary search algorithm is implemented in a function named search_binary, as follows:
如果算法的执行时间与输入规模的对数成比例,则称该算法在对数时间内运行。每次迭代,输入规模都会以恒定倍数因子减少。对数算法的一个示例是二分查找。二分查找算法用于在一维数据结构(如 Python 列表)中查找特定元素。数据结构中的元素需要按降序排序。二分查找算法实现在名为 search_binary 的函数中,如下所示:
The main loop takes advantage of the fact that the list is ordered. It divides the list in half with each iteration until it gets to the result.
主循环利用列表有序的特点。每次迭代将列表分成两半,直到得出结果。
After defining the function, it is tested to search a particular element in lines 11 and 12. The binary search algorithm is further discussed in Chapter 3, Sorting and Searching Algorithms.
定义了函数后,将对在第 11 行和第 12 行搜索特定元素进行测试。二分搜索算法将在第 3 章“排序和搜索算法”中进一步讨论。
Note that among the four types of Big O notation types presented, O(n2) has the worst performance and O(logn) has the best performance. On the other hand, O(n2) is not as bad as O(n3), but still, algorithms that fall in this class cannot be used on big data as the time complexity puts limitations on how much data they can realistically process. The performance of four types of Big O notations is shown in Figure 1.3:
请注意,在所提供的四种大 O 符号类型中,O(n 2 )性能最差,而 O(logn)性能最佳。另一方面,O(n 2 )不像 O(n 3 )那样糟糕,但仍然,属于这一类别的算法不能用于大数据,因为时间复杂度限制了它们能够实际处理的数据量。四种大 O 符号类型的性能如图 1.3 所示:
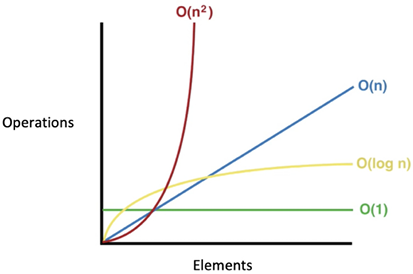
Figure 1.3: Big O complexity chart
图 1.3:大 O 复杂度图表
One way to reduce the complexity of an algorithm is to compromise on its accuracy, producing a type of algorithm called an approximate algorithm.
减少算法复杂性的一种方法是在准确性上做出妥协,从而产生一种称为近似算法的算法类型。
Selecting an algorithm 选择算法
How do you know which one is a better solution? How do you know which algorithm runs faster? Analyzing the time complexity of an algorithm may answer these types of questions.
你如何知道哪一个是更好的解决方案?你如何知道哪个算法运行得更快?分析算法的时间复杂度可能会回答这些问题。
To see where it can be useful, let’s take a simple example where the objective is to sort a list of numbers. There are a bunch of algorithms readily available that can do the job. The issue is how to choose the right one.
为了看到它在哪里可以派上用场,让我们举一个简单的例子,目标是对一组数字进行排序。有许多现成的算法可以完成这项工作。问题在于如何选择合适的算法。
First, an observation that can be made is that if there are not too many numbers in the list, then it does not matter which algorithm we choose to sort the list of numbers. So, if there are only 10 numbers in the list (n=10), then it does not matter which algorithm we choose as it would probably not take more than a few microseconds, even with a very simple algorithm. But as n increases, the choice of the right algorithm starts to make a difference. A poorly designed algorithm may take a couple of hours to run, while a well-designed algorithm may finish sorting the list in a couple of seconds. So, for larger input datasets, it makes a lot of sense to invest time and effort, perform a performance analysis, and choose the correctly designed algorithm that will do the job required in an efficient manner.
首先,可以观察到的一点是,如果列表中的数字不太多,那么选择哪种算法来对数字列表进行排序就无关紧要。因此,如果列表中只有 10 个数字(n=10),那么选择哪种算法都无关紧要,因为即使使用非常简单的算法,也不太可能花费超过几微秒的时间。但是随着 n 的增加,选择正确的算法开始变得重要起来。一个设计不良的算法可能需要几个小时才能运行完毕,而一个设计良好的算法可能只需要几秒钟就能完成对列表的排序。因此,对于更大的输入数据集,投入时间和精力进行性能分析,并选择正确设计的算法以高效地完成所需工作是非常有意义的。
Validating an algorithm 验证算法
Validating an algorithm confirms that it is actually providing a mathematical solution to the problem we are trying to solve. A validation process should check the results for as many possible values and types of input values as possible.
验证算法确认它实际上为我们试图解决的问题提供了数学解决方案。验证过程应检查尽可能多的可能值和输入值类型的结果。
Exact, approximate, and randomized algorithms
精确、近似和随机算法
Validating an algorithm also depends on the type of the algorithm as the testing techniques are different. Let’s first differentiate between deterministic and randomized algorithms.
验证算法的有效性还取决于算法的类型,因为测试技术是不同的。让我们首先区分确定性算法和随机算法。
For deterministic algorithms, a particular input always generates exactly the same output. But for certain classes of algorithms, a sequence of random numbers is also taken as input, which makes the output different each time the algorithm is run. The k-means clustering algorithm, which is detailed in Chapter 6, Unsupervised Machine Learning Algorithms, is an example of such an algorithm:
对于确定性算法,特定的输入总是产生完全相同的输出。但对于某些类别的算法,随机数序列也被视为输入,这使得每次运行算法时输出都不同。k 均值聚类算法是这样一种算法的例子,详见第 6 章《无监督机器学习算法》。
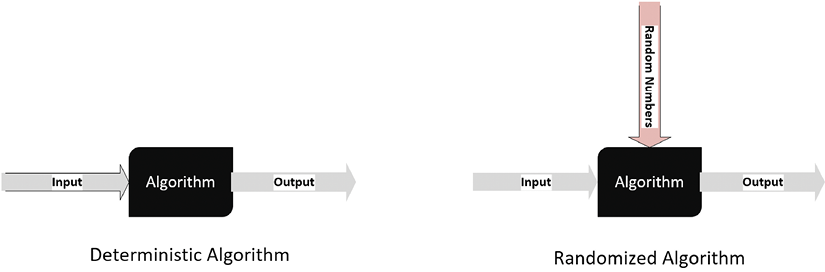
Figure 1.4: Deterministic and Randomized Algorithms
图 1.4:确定性和随机算法
Algorithms can also be divided into the following two types based on assumptions or approximation used to simplify the logic to make them run faster:
算法也可以根据用于简化逻辑以使其运行更快的假设或近似分为以下两种类型:
- An exact algorithm: Exact algorithms are expected to produce a precise solution without introducing any assumptions or approximations.
一个精确算法:精确算法预期能够在不引入任何假设或近似的情况下产生精确解决方案。 - An approximate algorithm: When the problem complexity is too much to handle for the given resources, we simplify our problem by making some assumptions. The algorithms based on these simplifications or assumptions are called approximate algorithms, which don’t quite give us the precise solution.
一个近似算法:当问题复杂度超出给定资源的处理能力时,我们通过做一些假设来简化问题。基于这些简化或假设的算法被称为近似算法,它们并不能给出精确解决方案。
Let’s look at an example to understand the difference between exact and approximate algorithms—the famous traveling salesman problem, which was presented in 1930. Traveling salesman challenges you to find the shortest route for a particular salesman that visits each city (from a list of cities) and then returns to the origin, which is why he is named the traveling salesman. The first attempt to provide the solution will include generating all the permutations of cities and choosing the combination of cities that is cheapest. It is obvious that time complexity starts to become unmanageable beyond 30 cities.
让我们通过一个例子来理解精确算法和近似算法之间的区别——著名的旅行推销员问题,该问题于 1930 年提出。旅行推销员问题挑战您找到一位特定推销员访问每个城市(从城市列表中)并返回原点的最短路径,这也是他被称为旅行推销员的原因。首次尝试解决方案将包括生成所有城市的排列组合,并选择最便宜的城市组合。显然,随着城市数量超过 30 个,时间复杂度开始变得难以管理。
If the number of cities is more than 30, one way of reducing the complexity is to introduce some approximations and assumptions.
如果城市数量超过 30 个,减少复杂性的一种方法是引入一些近似值和假设。
For approximate algorithms, it is important to set the expectations for accuracy when gathering the requirements. Validating an approximation algorithm is about verifying that the error of the results is within an acceptable range.
对于近似算法,设定准确性期望在收集需求时非常重要。验证近似算法是为了确认结果的误差在可接受范围内。
Explainability 可解释性
When algorithms are used for critical cases, it becomes important to have the ability to explain the reason behind each and every result whenever needed. This is necessary to make sure that decisions based on the results of the algorithms do not introduce bias.
当算法用于关键案例时,有必要能够随时解释每个结果背后的原因。这是为了确保基于算法结果的决策不会引入偏见。
The ability to exactly identify the features that are used directly or indirectly to come up with a particular decision is called the explainability of an algorithm. Algorithms, when used for critical use cases, need to be evaluated for bias and prejudice. The ethical analysis of algorithms has become a standard part of the validation process for those algorithms that can affect decision-making that relates to the lives of people.
准确识别直接或间接用于做出特定决策的特征的能力被称为算法的可解释性。当算法用于关键用例时,需要评估其是否存在偏见和偏见。对算法的伦理分析已成为验证过程的标准部分,适用于那些可能影响与人们生活相关的决策的算法。
For algorithms that deal with deep learning, explainability is difficult to achieve. For example, if an algorithm is used to refuse the mortgage application of a person, it is important to have the transparency and ability to explain the reason.
对于处理深度学习的算法来说,可解释性很难实现。例如,如果一个算法被用来拒绝某人的抵押贷款申请,具有透明度和解释原因的能力就显得尤为重要。
Algorithmic explainability is an active area of research. One of the effective techniques that have been recently developed is Local Interpretable Model-Agnostic Explanations (LIME), as proposed in the proceedings of the 22nd Association for Computing Machinery (ACM) at the Special Interest Group on Knowledge Discovery and Data Mining (SIGKDD) international conference on knowledge discovery and data mining in 2016. LIME is based on a concept where small changes are introduced to the input for each instance and then an effort to map the local decision boundary for that instance is made. It can then quantify the influence of each variable for that instance.
算法可解释性是一个活跃的研究领域。最近开发的有效技术之一是局部可解释模型无关解释(LIME),该技术是在 2016 年在计算机协会(ACM)第 22 届知识发现与数据挖掘专业兴趣小组(SIGKDD)国际会议的论文中提出的。LIME 基于一个概念,即为每个实例引入小的变化,然后努力绘制该实例的局部决策边界。然后可以量化每个变量对该实例的影响。
Summary 摘要
This chapter was about learning the basics of algorithms. First, we learned about the different phases of developing an algorithm. We discussed the different ways of specifying the logic of an algorithm that are necessary for designing it. Then, we looked at how to design an algorithm. We learned two different ways of analyzing the performance of an algorithm. Finally, we studied different aspects of validating an algorithm.
本章是关于学习算法基础知识的。首先,我们学习了算法开发的不同阶段。我们讨论了指定算法逻辑的不同方式,这对于设计算法是必要的。然后,我们看了如何设计算法。我们学习了分析算法性能的两种不同方式。最后,我们研究了验证算法的不同方面。
After going through this chapter, we should be able to understand the pseudocode of an algorithm. We should understand the different phases in developing and deploying an algorithm. We also learned how to use Big O notation to evaluate the performance of an algorithm.
经过阅读本章,我们应该能够理解算法的伪代码。我们应该了解开发和部署算法的不同阶段。我们还学会了如何使用大 O 符号来评估算法的性能。
The next chapter is about the data structures used in algorithms. We will start by looking at the data structures available in Python. We will then look at how we can use these data structures to create more sophisticated data structures, such as stacks, queues, and trees, which are needed to develop complex algorithms.
下一章是关于算法中使用的数据结构。我们将首先看一下 Python 中可用的数据结构。然后我们将看一下如何使用这些数据结构来创建更复杂的数据结构,比如栈、队列和树,这些数据结构是开发复杂算法所需的。
Learn more on Discord
在 Discord 上了解更多
To join the Discord community for this book – where you can share feedback, ask questions to the author, and learn about new releases – follow the QR code below:
要加入这本书的 Discord 社区 - 在那里您可以分享反馈,向作者提问,并了解新发布的内容 - 请扫描下方的二维码:
