
Building top-tier enterprise-grade intelligence using LLMs has traditionally been prohibitively expensive and resource-hungry, and often costs tens to hundreds of millions of dollars. As researchers, we have grappled with the constraints of efficiently training and inferencing LLMs for years. Members of the Snowflake AI Research team pioneered systems such as ZeRO and DeepSpeed, PagedAttention / vLLM, and LLM360 which significantly reduced the cost of LLM training and inference, and open sourced them to make LLMs more accessible and cost-effective for the community.
使用 LLMs 构建顶级企业级智能一直以来都是成本高昂、资源密集的,通常需要花费数千万到数亿美元。作为研究人员,我们多年来一直在努力应对高效训练和推理 LLMs 的限制。Snowflake AI 研究团队的成员开创了诸如 ZeRO 和 DeepSpeed、PagedAttention / vLLM 以及 LLM360 等系统,显著降低了 LLM 训练和推理的成本,并将它们开源,以使 LLMs 对社区更加可获得和具有成本效益。
Today, the Snowflake AI Research Team is thrilled to introduce Snowflake Arctic, a top-tier enterprise-focused LLM that pushes the frontiers of cost-effective training and openness. Arctic is efficiently intelligent and truly open.
今天,Snowflake AI 研究团队很高兴地介绍 Snowflake Arctic,这是一个面向企业的顶级LLM,推动着成本效益培训和开放性的前沿。Arctic 在智能和开放方面表现出色。
- Efficiently Intelligent: Arctic excels at enterprise tasks such as SQL generation, coding and instruction following benchmarks even when compared to open source models trained with significantly higher compute budgets. In fact, it sets a new baseline for cost-effective training to enable Snowflake customers to create high-quality custom models for their enterprise needs at a low cost.
高效智能:Arctic 擅长企业任务,如 SQL 生成、编码和指令遵循基准,即使与使用显著更高计算预算训练的开源模型相比也是如此。事实上,它为成本效益培训设定了一个新的基准,使 Snowflake 客户能够以低成本创建高质量的定制模型,以满足企业需求。
- Truly Open: Apache 2.0 license provides ungated access to weights and code. In addition, we are also open sourcing all of our data recipes and research insights.
真正的开放:Apache 2.0 许可证提供对权重和代码的无障碍访问。此外,我们还将所有的数据配方和研究见解开放源代码化。
Snowflake Arctic is available from Hugging Face, NVIDIA API catalog and Replicate today or via your model garden or catalog of choice, including Snowflake Cortex, Amazon Web Services (AWS), Microsoft Azure, Lamini, Perplexity and Together over the coming days.
Snowflake Arctic 现已在 Hugging Face、NVIDIA API 目录和 Replicate 上提供,或通过您选择的模型库或目录进行访问,包括 Snowflake Cortex、Amazon Web Services (AWS)、Microsoft Azure、Lamini、Perplexity 和 Together 在未来几天内提供。
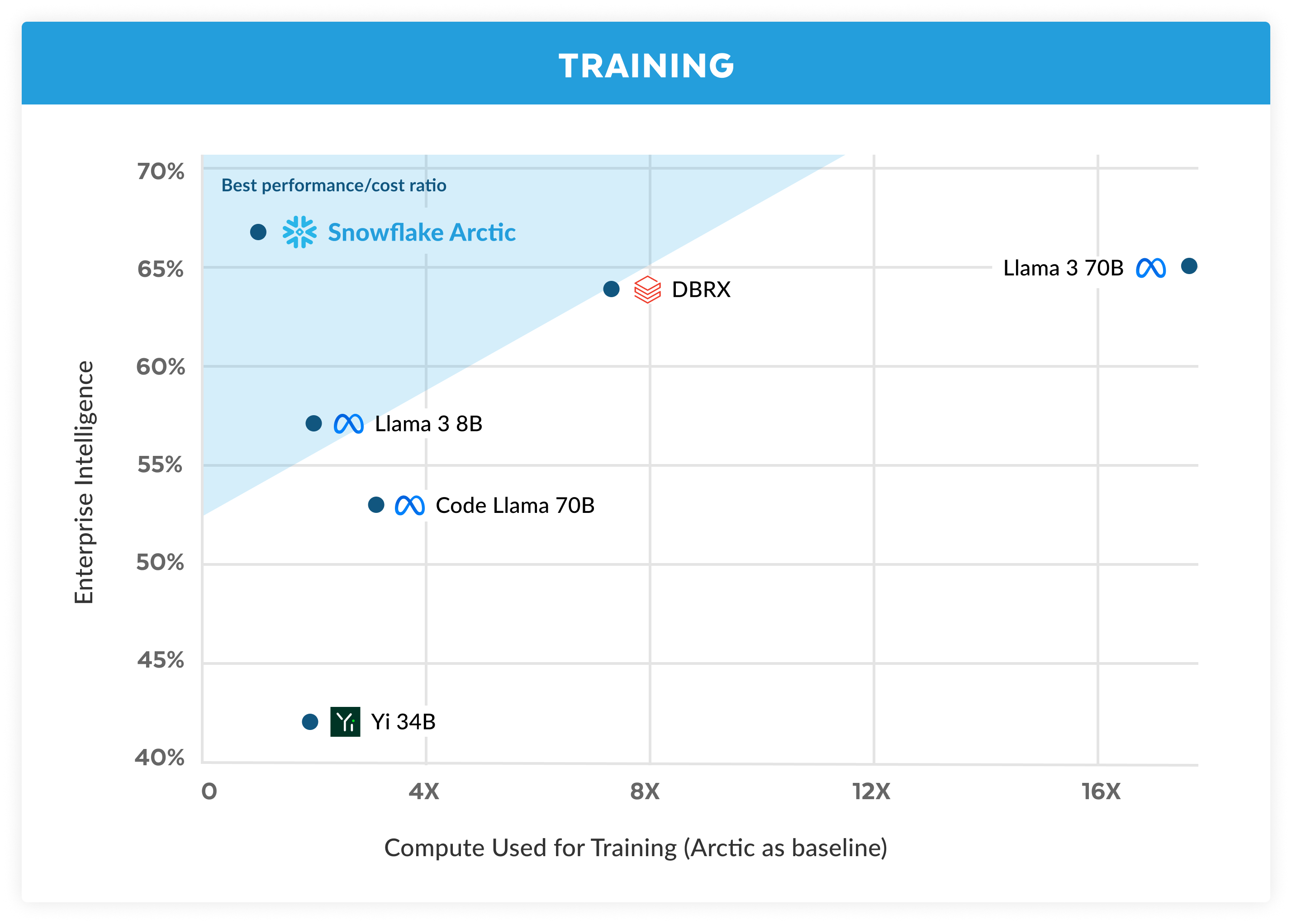
图 1. 企业智能 - 编码(人工评估+和 MBPP+),SQL 生成(Spider)和指令跟踪(IFEval)的平均值 - 与训练成本对比
Top-tier enterprise intelligence at incredibly low training cost
高级企业智能以极低的训练成本达到顶级水平
At Snowflake, we see a consistent pattern in AI needs and use cases from our enterprise customers. Enterprises want to use LLMs to build conversational SQL data copilots, code copilots and RAG chatbots. From a metrics perspective, this translates to LLMs that excel at SQL, code, complex instruction following and the ability to produce grounded answers. We capture these abilities into a single metric we call enterprise intelligence by taking an average of Coding (HumanEval+ and MBPP+), SQL Generation (Spider) and Instruction following (IFEval).
在 Snowflake,我们看到企业客户在 AI 需求和应用案例中存在一致的模式。企业希望使用LLMs构建对话式 SQL 数据联合助手、代码联合助手以及 RAG 聊天机器人。从指标的角度来看,这意味着能够擅长处理 SQL、代码、复杂指令跟进以及产生有根据的答案。我们将这些能力融合成为一个称为企业智能的单一指标,通过计算编码(HumanEval+和 MBPP+的平均)、SQL 生成(Spider)以及指令跟进(IFEval)的指标平均值。
Arctic offers top-tier enterprise intelligence among open source LLMs, and it does so using a training compute budget of roughly under $2 million (less than 3K GPU weeks). This means Arctic is more capable than other open source models trained with a similar compute budget. More importantly, it excels at enterprise intelligence, even when compared to those trained with a significantly higher compute budget. The high training efficiency of Arctic also means that Snowflake customers and the AI community at large can train custom models in a much more affordable way.
Arctic 在开源LLMs中提供一流的企业智能,并且只需要约 200 万美元的培训计算预算(不到 3K GPU 周)。这意味着与使用类似计算预算训练的其他开源模型相比,Arctic 更具能力。更重要的是,它在企业智能方面表现出色,即使与使用明显更高计算预算训练的模型比较也是如此。Arctic 的高效训练性能意味着 Snowflake 的客户和整个 AI 社区可以以更经济的方式训练定制模型。
As seen in Figure 1, Arctic is on par or better than both LLAMA 3 8B and LLAMA 2 70B on enterprise metrics, while using less than ½ of the training compute budget. Similarly, despite using 17x less compute budget, Arctic is on par with Llama3 70B in enterprise metrics like Coding (HumanEval+ & MBPP+), SQL (Spider) and Instruction Following (IFEval). It does so while remaining competitive on overall performance. For example, despite using 7x less compute than DBRX it remains competitive on Language Understanding and Reasoning (a collection of 11 metrics) while being better in Math (GSM8K). For a detailed breakdown of results by individual benchmark, see the Metrics section.
如图 1 所示,尽管使用不到 1/2 的训练计算预算,北极在企业指标上与 LLAMA 3 8B 和 LLAMA 2 70B 不相上下甚至更胜一筹。同样,尽管使用的计算预算比 Llama3 70B 少 17 倍,但北极在企业指标(如编码(HumanEval+和 MBPP+)、SQL(Spider)和指令遵循(IFEval))方面与其不相上下。在保持整体性能竞争力的同时实现这一点。例如,尽管使用的计算资源比 DBRX 少 7 倍,但在语言理解和推理方面(包括 11 个指标),北极仍保持竞争力,而在数学(GSM8K)方面则更胜一筹。有关每个基准测试结果的详细分解,请参阅度量部分。
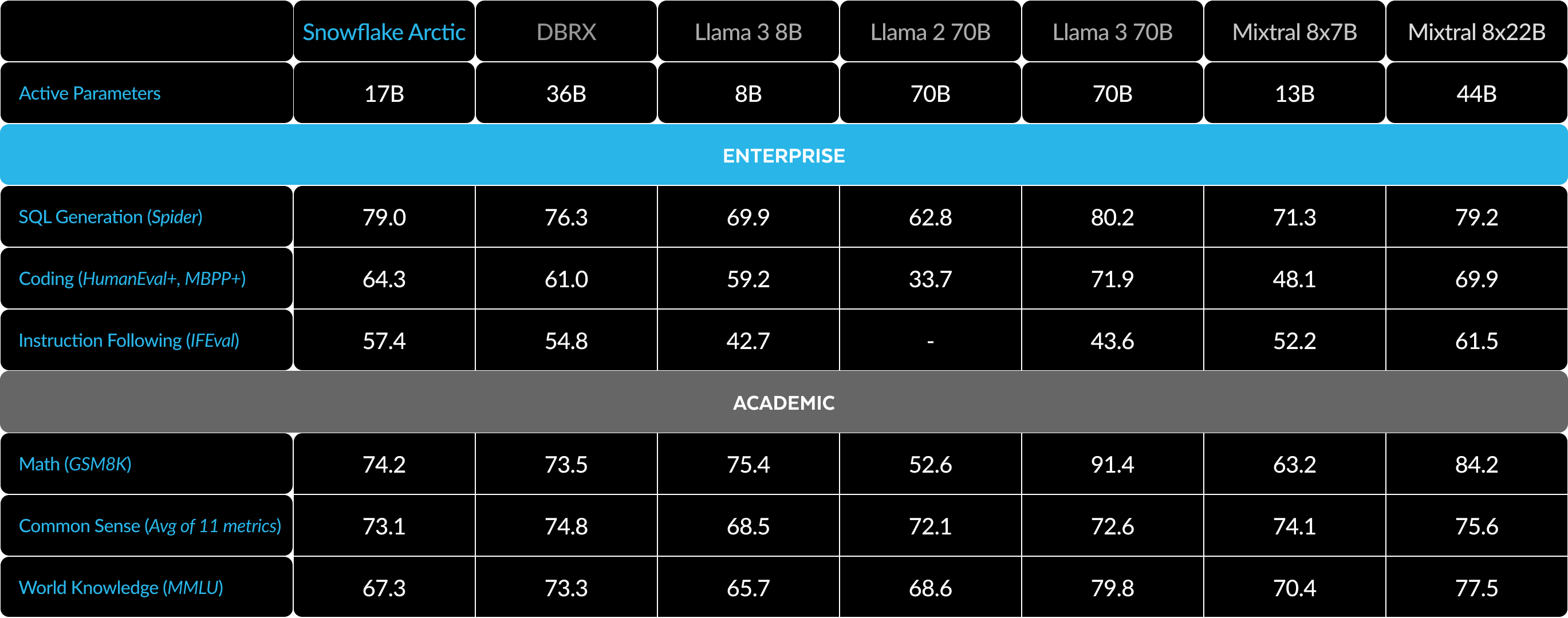
表1 模型架构和Arctic、Llama-2 70B、DBRX和Mixtral 8x22B的训练计算。训练计算与活跃参数和训练标记的乘积成正比。
Training efficiency 培训效率
To achieve this level of training efficiency, Arctic uses a unique Dense-MoE Hybrid transformer architecture. It combines a 10B dense transformer model with a residual 128×3.66B MoE MLP resulting in 480B total and 17B active parameters chosen using a top-2 gating. It was designed and trained using the following three key insights and innovations:
为了实现这种培训效率水平,Arctic 使用了独特的 Dense-MoE 混合变压器架构。它将一个 10B 的密集 Transformer 模型与一个剩余的 128×3.66B 的 MoE MLP 相结合,产生总计 480B 和 17B 活跃参数,使用顶级 2 的门控进行选择。它是使用以下三个关键的洞察和创新设计和训练的:
1) Many-but-condensed experts with more expert choices: In late 2021, the DeepSpeed team demonstrated that MoE can be applied to auto-regressive LLMs to significantly improve model quality without increasing compute cost.
1) 许多但压缩的专家有更多专家选择:2021 年底,DeepSpeed 团队证明了 MoE 可以应用于自回归LLMs以显著提高模型质量,而不增加计算成本。
In designing Arctic, we noticed, based on the above, that the improvement of the model quality depended primarily on the number of experts and the total number of parameters in the MoE model, and the number of ways in which these experts can be combined together.
在设计 Arctic 时,我们注意到,基于上述,模型质量的改善主要取决于专家的数量和 MoE 模型中参数的总数,以及这些专家可以组合在一起的方式数量。
Based on this insight, Arctic is designed to have 480B parameters spread across 128 fine-grained experts and uses top-2 gating to choose 17B active parameters. In contrast, recent MoE models are built with significantly fewer experts as shown in Table 2. Intuitively, Arctic leverages a large number of total parameters and many experts to enlarge the model capacity for top-tier intelligence, while it judiciously chooses among many-but-condensed experts and engages a moderate number of active parameters for resource-efficient training and inference.
基于这一洞察,Arctic被设计为在128个精细的专家中分布着480B个参数,并使用top-2门控选择17B个活跃参数。相比之下,最近的MoE模型使用的专家数量明显较少,如表2所示。直观地说,Arctic利用大量的总参数和许多专家来扩大一流智能模型的容量,同时明智地在众多但浓缩的专家中进行选择,并使用适量的活跃参数进行资源高效的训练和推理。

标准 MoE 架构与极地对比
2) Architecture and System Co-design: Training vanilla MoE architecture with a large number of experts is very inefficient even on the most powerful AI training hardware due to high all-to-all communication overhead among experts. However, it is possible to hide this overhead if the communication can be overlapped with computation.
2) 架构和系统协同设计:在最强大的 AI 训练硬件上,训练具有大量专家的普通 MoE 架构非常低效,因为专家之间的全对全通信开销很高。然而,如果通信可以与计算重叠,则可以隐藏此开销。
Our second insight is that combining a dense transformer with a residual MoE component (Fig 2) in the Arctic architecture enables our training system to achieve good training efficiency via communication computation overlap, hiding a big portion of the communication overhead.
我们的第二个洞察是,在北极架构中将密集变压器与剩余的 MoE 组件(图 2)相结合,能够通过通信计算重叠实现我们的训练系统实现良好的训练效率,从而隐藏了通信开销的大部分。
3) Enterprise-Focused Data Curriculum: Excelling at enterprise metrics like Code Generation and SQL requires a vastly different data curriculum than training models for generic metrics. Over hundreds of small-scale ablations, we learned that generic skills like common sense reasoning can be learned in the beginning, while more complex metrics like coding, math and SQL can be learned effectively towards the latter part of the training. One can draw analogies to human life and education, where we acquire capabilities from simpler to harder. As such, Arctic was trained with a three-stage curriculum each with a different data composition focusing on generic skills in the first phase (1T Tokens), and enterprise-focused skills in the latter two phases (1.5T and 1T tokens). A high-level summary of our dynamic curriculum is shown here.
3)企业关注的数据课程:在企业指标(如代码生成和 SQL)方面表现出色,需要一个与为通用指标训练模型完全不同的数据课程。通过数百次小规模剔除,我们了解到通用技能(如常识推理)可以在一开始学习,而更复杂的指标(如编码、数学和 SQL)可以有效地在训练后期学习。人们可以把它类比到人类生活和教育中,我们从简单到困难的能力逐渐获得。因此,Arctic 使用了一个三阶段课程进行训练,每个阶段具有不同的数据构成,第一个阶段专注于通用技能(1T Tokens),后两个阶段专注于企业技能(1.5T 和 1T Tokens)。我们动态课程的高级摘要如下。

重点关注企业智能的三相培训阿尔勒动物的动态数据组成
Inference efficiency 推理效率
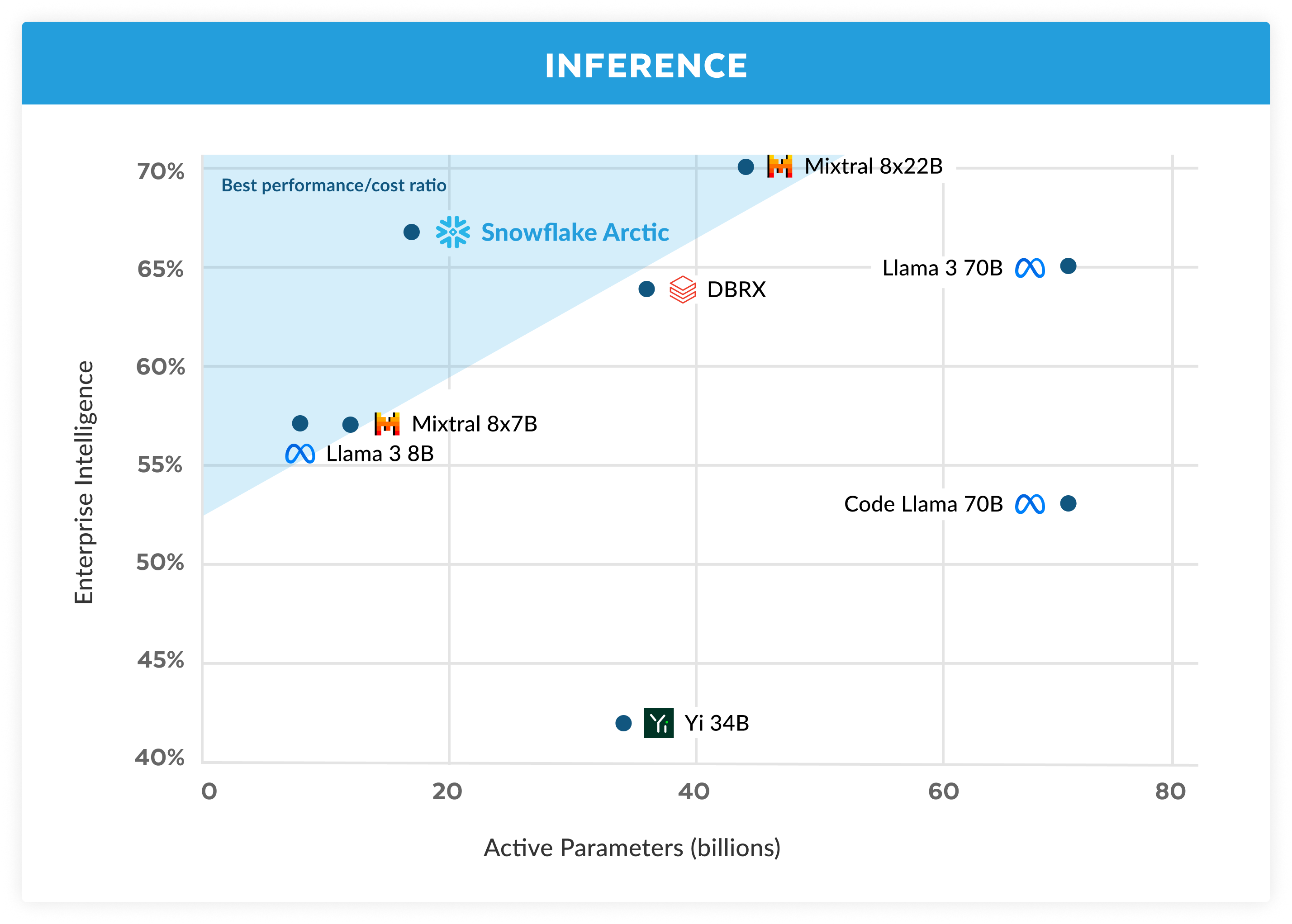
图 3。企业智能-编码的平均值(HumanEval+ 和 MBPP+)、SQL 生成(Spider)和推理过程中的指令遵循(IFEval)与推理过程中的活动参数
Training efficiency represents only one side of the efficient intelligence of Arctic. Inference efficiency is equally critical to allow for the practical deployment of the model at a low cost. Arctic represents a leap in MoE model scale, using more experts and total parameters than any other open sourced auto-regressive MoE model. As such, several system insights and innovations are necessary to run inference on Arctic efficiently:
训练效率仅代表 Arctic 高效智能的一面。推理效率同样至关重要,以便以低成本实现模型的实际部署。Arctic 代表了 MoE 模型规模的飞跃,使用的专家和总参数比任何其他开源自回归 MoE 模型都要多。因此,运行 Arctic 上的推理需要若干系统见解和创新。
a) At interactive inference of a small batch size, e.g., batch size of 1, an MoE model’s inference latency is bottlenecked by the time it takes to read all the active parameters, where the inference is memory bandwidth bounded. At this batch size, Arctic (17B active parameters) can have up to 4x less memory reads than Code-Llama 70B, and up to 2.5x less than Mixtral 8x22B (44B active parameters), leading to faster inference performance.
a) 在交互式推断的情况下, 例如批大小为 1, MoE 模型的推断延迟受制于读取所有活动参数所需的时间, 推断受内存带宽限制。在这个批大小下, Arctic (17B 活动参数)的内存读取量可能比 Code-Llama 70B 少 4 倍, 比 Mixtral 8x22B(44B 活动参数)少 2.5 倍, 从而提高了推断性能。
We have collaborated with NVIDIA and worked with NVIDIA TensorRT-LLM and the vLLM teams to provide a preliminary implementation of Arctic for interactive inference. With FP8 quantization, we can fit Arctic within a single GPU node. While far from fully optimized, at a batch size of 1, Arctic has a throughput of over 70+ tokens/second for effective interactive serving.
我们与 NVIDIA 合作, 与 NVIDIA TensorRT-LLM 和 vLLM 团队合作, 为交互式推断提供了 Arctic 的初步实现。使用 FP8 量化, 我们可以将 Arctic 放入单个 GPU 节点中。虽然远非完全优化, 但在批大小为 1 时, Arctic 的吞吐量达到了超过 70+ 个标记/秒, 用于有效的交互式服务。
b) As the batch size increases significantly e.g., thousands of tokens per forward pass, Arctic switches from being memory bandwidth bound to compute bound, where the inference is bottlenecked by the active parameters per token. At this point, Arctic incurs 4x less compute than CodeLlama 70B and Llama 3 70B.
随着批处理大小显著增加,例如,每次前向通行数以千计的令牌,Arctic 从内存带宽受限转变为计算受限,推断被每个令牌的活跃参数限制。在这一点上,Arctic 的计算比 CodeLlama 70B 和 Llama 3 70B 少 4 倍。
To enable compute bound inference and high relative throughput that corresponds to the small number of active parameters in Arctic (as shown in Fig 3), a large batch size is needed. Achieving this requires having enough KV cache memory to support the large batch size while also having enough memory to store nearly 500B parameters for the model. While challenging, this can be achieved with two-node inference using a combination of system optimizations such as FP8 weights, split-fuse and continuous batching, tensor parallelism within a node and pipeline parallelism across nodes.
为了实现计算受限推断和与 Arctic 中少量活跃参数对应的高相对吞吐量(如图 3 所示),需要一个大的批量大小。为了实现这一点,需要足够的 KV 缓存内存来支持大的批量大小,同时还需要足够的内存来存储模型的近 500B 参数。虽然具有挑战性,但可以通过两节点推断结合系统优化(如 FP8 权重、分裂融合和连续批处理、一个节点内的张量并行和跨节点的管道并行)来实现。
We have worked closely with NVIDIA to optimize inference for NVIDIA NIM microservices powered by TensorRT-LLM. In parallel, we are working with the vLLM community, and our in-house development team is also enabling efficient inference of Arctic for enterprise use cases in the coming weeks.
我们与英伟达紧密合作,优化了由 TensorRT-LLM驱动的英伟达 NIM 微服务的推断。同时,我们也与 vLLM 社区合作,我们的内部开发团队也将在未来几周内为企业用例高效推断阿尔提克。
Truly open 确实开放
Arctic was built upon the collective experiences of our diverse team, as well as major insights and learnings from the community. Open collaboration is key to innovation, and Arctic would not have been possible without open source code and open research insights from the community. We are thankful to the community and eager to give back our own learnings to enrich the collective knowledge and empower others to succeed.
Arctic 是在我们多元化团队的集体经验、以及社区的重要见解和学习基础之上构建的。开放协作是创新的关键,Arctic 无法没有社区的开源代码和开放研究见解。我们感谢社区,并渴望回馈我们自己的学习,丰富集体知识,增强其他人的成功能力。
Our commitment to a truly open ecosystem goes beyond open weights and code but also having open research insights and open source recipes.
我们对真正开放的生态系统的承诺不仅仅超越了开放的权重和代码,还包括开放的研究见解和开源秘方。
Open research insights 开放式研究洞见
The construction of Arctic has unfolded along two distinct trajectories: the open path, which we navigated swiftly thanks to the wealth of community insights, and the hard path, which is characterized by the segments of research that lacked prior community insights, necessitating intensive debugging and numerous ablations.
北极的建设沿着两条截然不同的轨迹展开:我们通过丰富的社区洞见迅速航行的开放路径,以及由于缺乏先前社区洞见而需要进行深入调试和大量修剪的硬路径。
With this release, we’re not just unveiling the model; we’re also sharing our research insights through a comprehensive ‘cookbook’ that opens up our findings from the hard path. The cookbook is designed to expedite the learning process for anyone looking to build world-class MoE models. It offers a blend of high-level insights and granular technical details in crafting an LLM akin to Arctic so you can build your desired intelligence efficiently and economically — guided by the open path instead of the hard one.
通过此发布,我们不仅展示了模型;还通过一本全面的“菜谱”分享我们的研究见解,这本书打开了我们从艰难的道路中得出的发现。这本菜谱旨在加快任何希望构建世界一流 MoE 模型的人的学习过程。它提供了高层次的见解和细致的技术细节,以制作类似于北极的LLM,这样您就可以通过开放的道路而不是艰难的道路高效经济地构建您需要的智能。
The cookbook spans a breadth of topics, including pre-training, fine-tuning, inference and evaluation, and also delves into modeling, data, systems and infrastructure. You can preview the table of contents, which outlines over 20 subjects. We will be releasing corresponding Medium.com blog posts daily over the next month. For instance, we’ll disclose our strategies for sourcing and refining web data in “What data to use?” We’ll discuss our data composition and curriculum in “How to compose data.” Our exploration of MoE architecture variations will be detailed in “Advanced MoE architecture,” discussing the co-design of model architecture and system performance. And for those curious about LLM evaluation, our “How to evaluate and compare model quality — less straightforward than you think” will shed light on the unexpected complexities we encountered.
这本菜谱涵盖了许多主题,包括预训练、微调、推理和评估,还深入探讨了建模、数据、系统和基础结构。您可以预览目录,其中概述了超过 20 个主题。在接下来的一个月里,我们将每天发布对应的 Medium.com 博客文章。例如,我们将披露我们在“使用什么数据?”中获取和改进网络数据的策略。我们将在“如何组织数据”中讨论数据构成和课程设置。我们的 MoE 体系结构变化探索将在“高级 MoE 体系结构”中详细介绍,讨论模型体系结构和系统性能的联合设计。对于那些好奇LLM评估的人,我们的“如何评估和比较模型质量-没有想象中那么简单”将阐明我们遇到的意外复杂性。
Through this initiative, we aspire to contribute to an open community where collective learning and advancement are the norms to push the boundaries of this field further.
通过这一举措,我们希望为一个开放的社区做出贡献,在这里,集体学习和进步是推动该领域发展边界的常规。
Open source serving code
开放源码服务代码
- We are releasing model checkpoints for both the base and instruct-tuned versions of Arctic under an Apache 2.0 license. This means you can use them freely in your own research, prototypes and products.
我们发布了 Arctic 的基础版和指导调优版本的模型检查点,使用 Apache 2.0 许可证。这意味着您可以在自己的研究、原型和产品中自由使用它们。
- Our LoRA-based fine-tuning pipeline, complete with a recipe, allows for efficient model tuning on a single node.
我们基于 LoRA 的微调管道,配备了配方,可以在单个节点上高效地进行模型微调。
- In collaboration with NVIDIA TensorRT-LLM and vLLM, we are developing initial inference implementations for Arctic, optimized for interactive use with a batch size of one. We are excited to work with the community to tackle the complexities of high-batch size inference of really large MoE models.
与 NVIDIA TensorRT-LLM和 vLLM 合作,我们正在为 Arctic 开发初步的推理实现,针对一个 batch size 的交互式使用进行了优化。我们很高兴与社区合作,应对高 batch size 推理的复杂性,处理非常大的 MoE 模型。
- Arctic is trained using a 4K attention context window. We are developing an attention-sinks-based sliding window implementation to support unlimited sequence generation capability in the coming weeks. We look forward to working with the community to extend to a 32K attention window in the near future.
Arctic 使用了一个 4K 的 attention 上下文窗口进行训练。我们正在开发一个基于 attention 汇集点的滑动窗口实现,以支持即将到来的无限序列生成能力。我们期待与社区合作,将其扩展到 32K 的 attention 窗口。
Metrics 指标
Our focus from a metrics perspective is primarily on what we call enterprise intelligence metrics, a collection of skills that are critical for enterprise customers that includes, Coding (HumanEval+ and MBPP+), SQL Generation (Spider) and Instruction following (IFEval).
我们在指标层面的关注主要集中在我们所称的企业智能指标上,这是企业客户至关重要的一组技能,包括 编码(HumanEval+ 和 MBPP+)、SQL 生成(Spider)和遵循指令(IFEval)。
At the same time, it is equally important to evaluate LLMs on the metrics the research community evaluates them on. This includes world knowledge, common sense reasoning and math capabilities. We refer to these metrics as academic benchmarks.
与此同时,同样重要的是根据研究界评估LLMs的标准来评估它们。 包括世界知识,常识推理和数学能力。 我们将这些指标称为学术基准。
Here is a comparison of Arctic with multiple open source models across enterprise and academic metrics:
这里是 Arctic 与多个开源模型在企业和学术指标上的比较:
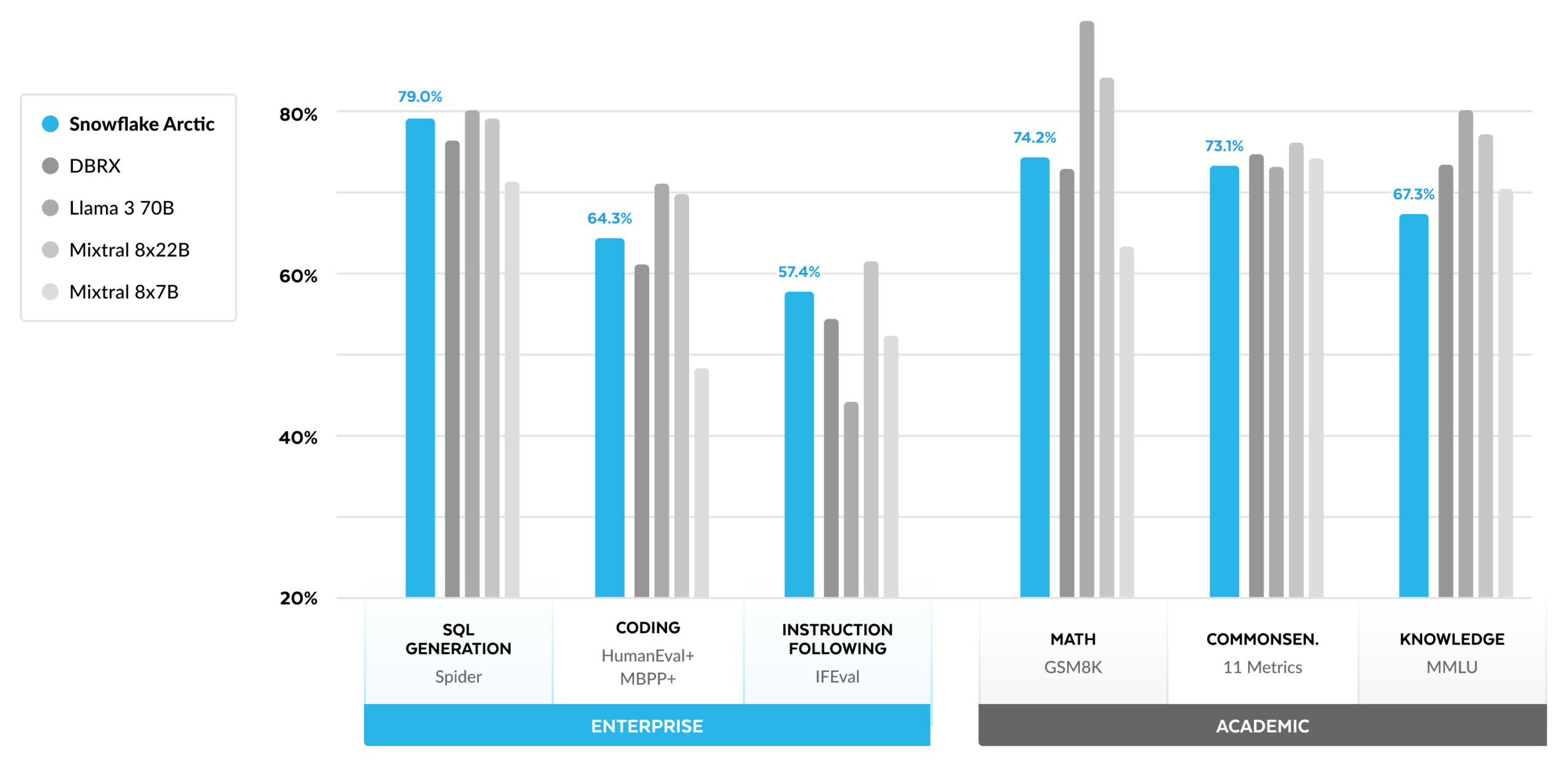
For enterprise metrics, Arctic demonstrates top-tier performance compared to all other open source models regardless of the compute class. For other metrics, it achieves top-tier performance at its compute class and even remains competitive with models trained with higher compute budgets. Snowflake Arctic is the best open source model for off-the-shelf enterprise use cases. And if you are looking to train your own model from scratch at the lowest total cost of ownership (TCO), the training infrastructure and systems optimization descriptions in our cookbook should be of great interest.
对于企业指标来说,与其他所有开源模型相比,Arctic 展示出了顶级性能,无论计算级别如何。对于其他指标来说,在其计算级别上,它实现了顶级性能,甚至与使用更高计算预算训练的模型保持竞争力。Snowflake Arctic 是最适合现成企业使用案例的最佳开源模型。如果您希望以最低的总拥有成本(TCO)从头开始培训自己的模型,我们的烹饪书中的培训基础设施和系统优化说明将非常有趣。
For academic benchmarks, there has been a focus on world knowledge metrics such as MMLU to represent model performance. With high-quality web and STEM data, MMLU monotonically moves up as a function of training FLOPS. Since one objective for Arctic was to optimize for training efficiency while keeping the training budget small, a natural consequence is lower MMLU performance compared to recent top-tier models. In line with this insight, we expect our ongoing training run at a higher training compute budget than Arctic to exceed Arctic’s MMLU performance. We note that performance on MMLU world knowledge doesn’t necessarily correlate with our focus on enterprise intelligence.
对于学术基准,一直以来都关注一些世界知识指标,如 MMLU,以表示模型的性能。利用高质量的网络和 STEM 数据,MMLU 递增地随着训练 FLOPS 的函数变化。由于 Arctic 的一个目标是在保持较小的训练预算的同时优化培训效率,一个自然的结果是相比于最近的顶级模型,MMLU 的性能较低。根据这一观察结果,预计我们正在进行的培训运行,其培训计算预算高于 Arctic,将超过 Arctic 的 MMLU 性能。我们注意到,MMLU 世界知识上的性能不一定与我们对企业智能的关注相一致。
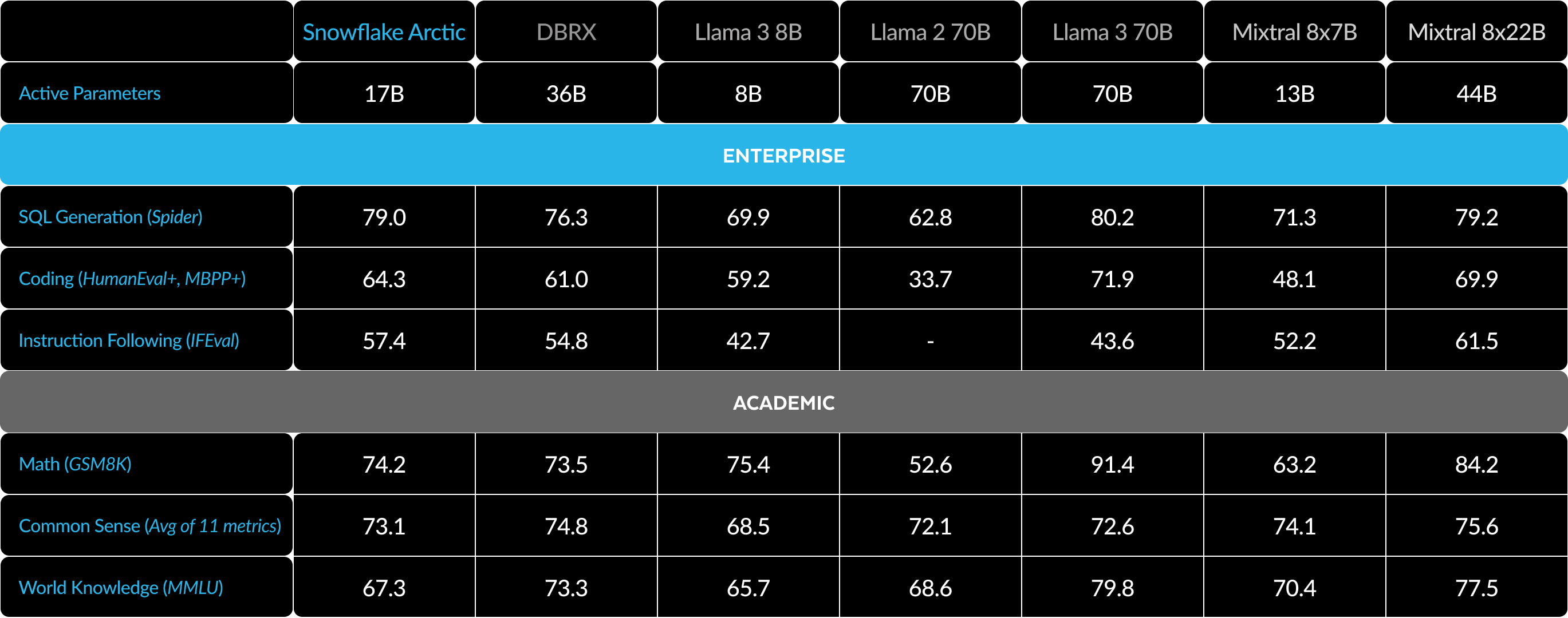
Table 3. Full Metrics Table. Comparing Snowflake Arctic with DBRX, LLAMA-3 8B, LLAMA-3 70B, Mixtral 8x7B, Mixtral 8x22B (instruction-tuned or chat variants if available).1 2 3
表 3。完整指标表。将 Snowflake Arctic 与 DBRX、LLAMA-3 8B、LLAMA-3 70B、Mixtral 8x7B、Mixtral 8x22B 进行比较(如果有指令调整或聊天变体)。 1 2 3
Getting started with Arctic
开始学习 Arctic
Snowflake AI Research also recently announced and open sourced the Arctic Embed family of models that achieves SoTA in MTEB retrieval. We are eager to work with the community as we develop the next generation in the Arctic family of models. Join us at our Data Cloud Summit on June 3-6 to learn more.
Snowflake AI 研究还最近宣布并开源了 Arctic Embed 系列模型,实现了 MTEB 检索的 SoTA。在我们开发 Arctic 系列模型的下一代时,我们迫切希望与社区合作。加入我们 6 月 3 日至 6 日举办的数据云峰会,了解更多信息。
Here’s how we can collaborate on Arctic starting today:
从今天开始,我们可以如何在 Arctic 上合作:
- Go to Hugging Face to directly download Arctic and use our Github repo for inference and fine-tuning recipes.
转到 '拥抱面孔' 直接下载 Arctic,使用我们的 Github 存储库进行推断和微调操作。 - For a serverless experience in Snowflake Cortex, Snowflake customers with a payment method on file will be able to access Snowflake Arctic for free until June 3. Daily limits apply.
在 Snowflake Cortex 中进行无服务器体验,拥有已存档付款方式的 Snowflake 客户将能够免费访问 Snowflake Arctic 直到 6 月 3 日。每日限额适用。 - Access Arctic via your model garden or catalog of choice including Amazon Web Services (AWS), Lamini, Microsoft Azure, NVIDIA API catalog, Perplexity, Replicate and Together AI over the coming days.
通过您选择的模型花园或目录,包括亚马逊网络服务(AWS)、Lamini、Microsoft Azure、NVIDIA API 目录、Perplexity、Replicate 和 Together AI,在未来几天内访问 Arctic。 - Chat with Arctic! Try a live demo now on Streamlit Community Cloud or on Hugging Face Streamlit Spaces, with an API powered by our friends at Replicate.
与 Arctic 进行聊天!现在在 Streamlit Community Cloud 或 Hugging Face Streamlit Spaces 上尝试实时演示,API 由我们的朋友 Replicate 提供动力。 - Get mentorship and credits to help you build your own Arctic-powered applications during our Arctic-themed Community Hackathon.
获得指导和学分,帮助您在我们的北极主题社区黑客马拉松期间构建自己的北极动力应用程序。
And finally, don’t forget to read the first edition of our cookbook recipes to learn more about how to build your own custom MoE models in the most cost-effective way possible.
最后,不要忘记阅读我们的食谱第一版,了解如何以最具成本效益的方式构建自己的定制 MoE 模型。
Acknowledgments 致谢
We would like to thank AWS for their collaboration and partnership in building Arctic’s training cluster and infrastructure, and NVIDIA for their collaboration in enabling Arctic support on NVIDIA NIM with TensorRT-LLM. We also thank the open source community for producing the models, datasets and dataset recipe insights we could build on top of to make this release possible. We would also like to thank our partners in AWS, Microsoft Azure, NVIDIA API catalog, Lamini, Perplexity, Replicate and Together AI for their collaboration in making Arctic available
1. The 11 metrics for Language Understanding and Reasoning include ARC-Easy, ARC-Challenge, BoolQ, CommonsenseQA, COPA, HellaSwag, LAMBADA, OpenBookQA, PIQA, RACE and WinoGrande.
2. Evaluation scores for HumanEval+/MBPP+ v0.1.0 were obtained assuming (1) bigcode-evaluation-harness using model-specific chat templates and aligned post-processing, (2) greedy decoding. We evaluated all models with our pipeline to ensure consistency. We validated that our evaluations results are consistent with EvalPlus leaderboard. In fact, our pipeline produces numbers that are a few points higher than the numbers in EvalPlus for all models giving us confidence that we are evaluating each model in the best way possible.
3. IFEval scores reported are the average of prompt_level_strict_acc and inst_level_strict_acc






