Deep RL Course documentation
Introducing Q-Learning
Deep RL Course 深度强化学习课程
Introducing Q-Learning 介绍 Q 学习
What is Q-Learning? 什么是 Q 学习?
Q-Learning is an off-policy value-based method that uses a TD approach to train its action-value function:
Q-学习是一种基于价值、使用时序差分方法的离策略方法,用于训练其动作价值函数:
- Off-policy: we’ll talk about that at the end of this unit.
离策略:我们将在本单元末尾讨论这一点。 - Value-based method: finds the optimal policy indirectly by training a value or action-value function that will tell us the value of each state or each state-action pair.
基于价值的方法:通过训练一个价值或动作价值函数间接找到最优策略,该函数将告诉我们每个状态或每个状态-动作对的价值。 - TD approach: updates its action-value function at each step instead of at the end of the episode.
TD 方法: 在每一步更新其动作价值函数,而不是在情节结束时更新。
Q-Learning is the algorithm we use to train our Q-function, an action-value function that determines the value of being at a particular state and taking a specific action at that state.
Q-学习是我们用于训练 Q 函数的算法,一个动作价值函数,它决定了在特定状态下采取某一动作的价值。
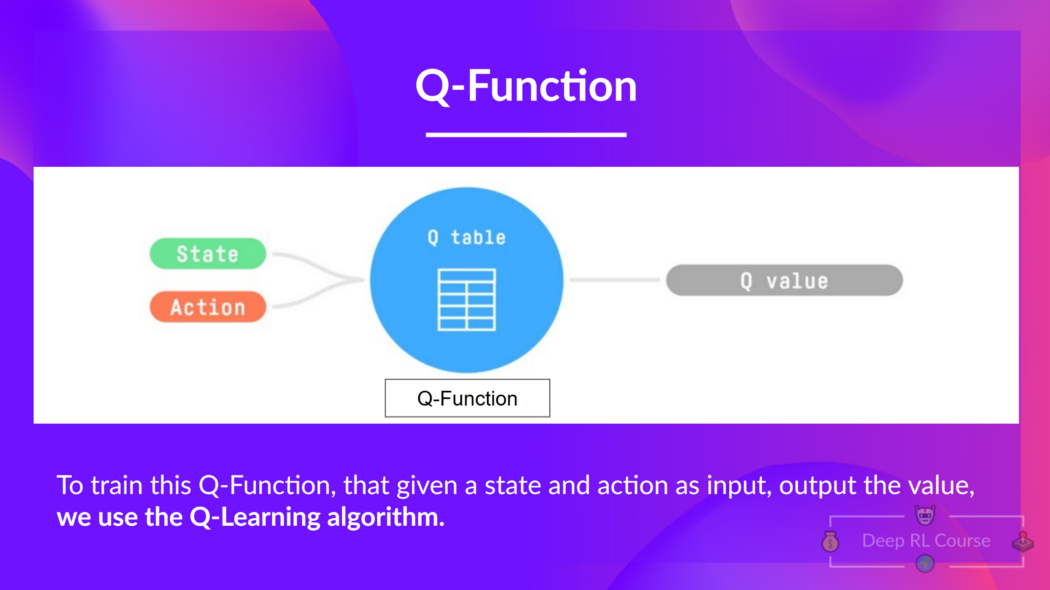
给定一个状态和动作,我们的 Q 函数输出一个状态-动作值(也称为 Q 值)
The Q comes from “the Quality” (the value) of that action at that state.
Q 来源于“该状态下的动作质量”(即价值)。
Let’s recap the difference between value and reward:
让我们回顾一下价值与奖励之间的区别:
- The value of a state, or a state-action pair is the expected cumulative reward our agent gets if it starts at this state (or state-action pair) and then acts accordingly to its policy.
状态的价值,或一个状态-动作对的价值,是指如果我们的agent从这个状态(或状态-动作对)开始,并根据其策略采取行动,预期能获得的累积奖励。 - The reward is the feedback I get from the environment after performing an action at a state.
奖励是在某个状态下执行动作后从环境中获得的反馈。
Internally, our Q-function is encoded by a Q-table, a table where each cell corresponds to a state-action pair value. Think of this Q-table as the memory or cheat sheet of our Q-function.
内部,我们的 Q 函数由一个 Q 表编码,该表中每个单元格对应一个状态-动作对值。可以将这个 Q 表视为我们 Q 函数的记忆或作弊小抄。
Let’s go through an example of a maze.
让我们通过一个迷宫的例子来了解。

The Q-table is initialized. That’s why all values are = 0. This table contains, for each state and action, the corresponding state-action values.
For this simple example, the state is only defined by the position of the mouse. Therefore, we have 2*3 rows in our Q-table, one row for each possible position of the mouse. In more complex scenarios, the state could contain more information than the position of the actor.
Q 表已初始化,因此所有值均为 0。该表针对每个状态和动作,包含了相应的动作-状态值。在这个简单的例子中,状态仅由老鼠的位置定义。因此,我们的 Q 表中有 2*3 行,每行对应老鼠的一个可能位置。在更复杂的场景中,状态可能包含比角色位置更多的信息。

Here we see that the state-action value of the initial state and going up is 0:
在这里我们可以看到,初始状态并选择向上动作的状态-动作值为 0:

So: the Q-function uses a Q-table that has the value of each state-action pair. Given a state and action, our Q-function will search inside its Q-table to output the value.
因此:Q 函数使用一个 Q 表其中包含每个状态-动作对的值。给定一个状态和动作,我们的 Q 函数将在其 Q 表中搜索以输出该值。
If we recap, Q-Learning is the RL algorithm that:
如果我们回顾一下,Q-Learning 是强化学习算法中的一种,它:
- Trains a Q-function (an action-value function), which internally is a Q-table that contains all the state-action pair values.
训练一个Q 函数(一个动作价值函数),其内部是一个包含所有状态-动作对值的 Q 表。 - Given a state and action, our Q-function will search its Q-table for the corresponding value.
给定一个状态和动作,我们的 Q 函数将在其 Q 表中查找相应的值。 - When the training is done, we have an optimal Q-function, which means we have optimal Q-table.
当训练完成后,我们得到了一个最优的 Q 函数,这意味着我们拥有了一个最优的 Q 表。 - And if we have an optimal Q-function, we have an optimal policy since we know the best action to take at each state.
如果我们拥有一个最优的 Q 函数,我们就拥有了一个最优策略,因为我们知道在每个状态下应采取的最佳行动。

In the beginning, our Q-table is useless since it gives arbitrary values for each state-action pair (most of the time, we initialize the Q-table to 0). As the agent explores the environment and we update the Q-table, it will give us a better and better approximation to the optimal policy.
起初,我们的 Q 表并无实际作用,因为它对每个状态-动作对赋予了任意值(多数情况下,我们会将 Q 表初始化为 0)。随着agent探索环境并更新 Q 表,它将为我们提供越来越接近最优策略的近似值。

我们在此看到,随着训练的进行,我们的 Q 表变得更优,因为它使我们能够了解每个状态-动作对的价值。
Now that we understand what Q-Learning, Q-functions, and Q-tables are, let’s dive deeper into the Q-Learning algorithm.
既然我们已经了解了什么是 Q-学习、Q 函数和 Q 表,让我们深入探讨 Q-学习算法。
The Q-Learning algorithm Q-学习算法
This is the Q-Learning pseudocode; let’s study each part and see how it works with a simple example before implementing it. Don’t be intimidated by it, it’s simpler than it looks! We’ll go over each step.
这是 Q-Learning 的伪代码;让我们逐部分研究,并在实施之前通过一个简单示例了解其工作原理。不要被它吓到,它比看起来简单!我们将逐一讲解每一步。

Step 1: We initialize the Q-table
第一步:我们初始化 Q 表

We need to initialize the Q-table for each state-action pair. Most of the time, we initialize with values of 0.
我们需要为每个状态-动作对初始化 Q 表。大多数情况下,我们用 0 值进行初始化。
Step 2: Choose an action using the epsilon-greedy strategy
步骤 2:使用ε-贪心策略选择一个动作
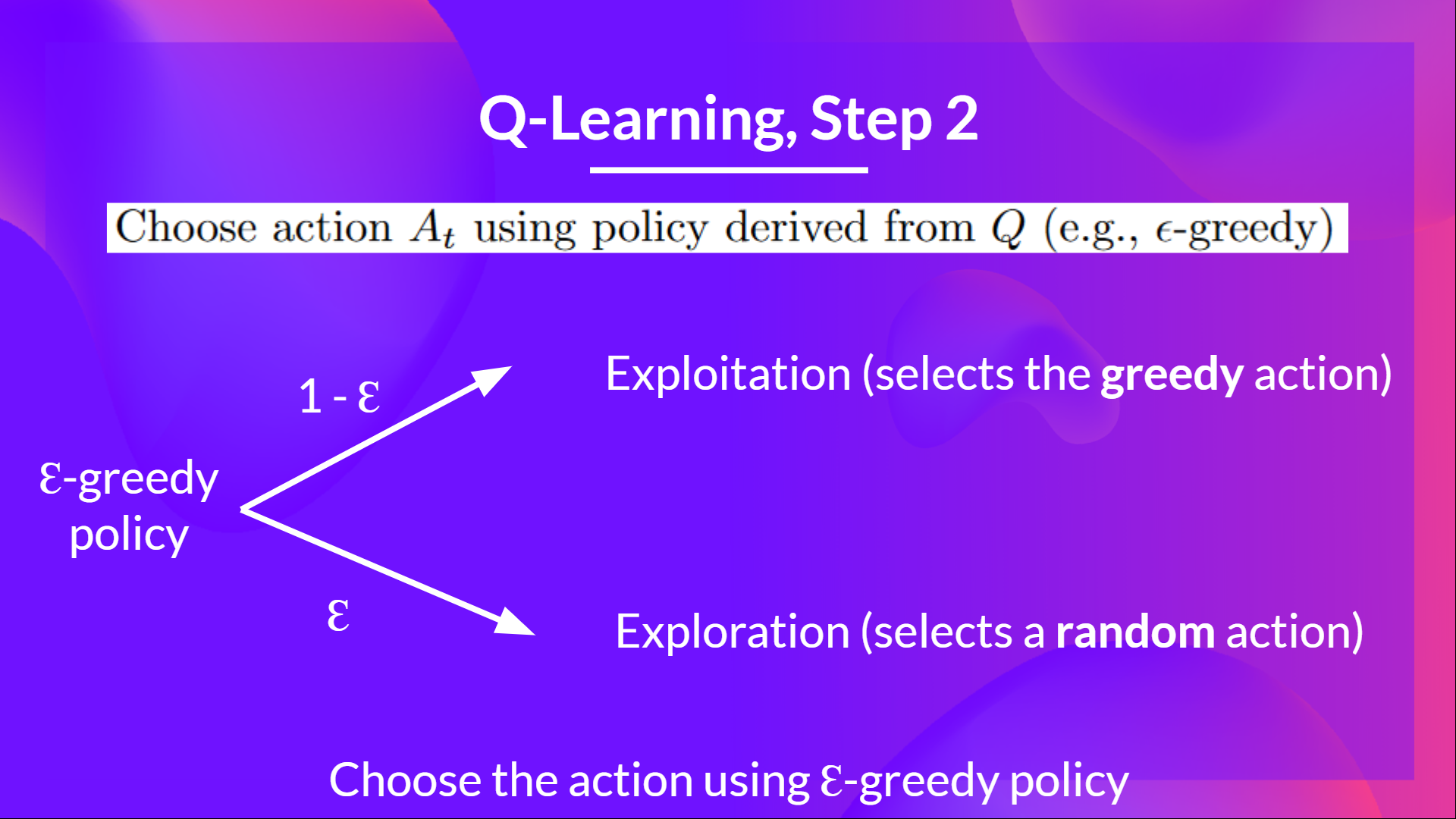
The epsilon-greedy strategy is a policy that handles the exploration/exploitation trade-off.
epsilon-greedy 策略是一种处理探索/利用权衡的策略。
The idea is that, with an initial value of ɛ = 1.0:
这个想法是,以初始值ɛ = 1.0 开始:
- With probability 1 — ɛ : we do exploitation (aka our agent selects the action with the highest state-action pair value).
以概率 1 — ɛ:我们进行利用(即我们的 agent 选择具有最高状态-动作对值的动作)。 - With probability ɛ: we do exploration (trying random action).
以概率ɛ:我们进行探索(尝试随机动作)。
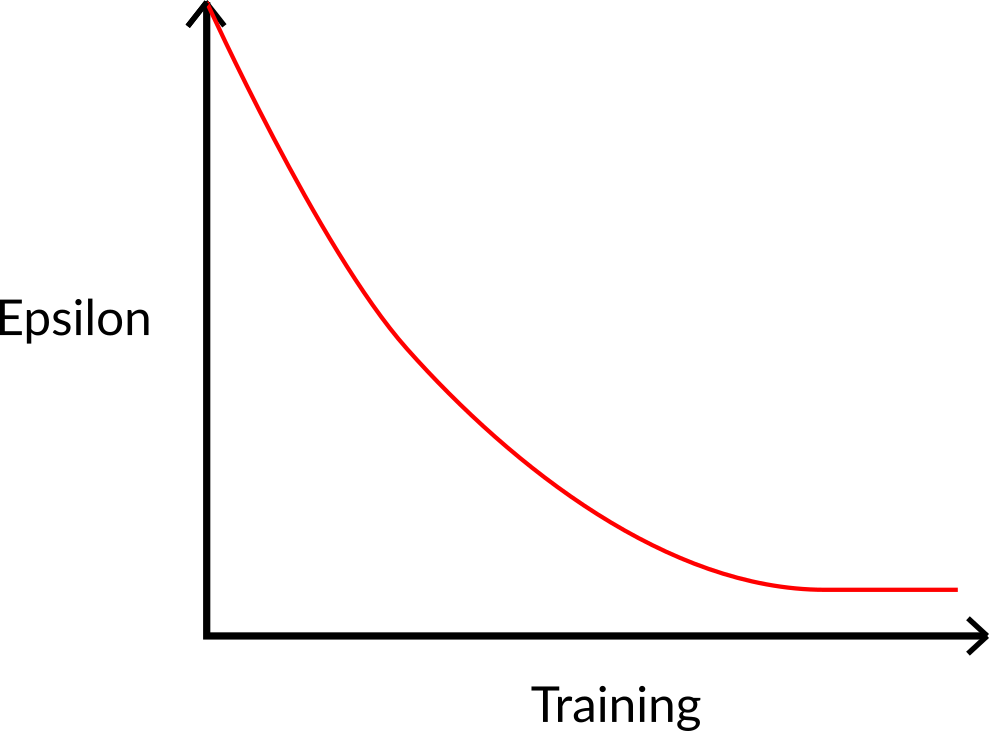
At the beginning of the training, the probability of doing exploration will be huge since ɛ is very high, so most of the time, we’ll explore. But as the training goes on, and consequently our Q-table gets better and better in its estimations, we progressively reduce the epsilon value since we will need less and less exploration and more exploitation.
在训练初期,由于ɛ值非常高,进行探索的概率会非常大,因此大部分时间我们都在探索。但随着训练的进行,我们的Q 表在估计上越来越精确,我们会逐步降低ε值,因为我们需要的探索越来越少,而更多地依赖于利用。
Step 3: Perform action At, get reward Rt+1 and next state St+1
步骤 3:执行动作 At,获得奖励 Rt+1 和下一状态 St+1

Step 4: Update Q(St, At)
步骤 4:更新 Q(St, At)
Remember that in TD Learning, we update our policy or value function (depending on the RL method we choose) after one step of the interaction.
记住,在 TD 学习中,我们根据所选的强化学习方法,在每次交互的一步之后更新我们的策略或价值函数。
To produce our TD target, we used the immediate reward plus the discounted value of the next state, computed by finding the action that maximizes the current Q-function at the next state. (We call that bootstrap).
为了生成我们的 TD 目标,我们采用了即时奖励 加上下一状态的折现值,这一计算过程是通过在下一状态找到使当前 Q 函数最大化的动作来实现的。(我们称之为自举法)。
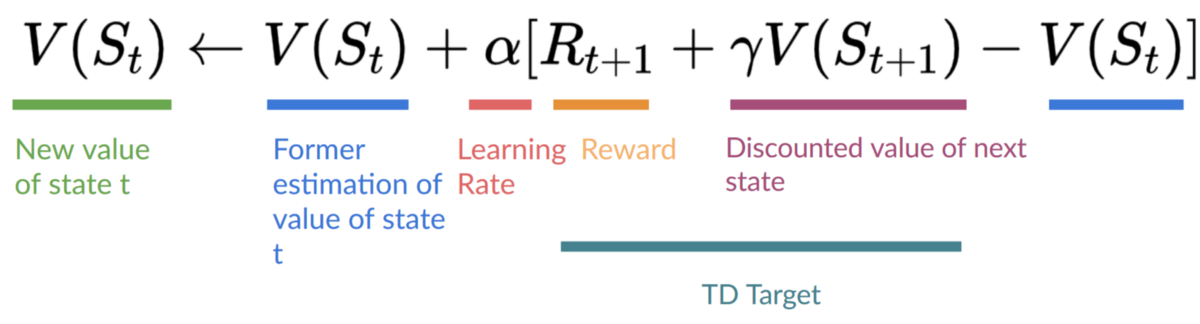
Therefore, our update formula goes like this:
因此,我们的 更新公式如下:
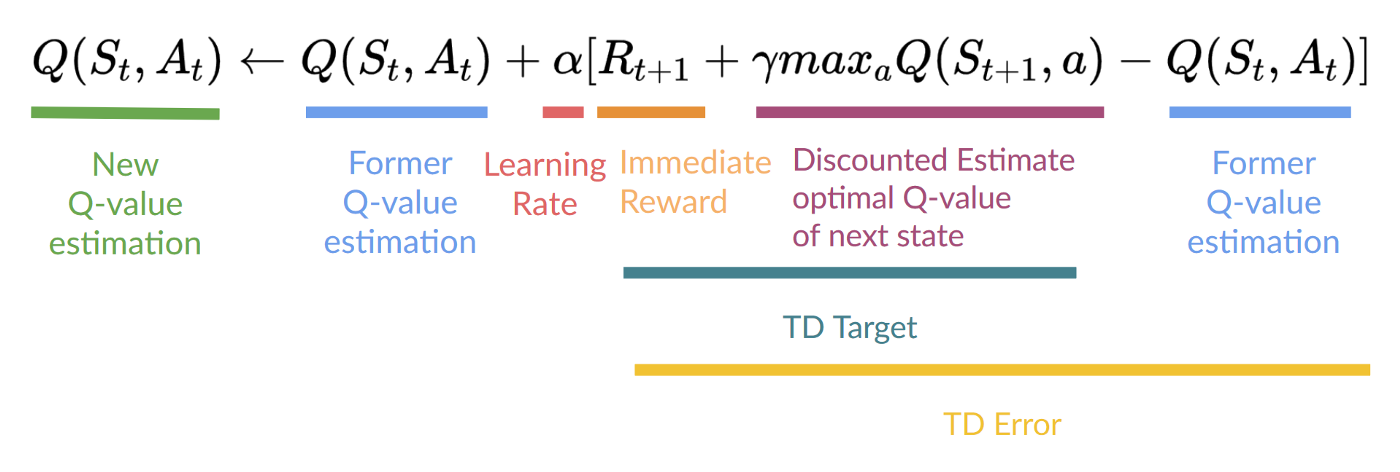
This means that to update our:
这意味着要更新我们的 :
- We need. 我们需要 。
- To update our Q-value at a given state-action pair, we use the TD target.
为了更新给定状态-动作对的 Q 值,我们使用 TD 目标。
How do we form the TD target?
我们如何形成 TD 目标?
- We obtain the reward after taking the action.
我们在采取行动 后获得奖励 。 - To get the best state-action pair value for the next state, we use a greedy policy to select the next best action. Note that this is not an epsilon-greedy policy, this will always take the action with the highest state-action value.
为了获取下一个状态的最佳状态-动作对值,我们采用贪婪策略来选择下一个最佳动作。请注意,这不是ε-贪婪策略,它将始终选择具有最高状态-动作值的动作。
Then when the update of this Q-value is done, we start in a new state and select our action using a epsilon-greedy policy again.
然后,当这个 Q 值的更新完成后,我们从新的状态开始,并再次使用 epsilon-贪心策略选择我们的行动。
This is why we say that Q Learning is an off-policy algorithm.
这就是我们称 Q 学习为离策略算法的原因。
Off-policy vs On-policy 离策略 vs 在策略
The difference is subtle:
差异微妙:
- Off-policy: using a different policy for acting (inference) and updating (training).
离策略:使用不同的策略进行行动(推理)和更新(训练)。
For instance, with Q-Learning, the epsilon-greedy policy (acting policy), is different from the greedy policy that is used to select the best next-state action value to update our Q-value (updating policy).
例如,在使用 Q-学习时,ε-贪心策略(行动策略)与用于选择最佳下一状态动作值以更新我们的 Q 值(更新策略)的贪心策略不同。
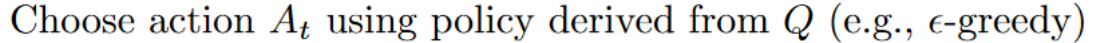
Is different from the policy we use during the training part:
与我们在训练部分使用的策略不同:
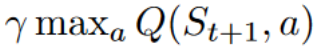
- On-policy: using the same policy for acting and updating.
同策略:使用相同的策略进行行为和更新。
For instance, with Sarsa, another value-based algorithm, the epsilon-greedy policy selects the next state-action pair, not a greedy policy.
例如,使用 Sarsa 这一基于价值的算法,epsilon-贪心策略会选择下一个状态-动作对,而非贪心策略。


更新在 GitHub 上