Why BERT is Not GPT
为什么 BERT 不是 GPT
照片由 david clarke 在 Unsplash 上拍摄
The most recent breakthroughs in language models have been the use of neural network architectures to represent text. There is very little contention that large language models have evolved very rapidly since 2018.
语言模型最近的突破是使用神经网络架构来表示文本。几乎没有争议,大型语言模型自 2018 年以来已经迅速发展。
It all started with Word2Vec and N-Grams in 2013 as the most recent in language modelling. RNNs and LSTMs came later in 2014. These were followed by the breakthrough of the Attention Mechanism.
一切始于 2013 年的 Word2Vec 和 N-gram,这是语言模型最近的进展。RNN 和 LSTM 在 2014 年稍后出现。随后是注意力机制的突破。
It was the Attention Mechanism breakthrough that gave birth to Large Pre-Trained Models and Transformers.
正是注意力机制的突破催生了大型预训练模型和 Transformer。
Both BERT and GPT are based on the Transformer architecture. This piece compares and contrasts between the two models.
BERT 和 GPT 都是基于 Transformer 架构的。这篇文章比较和对比了这两个模型。
The story starts with word embedding.
故事从词嵌入开始。
What is Word Embedding? 什么是词嵌入?
Word embedding is a technique in natural language processing (NLP) where words are represented as vectors in a continuous vector space. These vectors capture semantic meanings, allowing words with similar meanings to have similar representations.
词嵌入是自然语言处理(NLP)中的一种技术,其中单词被表示为连续向量空间中的向量。这些向量捕捉语义含义,使得具有相似含义的单词具有相似的表示。
For example, in a word embedding model, the words “king” and “queen” would have vectors that are close to each other, reflecting their related meanings. In the same way, the words ‘car’ and ‘truck’ are also likely to have vectors very close to each other. Same with ‘cat’ and ‘dog’.
例如,在词嵌入模型中,单词“king”和“queen”的向量会彼此接近,反映出它们相关的含义。同样,单词‘car’和‘truck’也很可能有非常接近的向量。‘cat’和‘dog’也是如此。
However, you would not expect ‘car’ and ‘dog’ to have very close vectors.
然而,你不会期望‘car’和‘dog’有非常接近的向量。
A famous example of word embedding is Word2Vec.
词嵌入的一个著名例子是 Word2Vec。
图片由:Mahajan, Patil, 和 Sankar。2013
Word2Vec is a neural network model that uses n-grams by training on context windows of words. There are two main approaches:
Word2Vec 是一个神经网络模型,它通过在单词的上下文窗口上训练来使用 n-gram。主要有两种方法:
Continuous Bag of Words (CBOW): Predicts a target word based on its surrounding context (n-grams). For example, given the context “the cat sat on the,” CBOW predicts the word “mat.”
连续词袋(CBOW):基于周围的上下文(n-gram)预测目标单词。例如,给定上下文“the cat sat on the,”CBOW 预测单词“mat。”
Skip-gram: Predicts the surrounding words given a target word. For example, given the word “cat,” Skip-gram predicts the context words “the,” “sat,” “on,” and “the.”
Skip-gram:给定目标单词预测周围的单词。例如,给定单词“cat,”Skip-gram 预测上下文单词“the,”“sat,”“on,”和“the。”
Both methods help to capture semantic relationships; with similar words having similar vector representations. This facilitates various NLP tasks by providing meaningful word embeddings.
这两种方法都有助于捕捉语义关系;相似单词具有相似的向量表示。这通过提供有意义的词嵌入来促进各种 NLP 任务。
Word2Vec uses context from large corpora to learn word associations. This approach enables various NLP tasks, such as sentiment analysis and machine translation, by providing a rich representation of words based on their usage patterns.
Word2Vec 使用大型语料库中的上下文来学习单词关联。这种方法通过提供基于单词使用模式的丰富表示,使得各种 NLP 任务,如情感分析和机器翻译成为可能。
图片作者:Mahajan, Patil, 和 Sankar。2013
Word2Vec using n-grams was introduced by Mahajan, Patil, and Sankar in their 2013 paper titled, ‘Word2Vec Using Character N–Grams’.
使用 n-gram 的 Word2Vec 是由 Mahajan, Patil, 和 Sankar 在他们的 2013 年论文‘Word2Vec Using Character N–Grams’中提出的。
Recurrent Neural Networks (RNNs) are a type of neural network designed for sequential data. They process inputs sequentially, maintaining a hidden state that captures information about previous inputs, making them suitable for tasks like time series prediction and natural language processing. The RNN type of network can be traced as far back as 1925 when the Ising model was used to simulate magnetic interactions, analogous to RNNs’ state transitions for sequence learning.
循环神经网络(RNNs)是一种设计用于序列数据的神经网络。它们按顺序处理输入,维持一个隐藏状态来捕获关于之前输入的信息,这使得它们适合于时间序列预测和自然语言处理等任务。RNN 类型的网络可以追溯到 1925 年,当时 Ising 模型被用来模拟磁相互作用,类似于 RNNs 在序列学习中的状态转换。
Long Short-Term Memory (LSTM) networks are a specialized type of RNN designed to overcome the limitations of standard RNNs, particularly the vanishing gradient problem.
长短期记忆(LSTM)网络是一种特殊的 RNN,设计用来克服标准 RNN 的限制,尤其是梯度消失问题。
图片作者:Hochreiter 和 Schmidhuber。1997
LSTMs use gates (input, output, and forget gates) to regulate the flow of information, enabling them to maintain long-term dependencies and remember important information over long sequences. LSTMs were invented by Hochreiter and Schmidhuber in 1997, and presented in their paper titled ‘Long Short-Term Memory’.
LSTMs 使用门(输入门、输出门和遗忘门)来调节信息流,使它们能够维持长期依赖并记住长序列中的重要信息。LSTMs 是由 Hochreiter 和 Schmidhuber 在 1997 年发明的,并在他们的论文‘Long Short-Term Memory’中提出。
Here is an implementation of the cell architecture shown above for LSTM:
下面是上面显示的 LSTM 单元结构的实现:
图片作者:Hochreiter 和 Schmidhuber。1997
Comparison of Word2Vec, RNNs, and LSTMs
Word2Vec、RNNs 和 LSTMs 的比较
Purpose: Word2Vec is primarily a word embedding technique, generating dense vector representations for words based on their context. RNNs and LSTMs, on the other hand, are used for modeling and predicting sequences.
目的:Word2Vec 主要是一种单词嵌入技术,根据单词的上下文生成单词的密集向量表示。而 RNNs 和 LSTMs 则用于建模和预测序列。
Architecture: Word2Vec employs shallow, two-layer neural networks, while RNNs and LSTMs have more complex, deep architectures designed to handle sequential data. (The more hidden layers an architecture has, the deeper the network.)
架构:Word2Vec 采用浅层、两层神经网络,而 RNNs 和 LSTMs 有更复杂、深层的设计,用于处理序列数据。(架构拥有的隐藏层越多,网络越深。)
Output: Word2Vec outputs fixed-size vectors for words. RNNs and LSTMs output sequences of vectors, suitable for tasks requiring context understanding over time, like language modeling and translation.
输出:Word2Vec 为单词输出固定大小的向量。RNNs 和 LSTMs 输出向量序列,适合于需要随时间理解上下文的任务,如语言建模和翻译。
Memory Handling: LSTMs, unlike standard RNNs and Word2Vec, can effectively manage long-term dependencies due to their gating mechanisms, making them more powerful for complex sequence tasks.
内存处理:与标准 RNNs 和 Word2Vec 不同,LSTMs 由于其门控机制,能够有效地管理长期依赖,使得它们在处理复杂序列任务时更加强大。
Word2Vec is(was) ideal for creating word embeddings, while RNNs and LSTMs excel(ed) in tasks involving sequential data and long-term dependencies.
Word2Vec 非常适合创建单词嵌入,而 RNNs 和 LSTMs 在处理序列数据和长期依赖的任务中表现出色。
What is the Attention Mechanism?
注意力机制是什么?
The attention mechanism is a key component in neural networks, particularly in transformers and large pre-trained language models that allows the model to focus on specific parts of the input sequence when generating output. It assigns different weights to different words or tokens in the input, enabling the model to prioritize important information and handle long-range dependencies more effectively.
注意力机制是神经网络中的关键组成部分,特别是在变压器和大型预训练语言模型中,它允许模型在生成输出时专注于输入序列的特定部分。它为输入中的不同单词或标记分配不同的权重,使模型能够优先处理重要信息并更有效地处理长距离依赖关系。
The attention mechanism paper is titled “Attention Is All You Need” by Ashish Vaswani et al.
注意力机制的论文标题为“AAttention Is All You Need”由 Ashish Vaswani 等人撰写。
Here is HOW TRANSFORMERS EVOLVED.
这里是变压器是如何进化的。
Tokenization is a very important part of the attention mechanism.
分词是注意力机制中非常重要的一部分。
Attention Mechanism Relation to Transformers
注意力机制与变压器的关联
Transformers use self-attention mechanisms to process input sequences in parallel rather than sequentially, as done in RNNs. This allows transformers to capture contextual relationships between all tokens in a sequence simultaneously, improving the handling of long-term dependencies and reducing training time.
变压器使用自注意力机制并行处理输入序列,而不是像 RNN 那样顺序处理。这使得变压器能够同时捕获序列中所有标记之间的上下文关系,提高处理长期依赖关系的能力并减少训练时间。
The self-attention mechanism helps in identifying the relevance of each token to every other token within the input sequence, enhancing the model’s ability to understand the context.
自注意力机制有助于识别输入序列中每个标记对其他每个标记的相关性,增强模型理解上下文的能力。
Attention Mechanism Relation to Large Pre-Trained Language Models
注意力机制与大型预训练语言模型的关联
Large pre-trained language models, such as BERT and GPT, are built on transformer architectures and leverage attention mechanisms to learn contextual embeddings from vast amounts of text data.
大型预训练语言模型,如 BERT 和 GPT,基于变压器架构构建,并利用注意力机制从大量文本数据中学习上下文嵌入。
These models utilize multiple layers of self-attention to capture intricate patterns and dependencies within the data, enabling them to perform a wide range of NLP tasks with high accuracy after fine-tuning on specific tasks.
这些模型利用多层自注意力捕获数据中的复杂模式和依赖关系,使它们在特定任务微调后能够以高准确性执行广泛的自然语言处理任务。
The attention mechanism is fundamental to the success of transformers and large pre-trained language models, allowing them to efficiently handle complex language understanding and generation tasks.
注意力机制是变压器和大型预训练语言模型成功的基础,使它们能够有效地处理复杂的语言理解和生成任务。
This focus on understanding context is similar to the way YData Fabric, a data quality platform designed for data science teams, also emphasizes on the importance of clean and well-structured data for building high-performing AI models. Just as attention mechanisms help language models understand the nuances of language, good data quality is essential for AI models to learn accurate and generalizable patterns from the data they are trained on.
这种对理解上下文的关注与 YData Fabric(一种为数据科学团队设计的数据质量平台)的方法相似,它也强调清洁和结构良好的数据对于构建高性能 AI 模型的重要性。正如注意力机制帮助语言模型理解语言的细微差别,良好的数据质量对于 AI 模型从训练数据中学习准确和泛化的模式至关重要。
So, What is BERT and GPT
那么,BERT 和 GPT 是什么?
First things first, both of these models are based on the transformer architecture. Both models are Large Pre-Trained Language Models.
首先,这两种模型都是基于变压器架构的。这两种模型都是大型预训练语言模型。
BERT
BERT stands for Bidirectional Encoder Representations from Transformers. It is a pre-trained language model developed by Google and was introduced in October 2018. It is based on the transformer architecture. (If you’ve read this far you know what I did there.).
BERT 代表双向编码器表示来自变压器的。它是由谷歌开发的一种预训练语言模型,于 2018 年 10 月推出。它基于变压器架构。(如果你读到这里,你就知道我在那里做了什么。)
The abstract of the paper by Devlin, Ming-Wei, Lee, and Toutanova, titled “ BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, reads:
论文摘要,Devlin, Ming-Wei, Lee 和 Toutanova 合著的《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》 reads:
“We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications.”(Devlin, Ming-Wei, Lee & Toutanova, 2018).
“我们介绍了一种新的语言表示模型,称为 BERT,代表双向编码器表示来自变换器的模型。与最近的语言表示模型不同,BERT 旨在通过在所有层上同时依赖左右上下文进行预训练深度双向表示。因此,预训练的 BERT 模型可以通过添加一个额外的输出层进行微调,以创建各种任务(如问题回答和语言推理)的最先进模型,而无需对特定任务的架构进行大量修改。”(Devlin, Ming-Wei, Lee & Toutanova, 2018)。
图片作者:Devlin, Ming-Wei, Lee & Toutanova, 2018
Two things to note, (1). BERT is bidirectional, that is, it can move from left to right simultaneously. (2). Answering questions and language inference are its major tasks.
需要注意的两件事:(1) BERT 是双向的,即它可以同时从左到右移动。(2) 回答问题和语言推理是它的主要任务。
Some applications of BERT include ClinicalBERT and BioBERT.
BERT 的一些应用包括 ClinicalBERT 和 BioBERT。
GPT
GPT stands for Generative Pre-trained Transformer. It refers to a family of large language models (LLMs) created by OpenAI, known for their ability to generate human-like text. GPT models can create new text content, like poems, code, scripts, musical pieces, and more. They are pre-trained and use transformer models in their core architecture.
GPT 代表生成预训练变换器。它指的是由 OpenAI 创建的一组大型语言模型(LLMs),以其生成类人文本的能力而闻名。GPT 模型可以创建新的文本内容,如诗歌、代码、脚本、音乐作品等。它们是预训练的,并在其核心架构中使用变换器模型。
Again, you see what I did there?
再次,你看懂我在那里做了什么吗?
In their paper titled, “Improving Language Understanding by Generative Pre-Training”, releasing GPT, Radford, Narasimhan, Salimans, and Sutskever put it in the abstract that:
在他们的论文《Improving Language Understanding by Generative Pre-Training》中,发布 GPT 的 Radford, Narasimhan, Salimans 和 Sutskever 在摘要中写道:
“Natural language understanding comprises a wide range of diverse tasks such as textual entailment, question answering, semantic similarity assessment, and document classification. Although large unlabeled text corpora are abundant, labeled data for learning these specific tasks is scarce, making it challenging for discriminatively trained models to perform adequately. We demonstrate that large gains on these tasks can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task.”(Radford, Narasimhan, Salimans, & Sutskever, 2016).
“自然语言理解包括广泛的多样化任务,如文本蕴含、问题回答、语义相似度评估和文档分类。尽管存在大量未标记的文本语料库,但用于学习这些特定任务的有标签数据却很稀缺,这使得判别性训练模型难以充分表现。我们证明了通过在未标记文本的多样化语料库上进行生成预训练的语言模型,然后在每个特定任务上进行判别性微调,可以实现这些任务上的巨大提升。”(Radford, Narasimhan, Salimans, & Sutskever, 2016)。
图片作者:Radford, Narasimhan, Salimans, & Sutskever, 2016
Two things to note: (1).GPT is majorly generative. (2). GPT is unidirectional.
需要注意的两件事:(1) GPT 主要是生成性的。(2) GPT 是单向的。
There have been several iterations of GPT, with GPT-4 being the latest and most advanced.
GPT 已经进行了几次迭代,其中 GPT-4 是最新的也是最先进的。
Major Differences Between BERT and GPT
BERT 和 GPT 之间的主要区别
First, let’s note the principal similarities between BERT and GPT
首先,让我们注意 BERT 和 GPT 之间的主要相似之处
- Both are based on the Transformer architecture.
两者都是基于变换器架构的。 - Both are pre-trained models from a large corpus of text.
两者都是从大量文本语料库中预训练的模型。 - Both are fine-tuned for various functions.
两者都针对各种功能进行了微调。
The differences are: 不同之处在于:
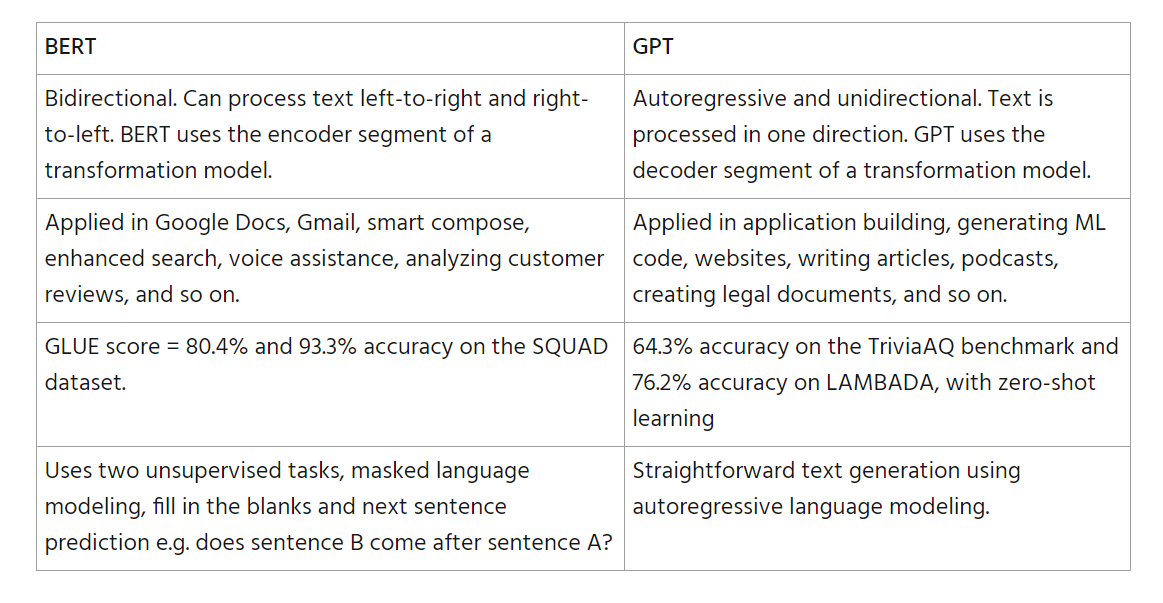
And all that is why BERT is not GPT.
这就是为什么 BERT 不是 GPT 的原因。