
关键链接
自我-RAG 和 CRAG 的食谱- 视频
动机
因为大多数LLMs只会在大型公共数据集上进行周期性训练,所以他们缺乏最新信息和/或无法用于训练的私有数据。检索增强生成(RAG)是开发LLM应用的主要范式,通过将LLMs连接到外部数据源来解决这个问题(参见我们的视频系列和博客文章)。基本的 RAG 流水线包括嵌入用户查询、检索与查询相关的文档,然后将文档传递给LLM以根据检索到的上下文生成答案。
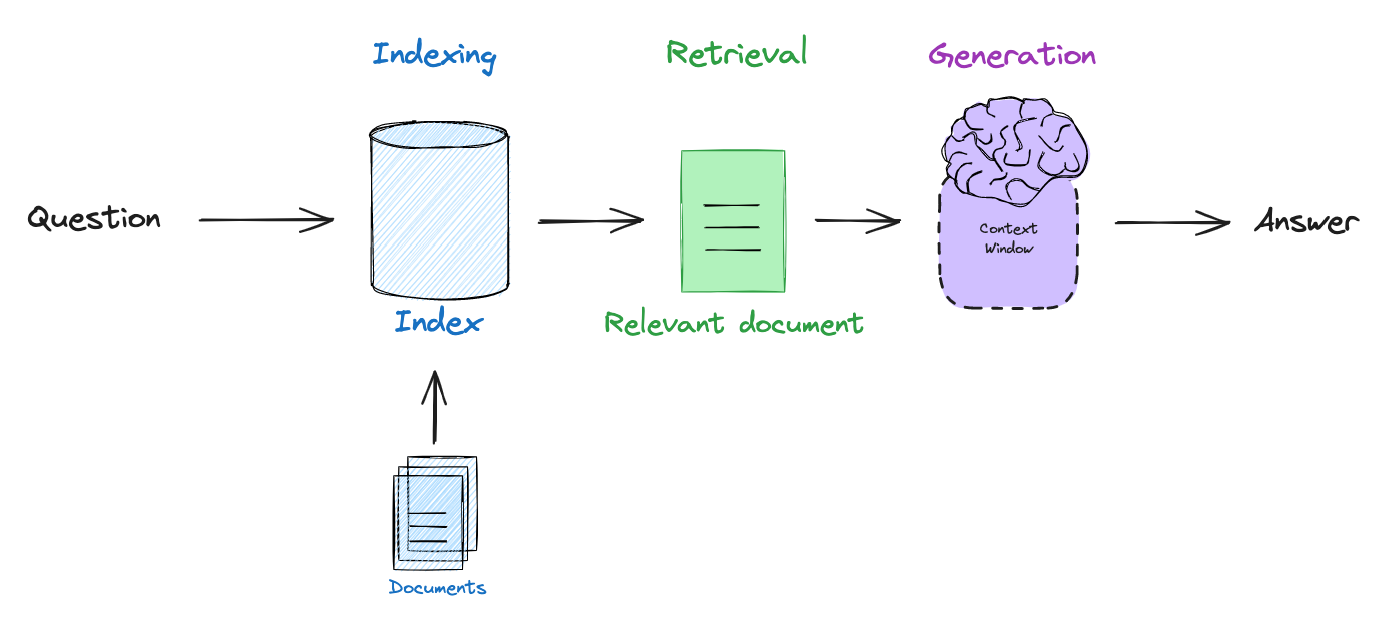
自我反思式 RAG
实际上,许多人发现实施 RAG 需要围绕这些步骤进行逻辑推理:例如,我们可以在何时检索(根据问题和索引的组成),何时重写问题以进行更好的检索,或何时丢弃无关的检索文档并重新尝试检索?提出了自我反思的 RAG(论文)一词,它捕捉到使用LLM自我纠正低质量检索和/或生成的概念。
基本的 RAG 流程(如上所示)只是使用一个链:LLM根据检索到的文档确定要生成什么。一些 RAG 流程使用路由,其中LLM根据问题在不同的检索器之间进行选择。但自省式 RAG 通常需要某种形式的反馈,重新生成问题和/或重新检索文档。状态机是支持循环的第三种认知架构,非常适合于此:状态机只需让我们定义一系列步骤(例如,检索、评估文档、重写查询)并设置它们之间的转换选项;例如,如果我们的检索到的文档不相关,则重写查询并重新检索新文档。
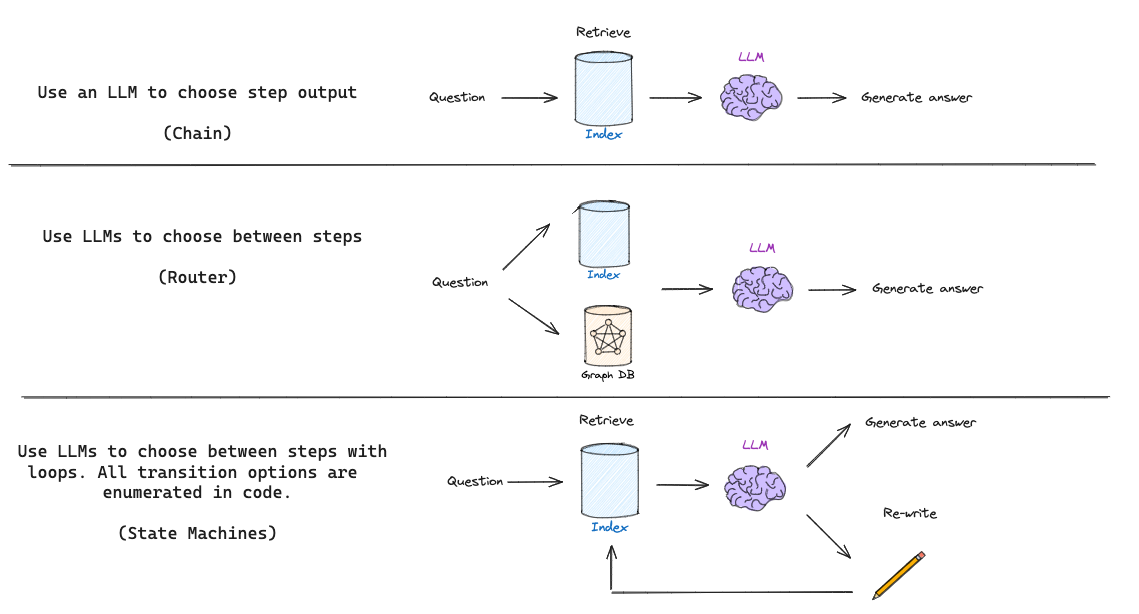
RAG 的认知架构
使用 LangGraph 的自省式 RAG
我们最近推出了 LangGraph,这是一种实现LLM状态机的简单方法。这为 RAG 流程的布局提供了很大的灵活性,并支持了针对 RAG 的具体决策点(例如,文档评分)和循环(例如,重试检索)的更通用的“流程工程”过程。
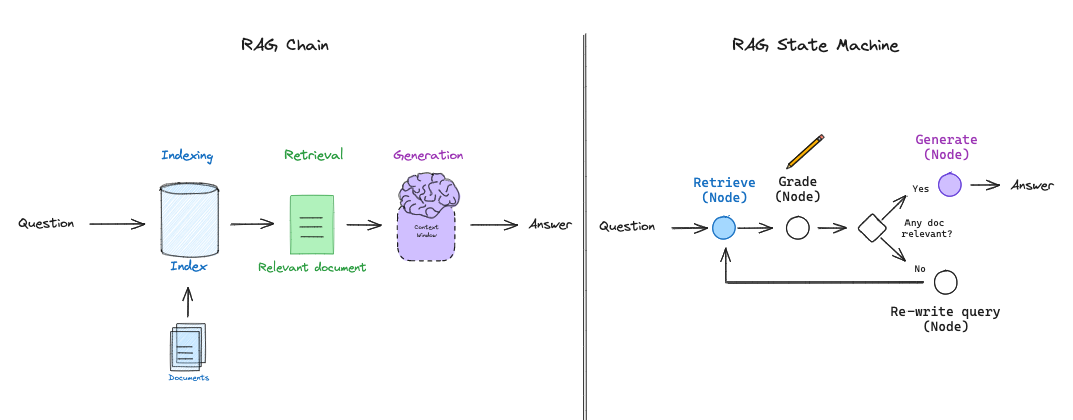
状态机让我们设计更复杂的 RAG“流程”
为了突出 LangGraph 的灵活性,我们将使用它来实现受两篇有趣且最近的自我反思 RAG 论文启发的想法,CRAG 和 Self-RAG。
纠正性 RAG(CRAG)
纠正性 RAG(CRAG)引入了一些有趣的想法(论文):
使用轻量级检索评估器来评估查询所获取文档的整体质量,为每个文档返回一个置信度分数。
如果认为基于向量存储的检索对用户查询来说模糊或不相关,则执行基于网络的文档检索以补充上下文。
通过将检索到的文档划分为“知识条”,为每个条打分并过滤掉无关的条,来细化检索到的知识。
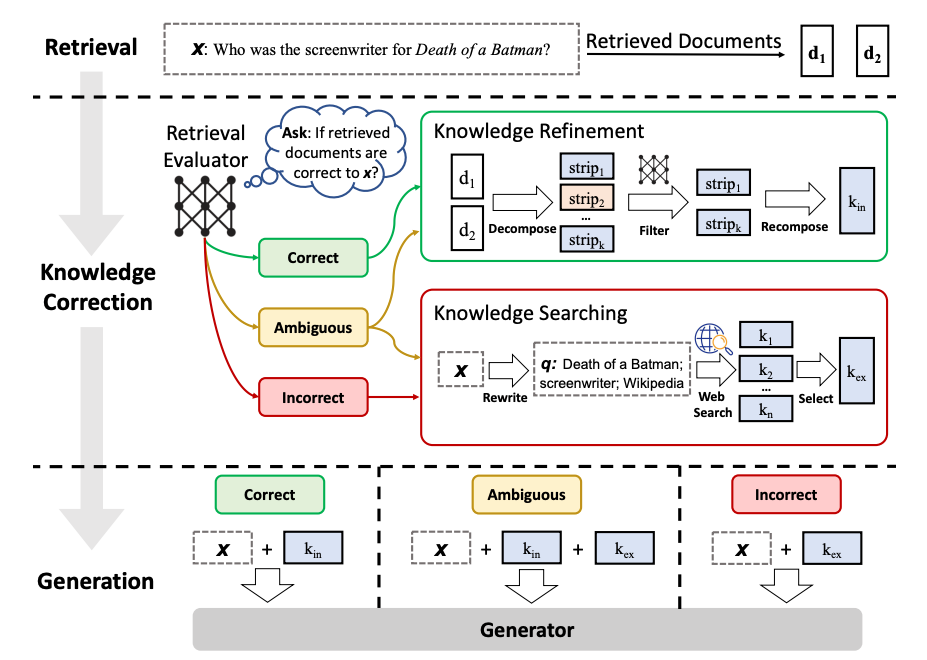
我们可以将其表示为一个图,进行一些简化和调整以供说明目的(当然,可以根据需要进行自定义和扩展):
我们将跳过知识细化阶段作为初步尝试。它代表了一种有趣且有价值的事后处理形式,但对理解如何在 LangGraph 中布局此工作流程并非必不可少。
如果有任何文档不相关,我们将使用网络搜索进行补充检索。我们将使用 Tavily Search API 进行网络搜索,它快速便捷。
我们将使用查询重写来优化网络搜索的查询。
对于二进制决策,我们使用 Pydantic 来建模输出,并将此功能作为 OpenAI 工具提供,该工具在运行LLM时每次都会被调用。这使我们能够模拟条件边的输出,其中一致的二进制逻辑至关重要。
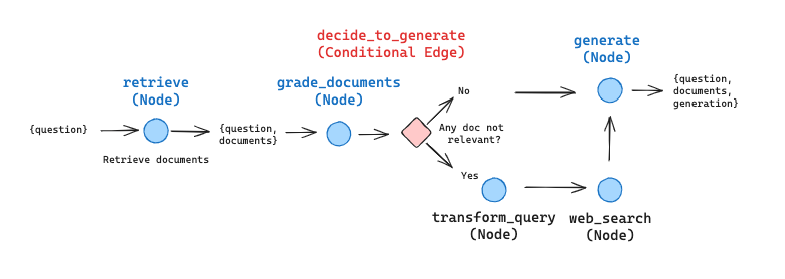
CRAG 的 LangGraph 实现
我们在示例笔记本中展示了这一点,并索引了三篇博客文章。我们可以在这里看到一个跟踪,突出了在询问有关博客文章中找到的信息时的使用情况:我们节点之间的逻辑流程被清楚地列出。
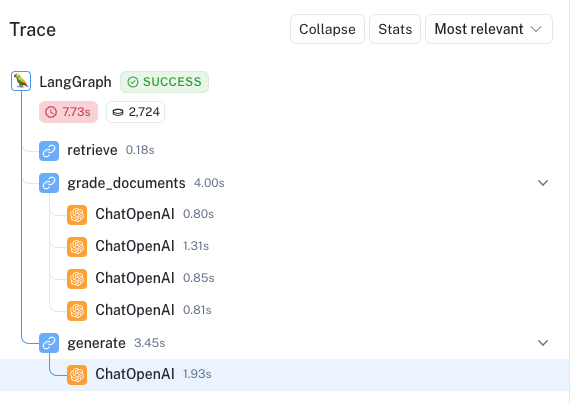
相比之下,我们问了一个与博客文章无关的问题。这里的跟踪显示,我们在条件边的下部路径上调用,并从用于最终生成的 Tavily 网络搜索中收集补充文档。
自我-RAG
自我-RAG 是与其他几个有趣的 RAG 思想(论文)相关的的方法。该框架训练一个LLM生成自我反思标记,这些标记控制 RAG 过程中的各个阶段。以下是标记的总结:
Retrieve标记决定根据输入的D与 ORx (question)、x (question)或y (generation)检索yes, no, continue个片段。输出是yes, no, continue
ISREL标记决定对于输入(x (question),d (chunk))在D中的d,段落D是否相关。输出是relevant, irrelevant。
ISSUP标记决定来自D中每个切片的第LLM代生成是否与该切片相关。输入为x,d,y对于在D中的d。它确认在y (generation)中的所有值得验证的陈述都由d支持。输出是fully supported, partially supported, no support。
ISUSE标记决定来自D中每个切片的生成是否是对x的有效响应。输入为x,y对于在D中的d。输出是{5, 4, 3, 2, 1}.。
这篇论文中的表格是对以上信息的补充:

自我 RAG 中使用的四种令牌类型
我们可以将其简化为图形来理解信息流:
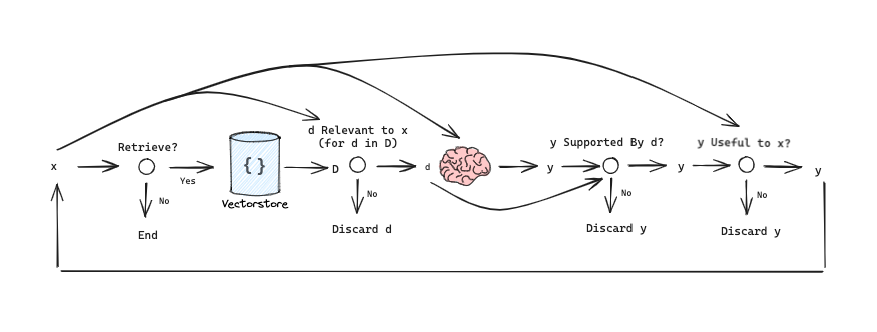
自我-RAG 中使用的流程示意图
我们可以在 LangGraph 中表示这一点,进行一些简化的说明/调整以供演示目的(可以根据需要进行自定义和扩展):
如上所述,我们对检索到的每份文档进行评分。如果有任何相关的内容,我们将继续生成。如果所有内容都不相关,则我们将转换查询以提出改进的问题并重新检索。注意:我们可以利用上述来自 CRAG(网络搜索)的想法作为此路径的补充节点!
该论文将对每个片段进行生成并两次评分。相反,我们从所有相关文档中进行一次生成。然后,根据文档(例如,防止 hallucinations)和上述答案对生成的内容进行评分。这减少了LLM调用的次数,提高了延迟,并允许将更多上下文融入生成中。当然,如果需要更多的控制,那么按片段生成并孤立地对其进行评分是一种简单的适应方法。
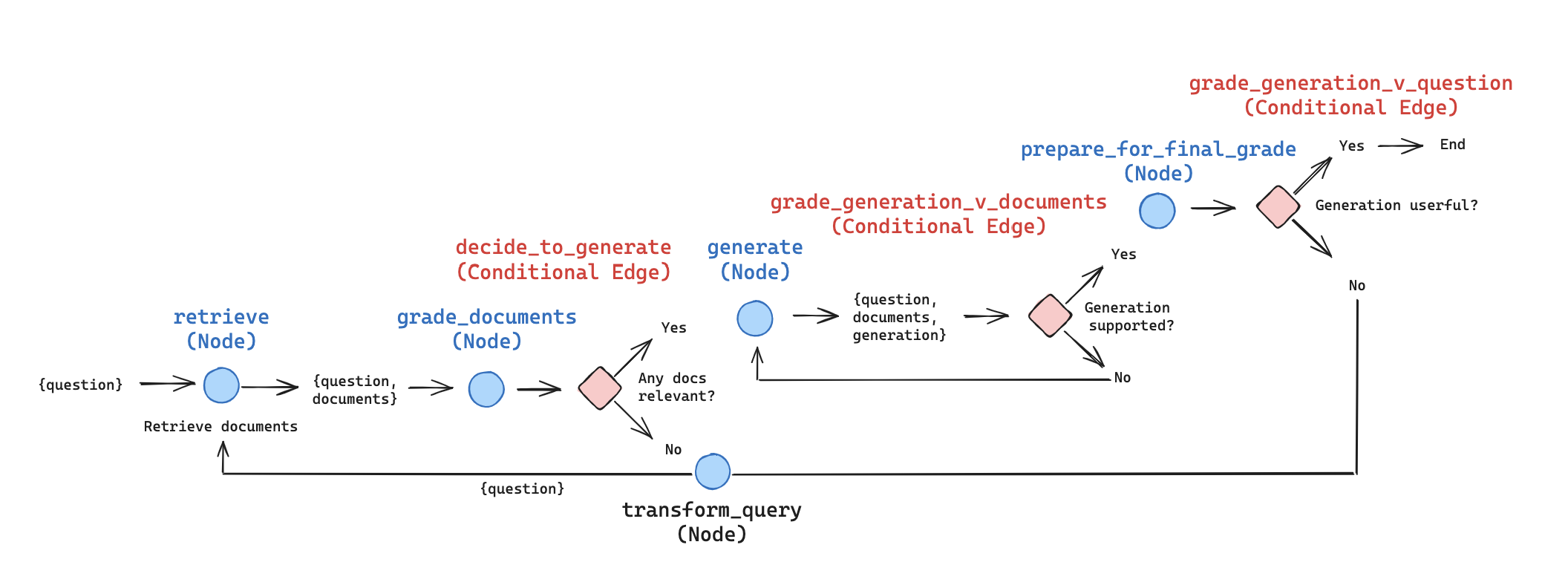
Self-RAG 的 LangGraph 实现
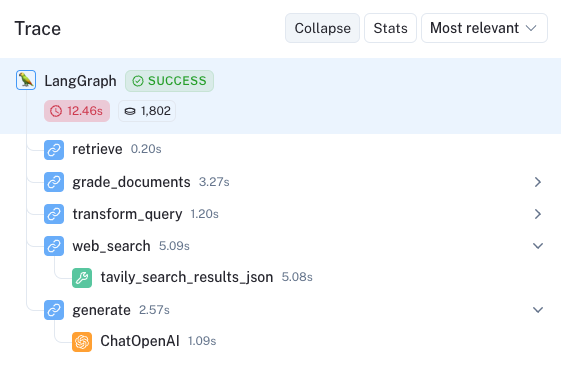
这是一个突出显示主动 RAG 自我纠正能力的例子。问题为 Explain how the different types of agent memory work? 。所有四篇文档都被认为是相关的,生成与文档的检查通过了,但生成的内容并未被认为对问题完全有用。
然后我们看到循环重新启动,这里有一个改写后的查询: How do the various types of agent memory function? 。因为不相关(在这里),四分之一的文档被过滤掉。然后生成的内容通过了两个检查:
The various types of agent memory include sensory memory, short-term memory, and long-term memory. Sensory memory retains impressions of sensory information for a few seconds. Short-term memory is utilized for in-context learning and prompt engineering. Long-term memory allows the agent to retain and recall information over extended periods, often by leveraging an external vector store.
整体跟踪比较容易审计,节点布局清晰:
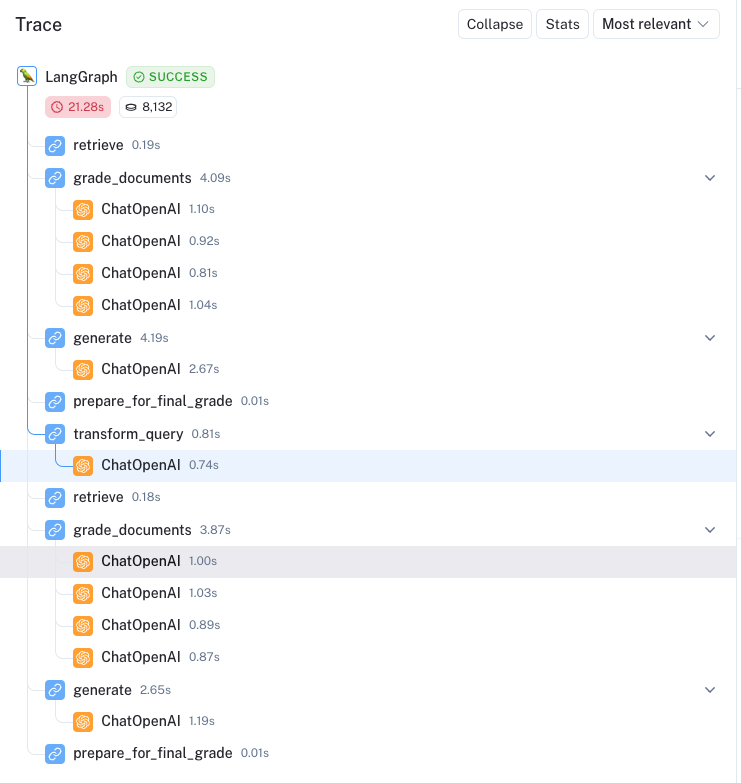
结论
自我反思可以大大提高 RAG 的效果,使其能够纠正质量差的检索或生成。最近几篇关于 RAG 的论文都关注这个主题,但实现这些想法可能有些棘手。在这里,我们展示 LangGraph 可以轻松用于自我反思式 RAG 的“流工程”。我们提供了实施两篇有趣论文(Self-RAG 和 CRAG)中思想的烹饪书。