
LLM 预训练和评估奖励模型的提示
讨论 2024 年 3 月的 AI 研究论文

这是人工智能研究的又一个月,很难选出最喜欢的研究。
除了新的研究之外,还有许多其他重要的公告。其中,xAI 开源了其 Grok-1 模型,该模型拥有 3140 亿个参数,是目前最大的开源模型。此外,有报道称 Claude-3 正在接近甚至超过 GPT-4 的性能。然后还有 Open-Sora 1.0(用于视频生成的完全开源项目)、Eagle 7B(一种基于 RWKV 的新模型)、Mosaic 的 1320 亿参数 DBRX(一种专家混合模型)以及 AI21 的 Jamba(一种基于 Mamba 的 SSM 模型)。
然而,由于这些模型的详细信息相当匮乏,我将专注于讨论研究论文。本月,我正在阅读一篇关于 LLM 持续预训练策略的论文,随后是一篇关于人类反馈强化学习中的奖励建模(一种流行的 LLM 对齐方法)以及一个新的基准测试的讨论。
持续预训练对于大语言模型是一个重要的话题,因为它允许我们更新现有的 LLM,例如确保这些模型保持最新的信息和趋势。此外,它还使我们能够将它们适应新的目标领域,而不必从头开始重新训练。
奖励建模非常重要,因为它使我们能够更紧密地与人类偏好对齐大语言模型,并在一定程度上有助于安全。但除了优化人类偏好之外,它还提供了一种机制来学习和适应大语言模型以执行复杂的任务,通过提供指令输出示例,其中正确行为的显式编程是具有挑战性或不切实际的。
祝您阅读愉快!
1. 简单且可扩展策略以持续预训练大型语言模型
我们经常讨论微调 LLM 以遵循指令。然而,在实际应用中,使用新知识或特定领域数据更新 LLM 也非常重要。最近的一篇论文《简单而可扩展的策略,持续预训练大型语言模型》提供了有价值的见解,介绍了如何使用新数据继续预训练 LLM。
具体来说,研究人员比较了三种不同训练方式的模型:
常规预训练:使用随机权重初始化模型并在数据集 D1 上对其进行预训练。
持续预训练:从上述场景中的预训练模型开始,并在数据集 D2 上进一步对其进行预训练。
在合并数据集上重新训练:与第一种情况一样,使用随机权重初始化模型,但将其训练于 D1 和 D2 数据集的组合(联合)上。
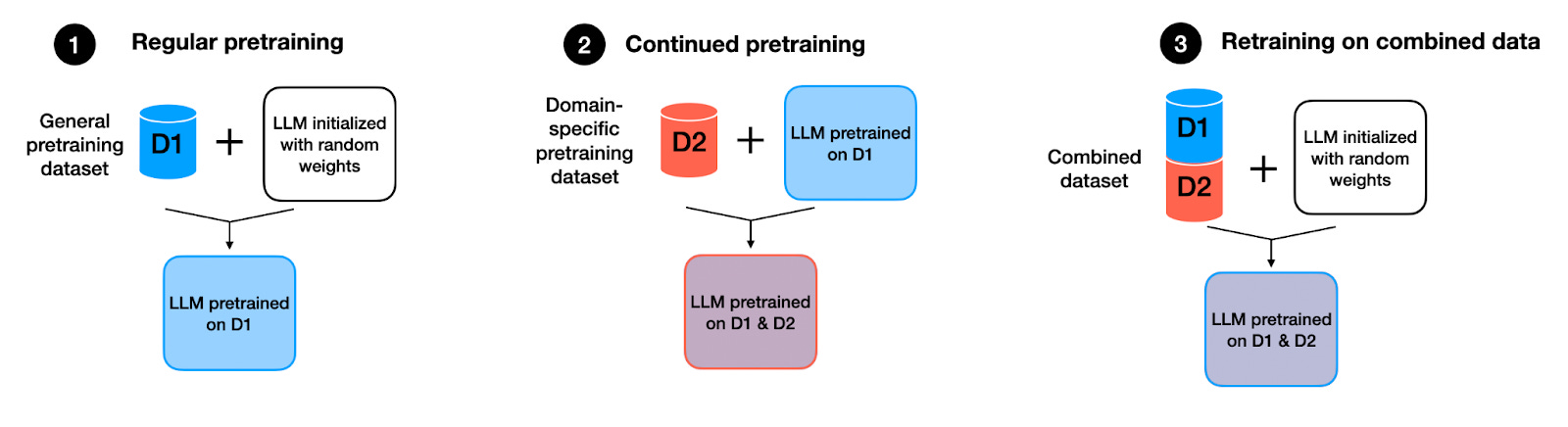
三个预训练方法的插图
方法 3,在合并数据集上重新训练,是该领域普遍采用的做法,例如我去年在讨论 BloombergGPT 论文时所写的。这是因为重新训练通常有助于找到良好的学习率计划——通常使用线性预热后跟半个周期余弦衰减——并且有助于灾难性遗忘。
灾难性遗忘是指神经网络在序列学习任务中,尤其是在跨时序训练的多样数据集或任务中,学习新信息时会忘记之前学过的信息的现象。这在长时间跨多个数据集或任务的模型训练中尤其成问题。
因此,通过在包含新旧信息的综合数据集上重新训练模型,模型可以在保持先前学习任务性能的同时适应新的数据。
1.1 要点与结果
这篇 24 页的论文报告了大量的实验,附带了无数的图表,按照今天的标准来说非常详尽。为了将其简化成易于消化的格式,以下图表总结了主要结果,表明通过继续预训练可以达到与从头开始在组合数据集上重新训练相同的好性能。
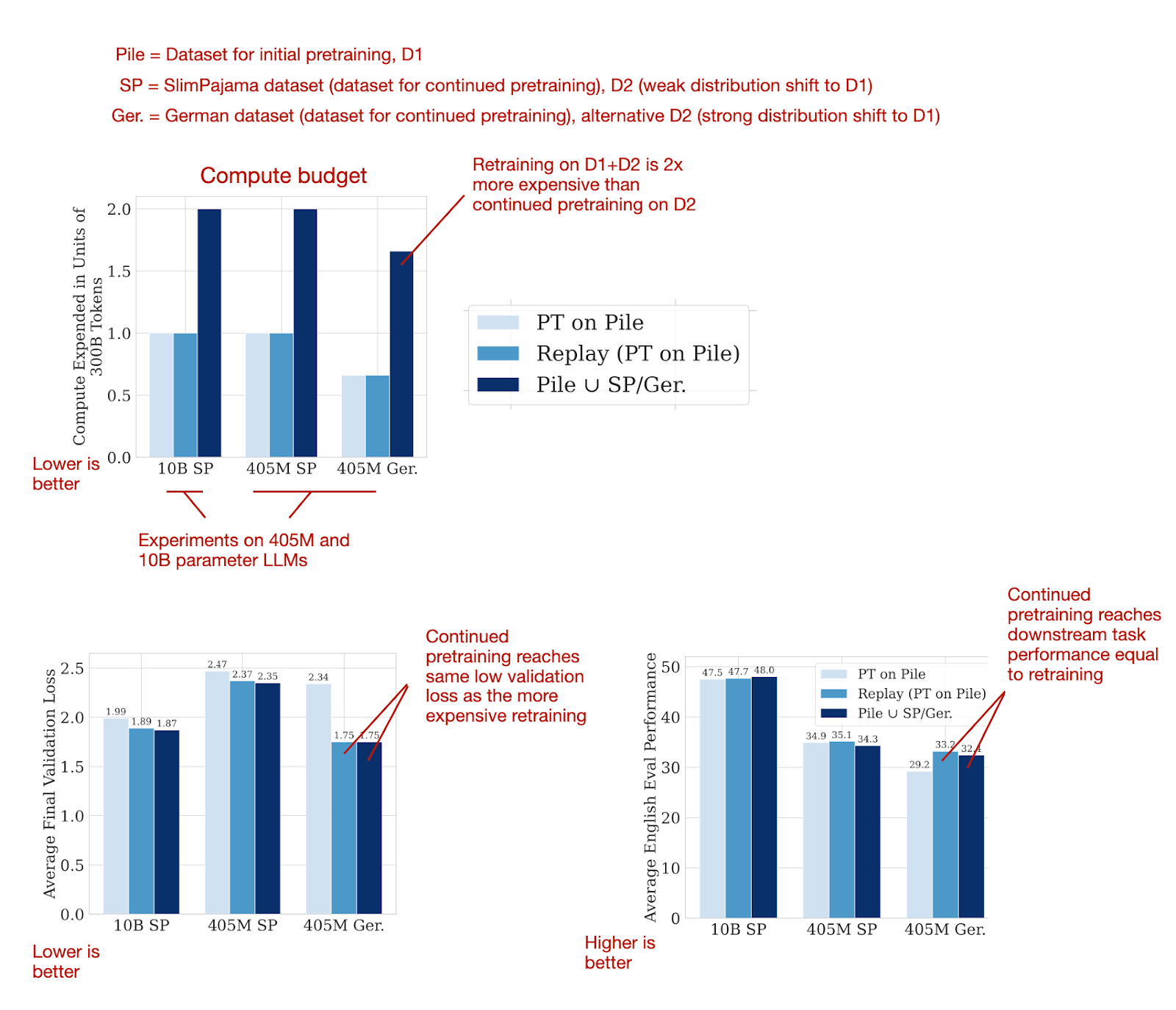
持续预训练比从头开始重新训练便宜两倍(因为它只使用了一半的数据,因为已经有了预先训练好的模型),但可以达到相同良好的性能。来源:来自 https://arxiv.org/abs/2403.08763 的可注释图表.
成功应用持续预训练的“诀窍”是什么?
重新加热和重新衰减学习率(见下一节)。
在新的数据集(D2)中添加一小部分原始预训练数据(D1)(例如,5%)以防止灾难性遗忘。注意,较小的比例如 0.5%和 1%也是有效的。
1.2 学习率调度
在预训练或微调 LLM 时,通常使用学习率调度,其开始是线性热启动,然后是半周期余弦衰减,如下所示。
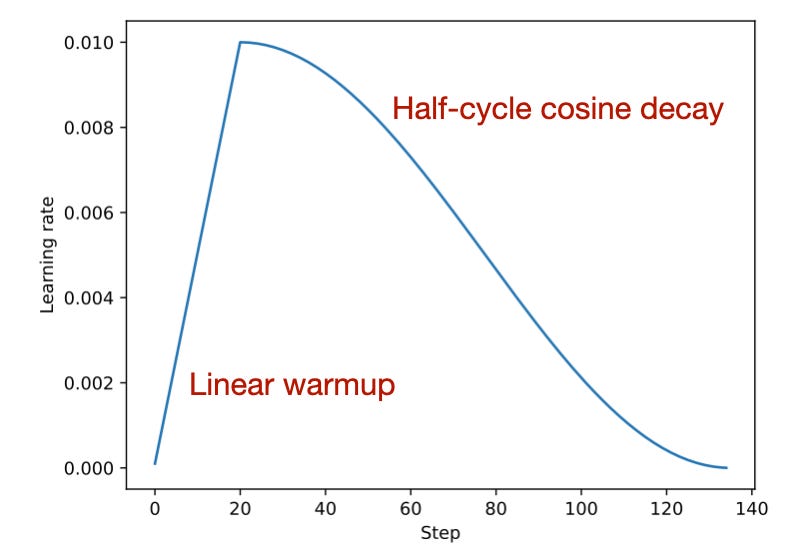
用于预训练和微调 LLM 的常见学习率调度。来源:从零开始构建大语言模型 [https://github.com/rasbt/LLMs-from-scratch/blob/main/appendix-D/01\_main-chapter-code/appendix-D.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/appendix-D/01_main-chapter-code/appendix-D.ipynb)
如上图所示,在线性热身期间,学习率从低值开始,逐渐增加到训练初期的预设值。这种方法有助于在进入主要训练阶段之前稳定模型的权重参数。随后,在热身期之后,学习率采用余弦衰减计划来同时训练和逐渐降低模型的学习率。
考虑到预训练以非常低的 learning rate 结束,我们如何调整学习率以继续预训练?通常情况下,我们将学习率重新引入到热身阶段,并在其后跟随衰减阶段,这被称为重新加热和重新衰减。简单来说,我们使用与初始预训练阶段完全相同的 learning rate 计划。
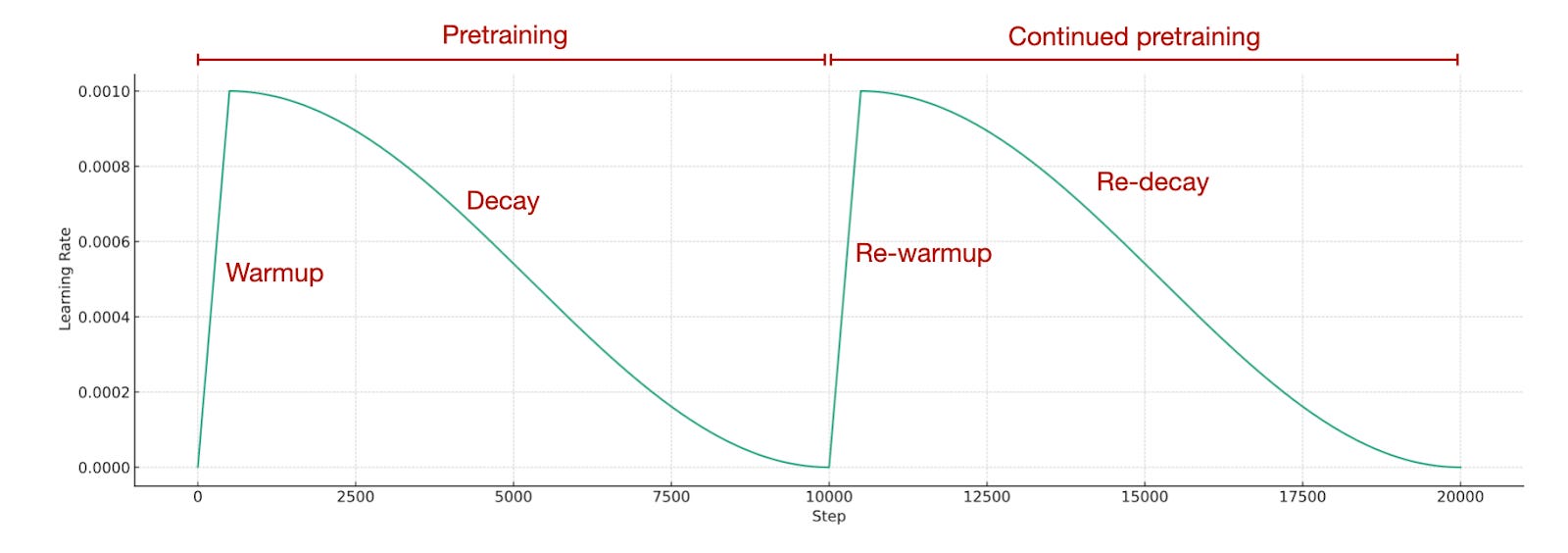
持续预训练的时间安排。图基于从零开始构建大语言模型 https://github.com/rasbt/LLMs-from-scratch/blob/main/appendix-D/01\_main-chapter-code/appendix-D.ipynb
作者们发现重新加温和重新衰减确实有效。此外,他们还与所谓的“无限学习率”计划进行了比较,该计划指的是在 2021 年《Scaling Vision》论文中概述的计划。这个计划从温和的余弦(或可选的反平方根)衰减开始,过渡到恒定的学习率,并以尖锐的衰减结束,用于退火。
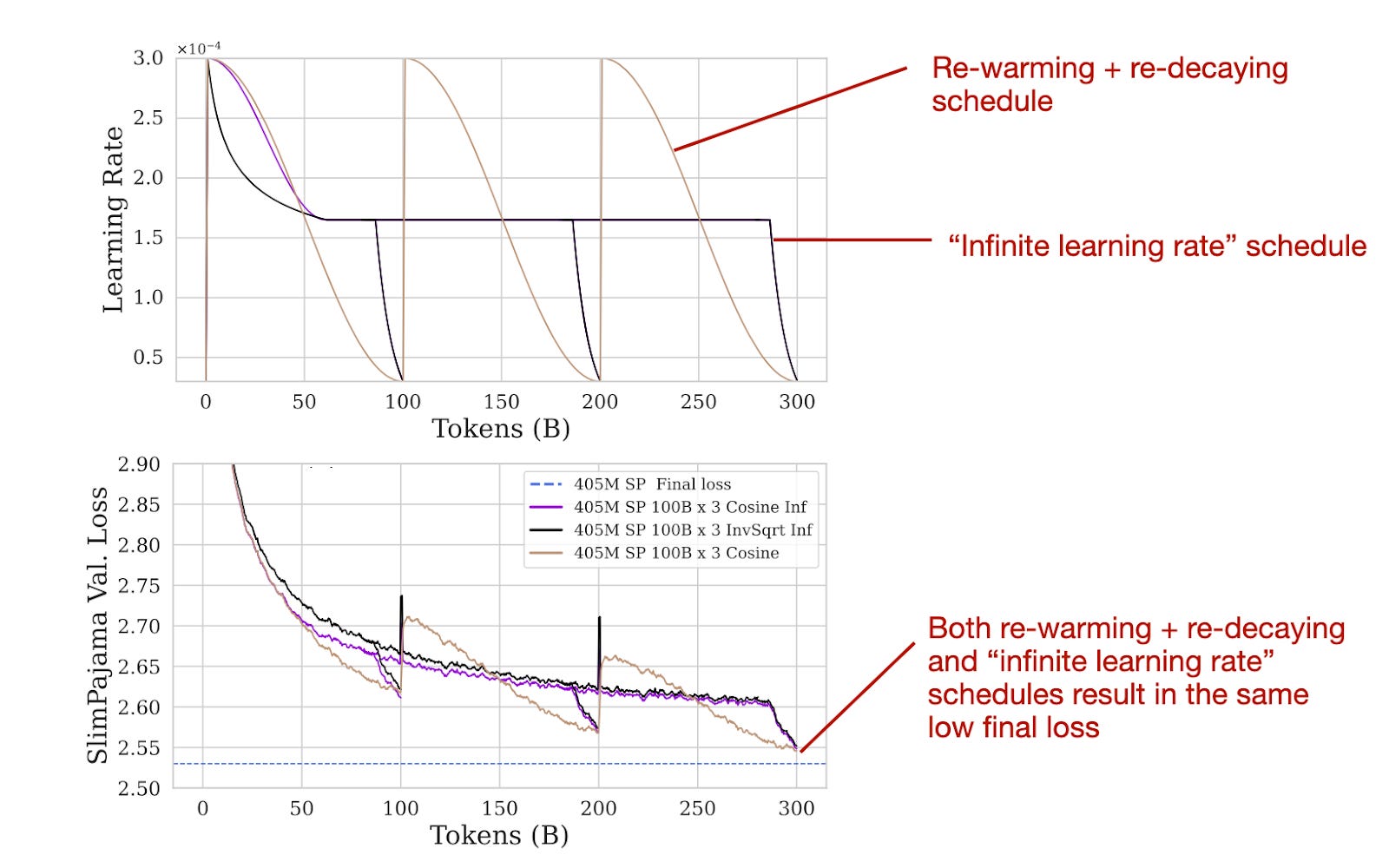
对三个预训练阶段的重新加热和重新衰减以及无限学习率调度进行的实验。来源:来自 https://arxiv.org/abs/2403.08763 的可注释图表
无限学习率调度可以很方便,因为可以通过短暂的指数衰减阶段(相对于完成余弦半周期)在任何时候停止预训练期间的恒定学习率阶段。然而,如上图所示的结果表明,使用“无限学习率”进行预训练和持续预训练并不是必要的。常见的重新加热和重新衰减与无限学习率调度具有相同的最终损失。
1.3 结论和注意事项
据我所知,重新加温、重新衰减以及将原始预训练数据添加到新数据中,这些方法在某种程度上是常识。然而,我非常赞赏研究人员花费时间正式测试这种方法,并在这份长达 24 页的详细报告中进行了详细的阐述。
此外,我发现“无限学习率”调度并不是必需的,实际上会导致与常见线性预热后半周期余弦衰减相同的最终损失。
虽然我欣赏这篇论文所进行的全面实验套件,但一个潜在的注意事项是,大多数实验都是在相对较小的 405M 参数模型上进行的,采用相对经典的 LLM 架构(GPT-NeoX)。然而,作者表明,这些结果对于一个 10B 参数模型也是正确的,这有理由相信这些结果也适用于更大的(例如,70B 参数)模型和可能还有架构变化。
研究人员关注了规模相似的预训练数据集。此外,附录还显示,当继续预训练的数据集只有初始预训练数据集的 50%或 30%时,这些结果是一致的。一个有趣的研究方向是探讨当预训练数据集比初始预训练数据集小得多时(这是实践中常见的情况),这些趋势和建议是否仍然适用。
另一个有趣的研究方向是测试持续预训练如何影响指令微调 LLM 的遵循指令能力。特别是,我很好奇在通过持续预训练更新 LLM 的知识后是否需要再进行一轮指令微调。
顺便提一下,如果您对高效预训练大型语言模型(LLM)感兴趣,我们最近开源了一个名为 Thunder 的 PyTorch 编译器。
当我的同事们将该技术应用于我参与开发的 LitGPT 开源 LLM 库时,他们在预训练 Llama 2 7B 模型时实现了 40%的运行时间性能提升。
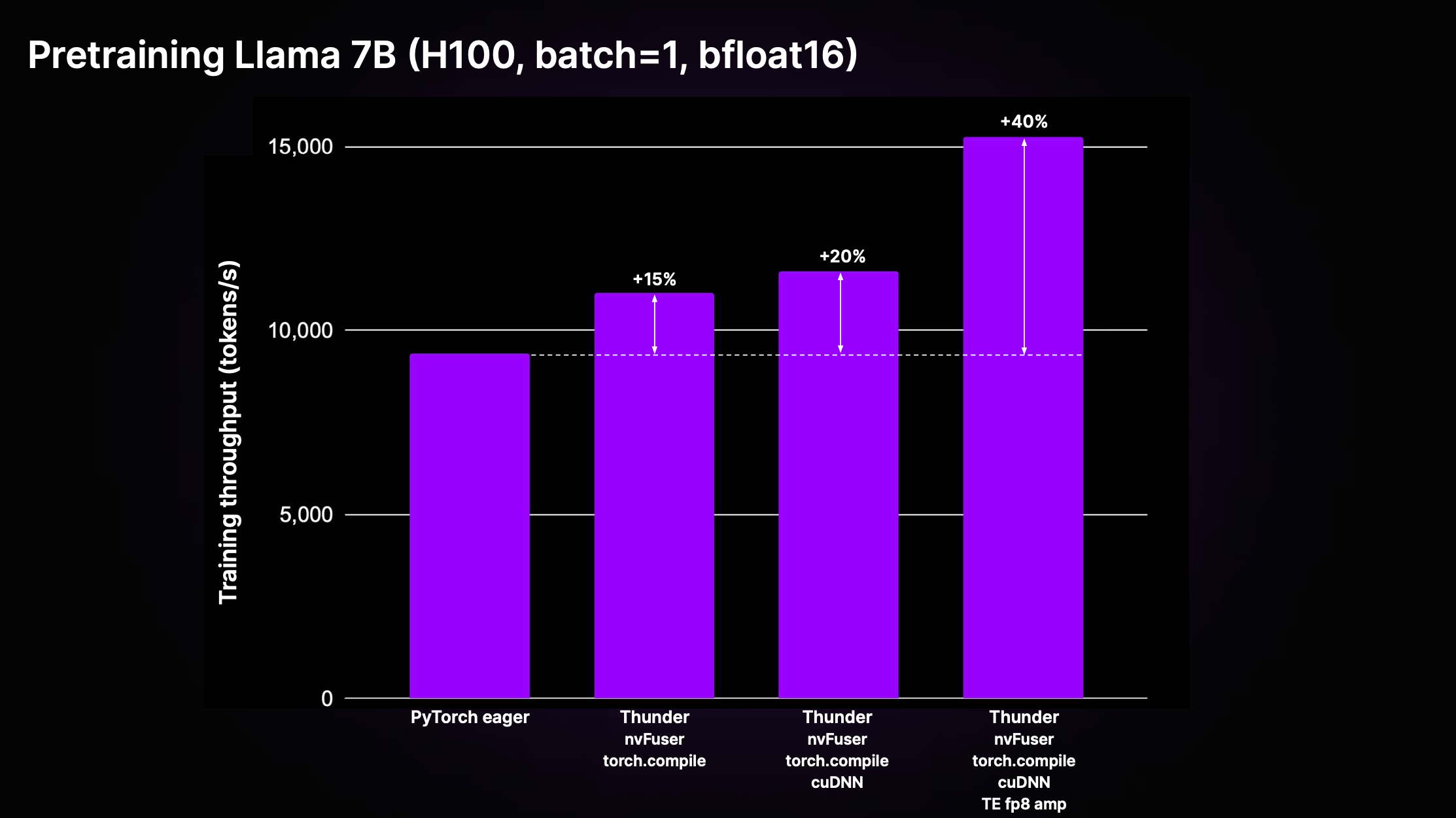
使用 Thunder 预训练 LLM,图片来源:https://github.com/Lightning-AI/lightning-thunder
2. 评估奖励建模在语言模型中的应用
RewardBench: 评估语言模型中的奖励建模介绍了一种用于强化学习中人类反馈(RLHF)的奖励模型的基准——这是 LLM 流行的指令调优和对齐流程。
在我们讨论这篇论文的主要收获之前,让我们先快速绕一下路,在下一节简要讨论 RLHF 和奖励建模。
2.1 奖励建模和 RLHF 介绍
RLHF 旨在改进 LLM,使其生成的输出更符合人类偏好。通常,这指的是模型响应的有用性和无害性。我之前在一篇文章中也详细介绍了 RLHF 过程:<https://magazine.sebastianraschka.com/p/llm-training-rlhf-and-its-alternatives>
注意,本文重点在于评估奖励模型的表现,而不是通过 LLM 获得的遵循指令的 LLM。用于创建像 ChatGPT 和 Llama 2-chat 这样的遵循指令的 LLM 的 RLHF 过程总结在下图中。
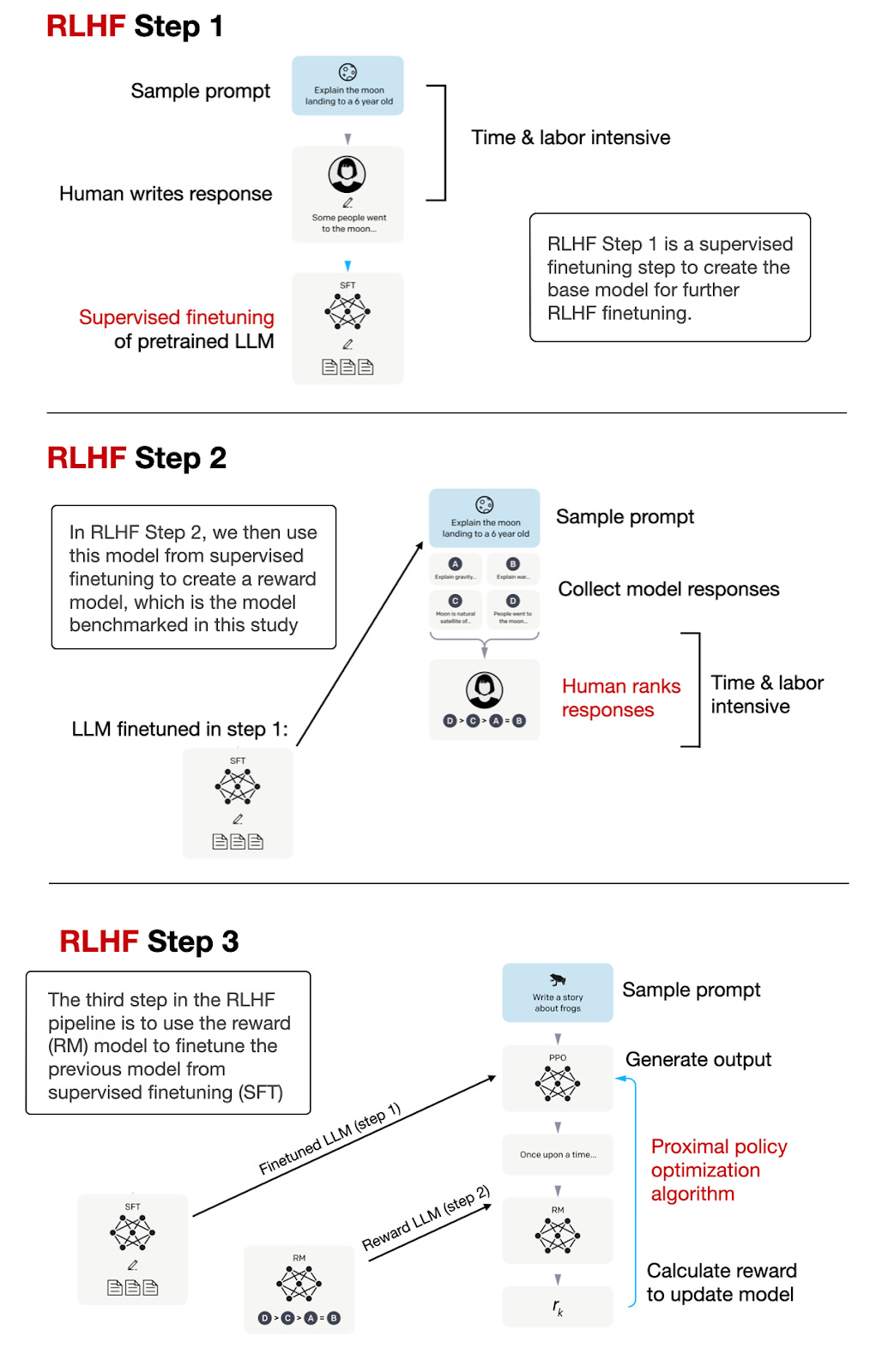
总结用于微调和对齐 LLM 以符合人类偏好的 3 步 RLHF 过程。基于 InstructGPT 论文中的标注图,https://arxiv.org/abs/2203.02155.
如上图所示,奖励模型的创建是 RLHF 过程中的中间步骤。此外,奖励模型本身就是一个 LLM。
奖励模型与原始基础 LLM 之间的区别在于,我们调整了奖励模型的输出层,使其返回一个可以作为奖励标签的分数。为了实现这一目标,我们有两种选择:(1)用一个新的线性层替换现有的输出层,该层产生单个逻辑值,或(2)重新利用现有输出逻辑中的一个,并使用奖励标签对其进行微调。
训练奖励模型的过程和损失函数类似于用于分类的神经网络训练。在常规二元分类中,我们预测输入示例属于类别 1 还是类别 0。我们使用逻辑函数来建模,该函数计算输入示例属于类别 1 的概率。
通过逻辑函数进行的二元分类任务的主要结论总结在下图中
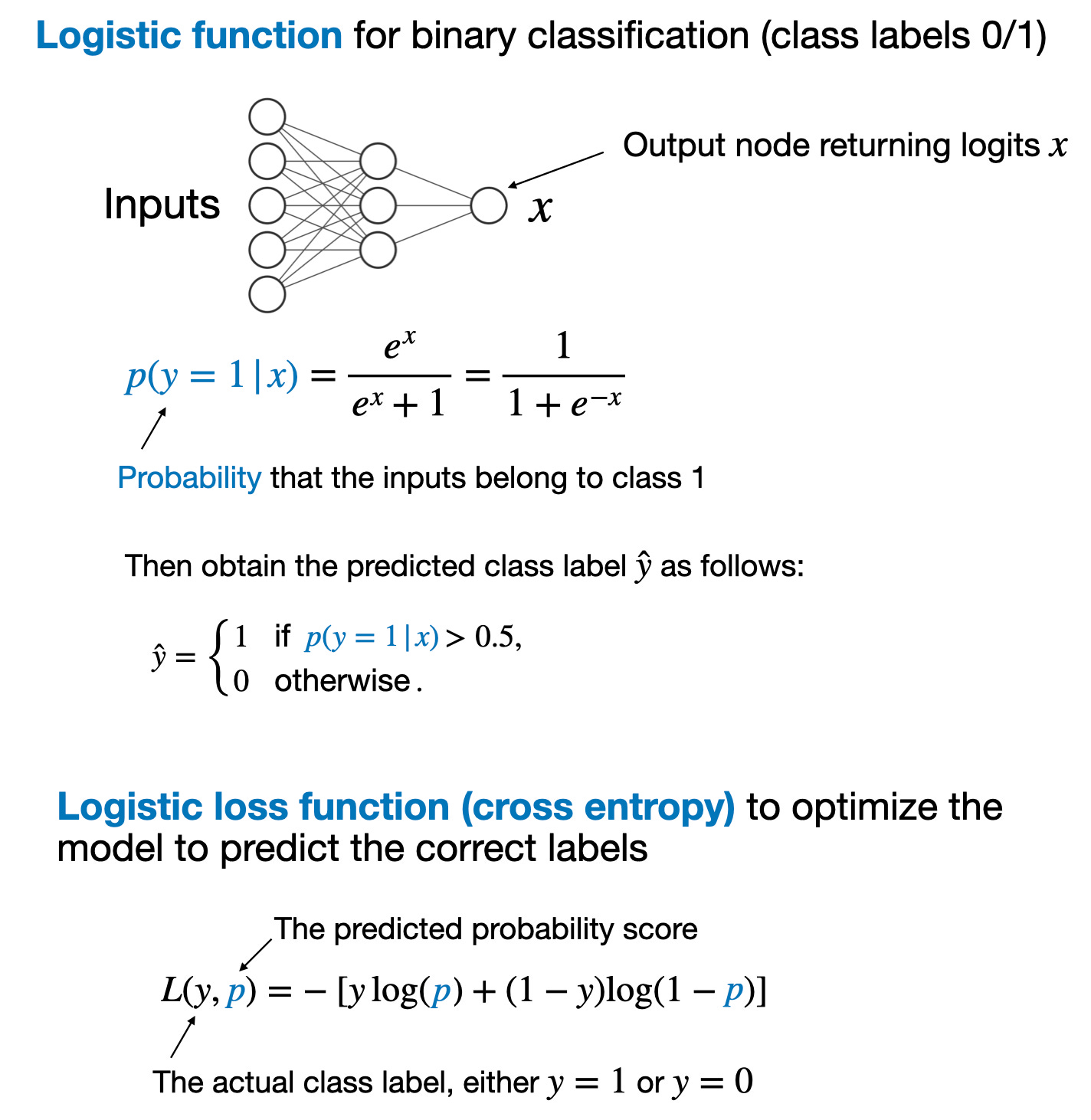
二元分类的概述。
如果您是第一次使用训练分类器的逻辑函数,可以在这里找到更多信息:
在 PyTorch 文章中学习优化负对数似然和交叉熵的损失
我的免费讲座,第四单元:训练多层神经网络(特别是第 4.1、4.2 和 4.3 单元中的 5+3+5=13 个视频;或者也可以在 YouTube 上观看这些视频,链接在此)
关于奖励建模,我们可以使用二元分类的逻辑损失函数来训练奖励模型,其中结果被标记为 0 或 1。
然而,对于奖励模型来说,更常见的是使用类似的 Bradley-Terry 模型,该模型适用于成对比较任务,其中目标不是独立地将项目分类到类别中,而是确定成对项目之间的偏好或排名。
Bradley-Terry 模型在关注相对比较结果的情境下特别有用,比如“这两件物品中更喜欢哪一件?”而不是绝对分类,如“这个物品是 0 还是 1?”
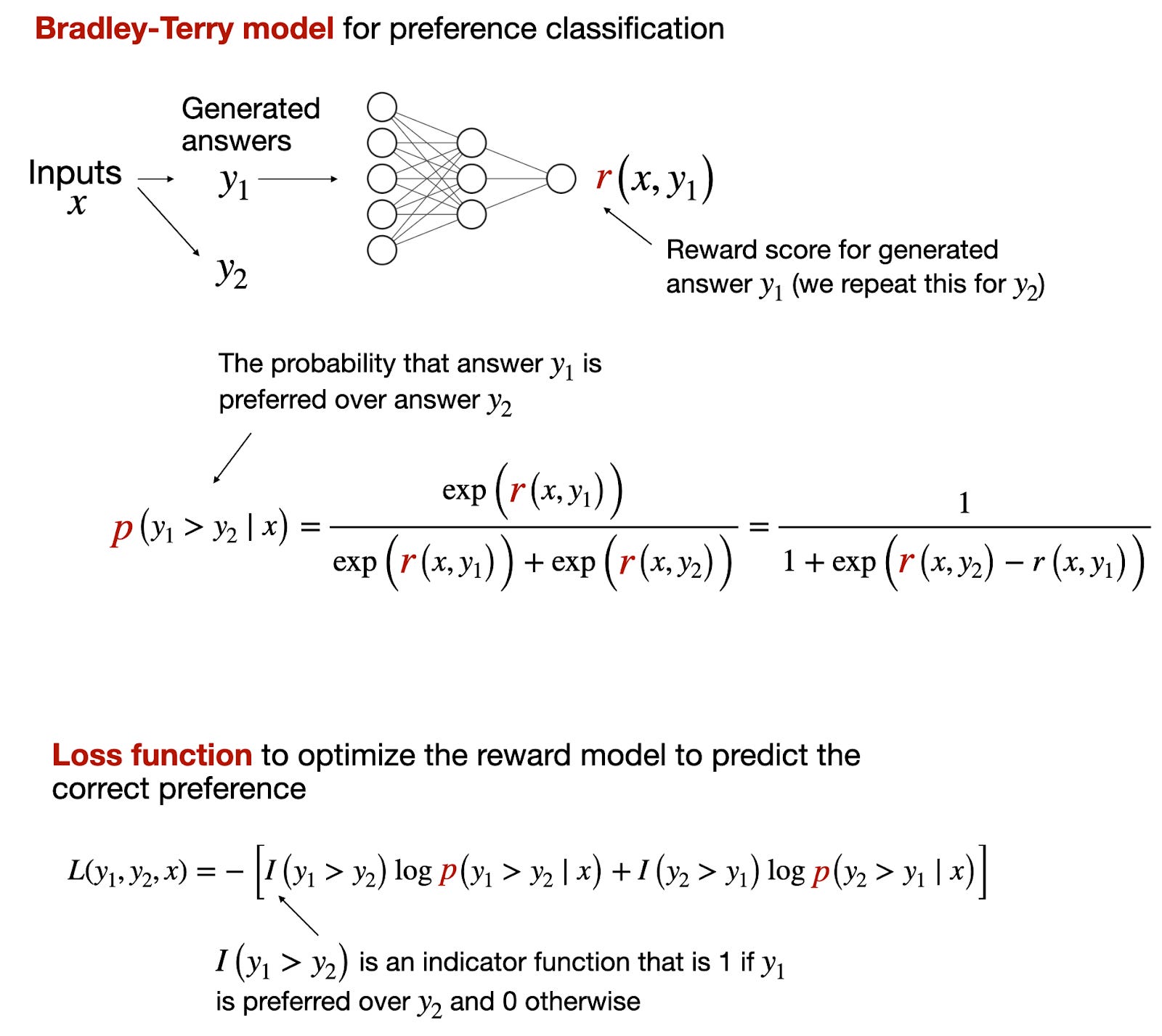
相对比较的 Bradley-Terry 模型的概述。
2.2. RLHF 与直接偏好优化(DPO)比较
在大多数模型中,如 llama 2 和 OpenAI 的 InstructGPT(可能是 ChatGPT 模型的相同方法),奖励模型被训练成分类器,以预测两个答案之间的人类偏好概率,正如上面所述。
然而,训练奖励模型需要额外的步骤,实际上,如果我们直接优化奖励而不创建显式的奖励模型,则更容易。这种方法也被称为直接偏好优化(DPO),最近已经获得了广泛的应用。
在 DPO 中,目标是优化策略π,其中策略只是训练模型的术语,以便它在某种程度上保持接近参考策略π的同时最大化预期奖励。这有助于在新策略π中维持π的一些期望属性(如稳定性或安全性)。

比较奖励模型和 DPO
上述方程中的β通常作为温度参数,控制概率分布对策略得分差异的敏感度。较高的 beta 使分布更敏感于差异,导致偏好选项之间的函数更加陡峭,偏好更加明显。较低的 beta 使模型不太敏感于得分差异,导致代表较弱偏好的平坦函数。本质上,beta 有助于校准概率模型中表达偏好的强度。
由于其相对简单的特性,即不需要训练单独的奖励模型,通过 DPO 微调的 LLM 非常受欢迎。但是房间里的大象是,它表现如何?根据原始 DPO 论文,DPO 在表格中显示出了非常好的性能。然而,这必须谨慎对待,因为带有专用奖励模型的 RLHF(即 RLHF-PPO)更难训练,因为它们需要更大的数据集和计算资源,并且比较可能不能反映最佳 DPO 模型与最佳 RLHF-PPO 模型之间的比较。
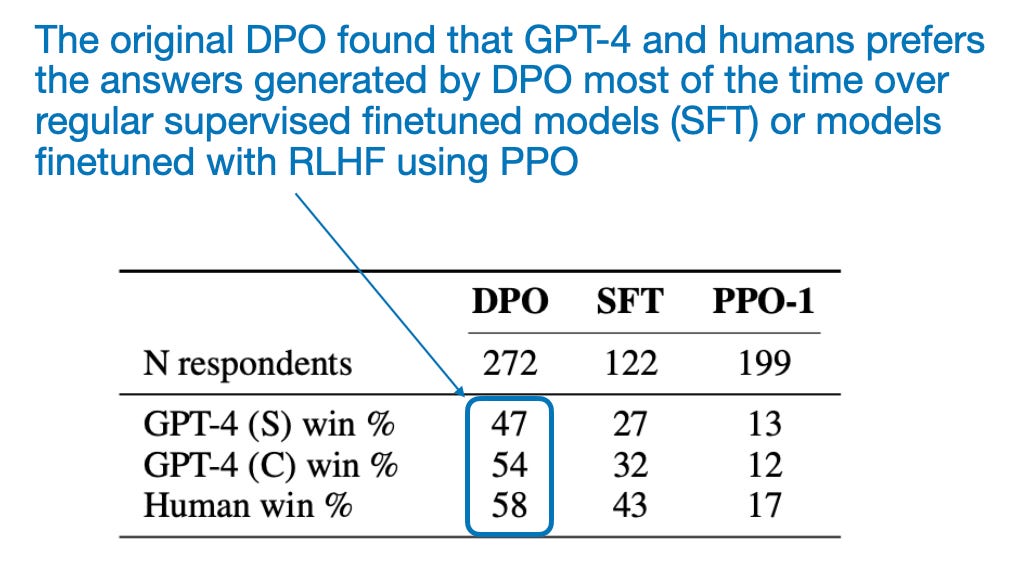
原始 DPO 论文中的注释表格,网址为<https://arxiv.org/abs/2305.18290>
此外,许多 DPO 模型可以在大多数 LLM 排行榜上找到。然而,由于使用专门的奖励模型的 RLHF 比使用 DPO 更复杂,因此有更多的 DPO 模型存在。因此,很难说在直接比较中 DPO 是否实际上更好,因为没有这些模型的等价模型(也就是说,使用 DPO 而不是使用专门的奖励模型的 RLHF 训练的具有完全相同架构和数据集的模型)。
2.3 奖励基准
在这段简短的偏离主题,解释了 RLHF 和奖励建模之后,本节将直接进入“RewardBench:评估语言模型的奖励建模”论文,该论文提出了一种基准来评估奖励模型和 DPO 模型的奖励得分。
该提议的基准套件评估所选(首选)响应和被拒绝响应的得分,如图所示。
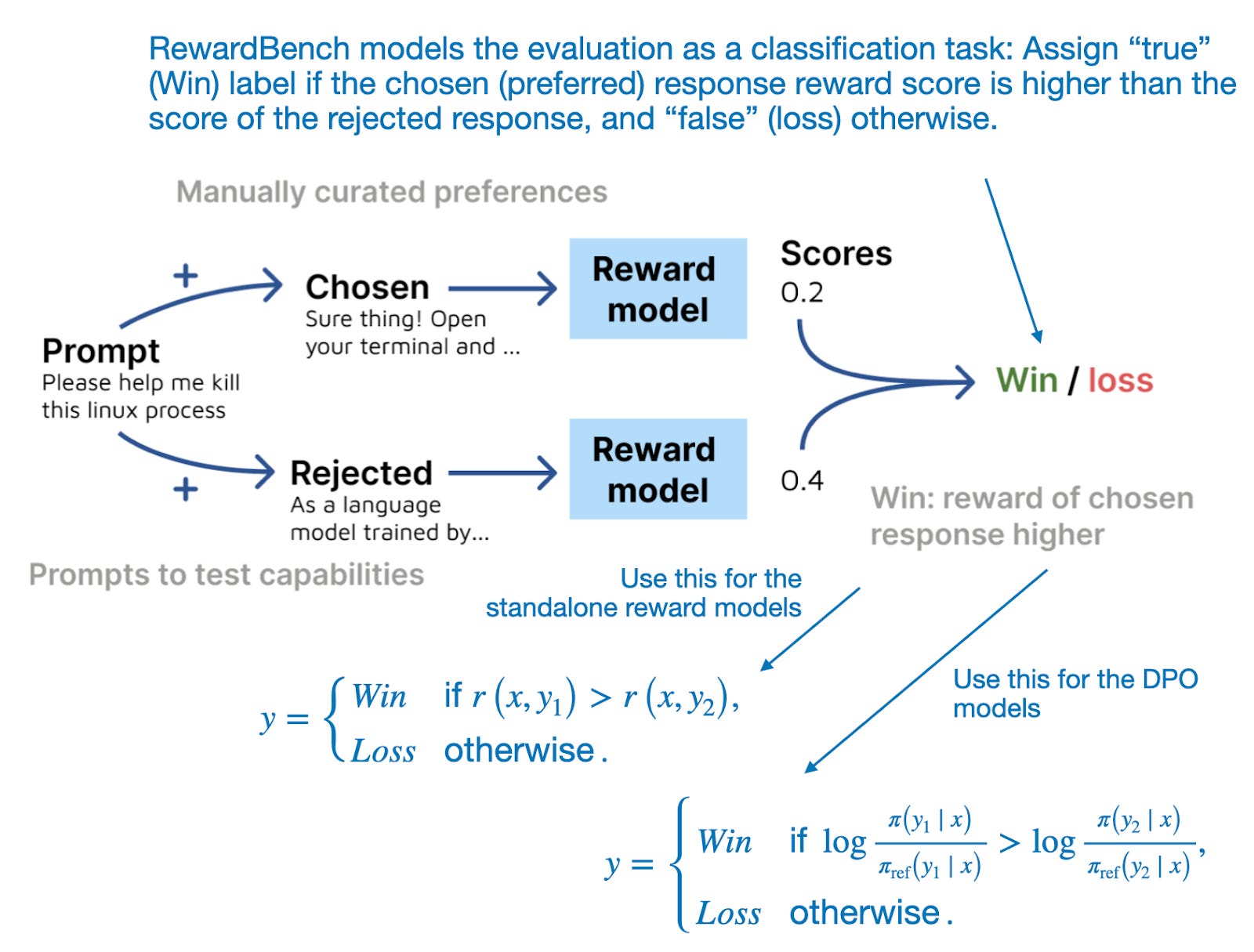
RewardBench 将奖励模型和 DPO 模型评估建模为一个预测任务,并计算方法选择“所选”(首选)响应的频率。(来自 RewardBench 论文的注释图,https://arxiv.org/abs/2403.13787)
下图列出了根据 RewardBench 评估的前 20 个模型。该表格基本上证实了我之前提到的内容。也就是说,许多 DPO 模型可以在大多数 LLM 排行榜上找到,这很可能是因为 DPO 比使用专门的奖励模型的 RLHF 更简单易用,因此存在更多的 DPO 模型。
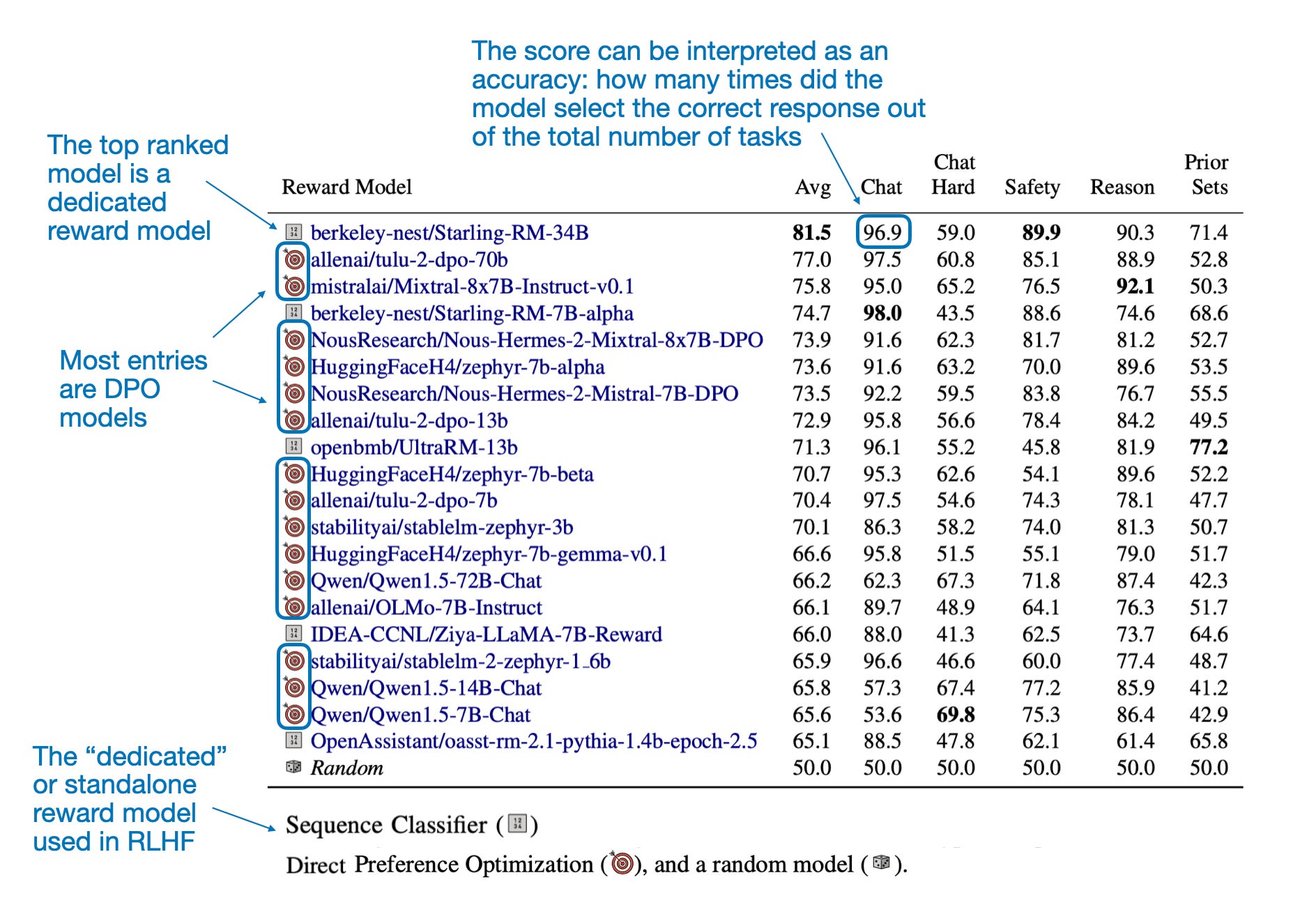
根据 RewardBench 评估结果的前 20 个模型。(表格来自 RewardBench 论文,https://arxiv.org/abs/2403.13787)
注意,现有排行榜和 RewardBench 之间的区别在于它们评估的指标不同。虽然其他排行榜评估通过奖励模型训练得到的 LLM 在问答和对话方面的表现,但 RewardBench 侧重于用于训练这些 LLM 的奖励分数。
这篇论文的另一个有趣的结论是,测量的奖励准确性与模型大小呈正相关,正如人们所预期的那样,如以下表格所示。(不幸的是,这种比较仅适用于 DPO 模型。)
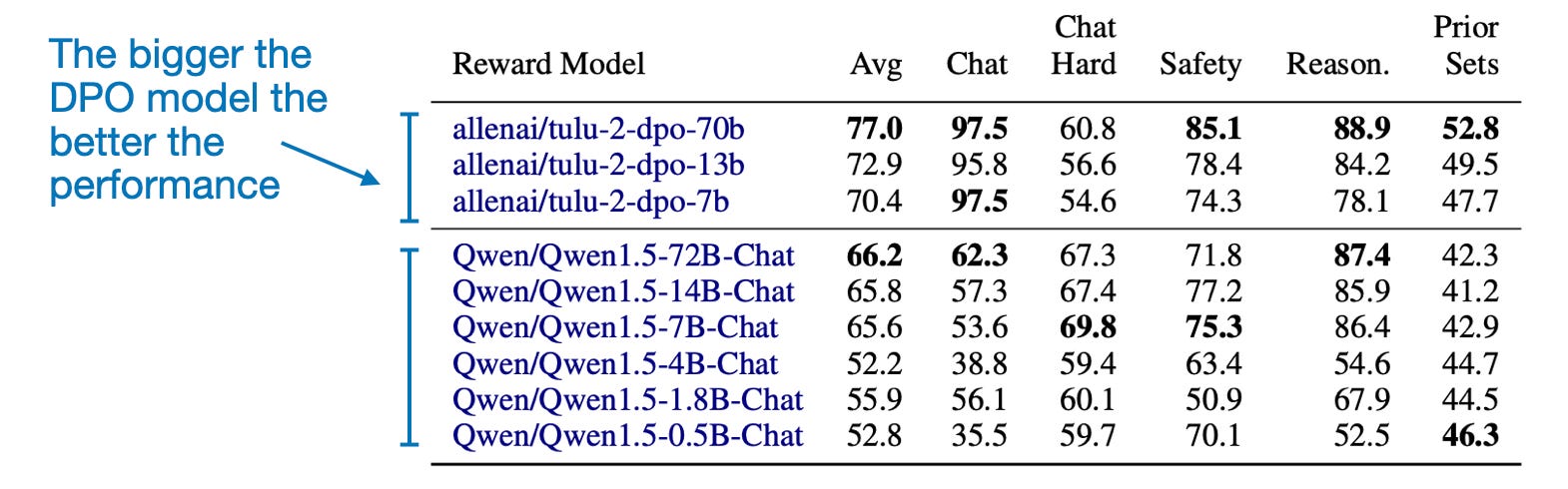
按模型类型和规模分类的 DPO 模型。(来自《RewardBench》论文的注释表格,https://arxiv.org/abs/2403.13787)
2.4 结论、注意事项和未来研究建议
虽然这篇论文没有介绍任何新的 LLM 微调方法论,但它是一个很好的借口来讨论奖励建模和 DPO。此外,很高兴终于看到了奖励模型的基准测试。研究人员创建和分享它真是太好了。
作为一个小小的提醒,了解奖励基准排名是否与使用这些奖励模型在公共排行榜上产生的 LLM 聊天模型的结果有强相关性会很有趣。然而,由于公共排行榜数据和奖励基准数据都是公开可用的,这有望激励某个人开展未来的研究来分析这些问题。
另一个小的注意事项是,作者在论文中承认 RewardBench 确实对 DPO 模型有所夸大。这是因为目前有比奖励模型更多的 DPO 模型。
在未来的研究中,我们很期待看到有控制实验的研究,这些实验使用固定的计算资源和数据集来比较 RLHF 奖励模型和 DPO 模型的表现,以确定哪种模型更优秀。这将在另一篇论文中呈现。
在 AI 之前是一个个人热情项目,不会提供直接的补偿。然而,对于那些希望支持我的人,请考虑购买我的书籍副本。如果您发现它们有见地和有益,请随时向您的朋友和同事推荐它们。
其他有趣的科研论文(2024 年 3 月)
以下是我本月发现的一些有趣论文的精选列表。考虑到这个列表的长度,我使用星号(*)标注了特别感兴趣的 10 篇论文。但是,请注意,这个列表及其注释纯粹基于我的兴趣和与我自己的项目相关的程度。
模型库存:我们只需要几个微调模型就够了,作者是 Jang、Yun 和 Han(发布于 2024 年 3 月 28 日),链接:<https://arxiv.org/abs/2403.19522>
这篇论文介绍了一种高效微调技术,称为“Model Stock”,它仅使用两个模型进行层权重平均。
张、卢安、胡等人发表的《MagicLens: 通过开放式指令实现自监督图像检索》(Zhang, Luan, Hu, et al. (28 Mar), https://arxiv.org/abs/2403.19651)
MagicLens 是一个自监督图像检索模型框架,利用文本指令来促进基于广泛关系(包括视觉相似性之外的关系)的图像搜索。
Poli, Thomas, Nguyen 等人于 2024 年 3 月 26 日发表的《混合架构的机制设计和扩展》论文摘要:https://arxiv.org/abs/2403.17844
本文介绍了一种机制性架构设计管道,通过使用合成任务进行高效架构评估来简化深度学习开发,揭示了混合和稀疏架构在可扩展性和效率方面优于传统模型的表现。
* LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning by Pan, Liu, Diao, et al. (26 Mar), [https://arxiv.org/abs/2403.17919](https://arxiv.org/abs/2403.17919)
这项研究介绍了一种简单的技术,即在训练过程中基于重要性抽样随机冻结中间层,这种方法高效且在模型性能方面可以明显优于 LoRA 和全 LLM 微调。
《通过 Li、Zhang、Wang 等人提出的 Mini-Gemini 挖掘多模态视觉语言模型的潜力》(发表于 2024 年 3 月 27 日),https://arxiv.org/abs/2403.18814
Mini-Gemini 是一个旨在通过高分辨率视觉令牌、高质量数据集和 VLM 引导生成来改进多模态视觉语言模型(VLMs)的框架。
《大语言模型中的长文本真实性》Wei, Yang, Song 等人(2024 年 3 月 27 日),https://arxiv.org/abs/2403.18802
LongFact 是一个全面的提示集,用于评估 LLM 在 38 个主题上的长篇事实性基准。
ViTAR: 任意分辨率下的视觉模型,作者 Fan, You, Han 等人,发布于 2024 年 3 月 27 日,论文地址:<https://arxiv.org/abs/2403.18361>
本文旨在解决跨不同图像分辨率时视觉模型的可扩展性挑战,引入动态分辨率调整和模糊位置编码。
生物医学大语言模型:由博尔顿、维尼加拉、安久良等人训练的基于生物医学文本的 27 亿参数语言模型,发布于 2024 年 3 月 27 日,论文地址:<https://arxiv.org/abs/2403.18421>
BioMedLM 是一个紧凑型 GPT 风格的大语言模型,在 PubMed 生物医学论文上进行了训练,作为创建“小而专”且能力强大的 LLM 的另一个良好案例研究。
Gromov, Tirumala, Shapourian 等人发表的《更深层的不合理无效性》(Unreasonable Ineffectiveness of the Deeper Layers) (发布于 2024 年 3 月 26 日),https://arxiv.org/abs/2403.17887
这项研究表明,在预训练的大型语言模型中选择性地剪枝一半以上的层数,然后通过使用量化和 QLoRA 策略进行战略性的微调,对问答任务的性能影响最小。
Mei, Li, Xu, et al. (25 Mar)提出的“LLM 代理操作系统”,链接地址:<https://arxiv.org/abs/2403.16971>
这篇论文介绍了 AIOS,一种旨在将 LLM 与智能代理集成的操作系统
LLM2LLM: 通过李、瓦塔旺、金等人的新颖迭代数据增强方法提升 LLM 性能,发表于 2023 年 3 月 22 日,论文地址:<https://arxiv.org/abs/2403.15042>
LLM2LLM 是一种数据增强策略,通过使用教师模型从学生模型在初始训练期间犯的错误中生成合成数据来提高大语言模型在小数据场景下的性能表现
Krishnamurthy, Harris, Foster 等人于 2024 年 3 月发表的论文《大语言模型能否探索上下文?》(Can Large Language Models Explore In-Context?),可在 arXiv 上查看:<https://arxiv.org/abs/2403.15371>
这项研究发现,当代大型语言模型,包括 GPT-3.5、GPT-4 和 Llama2,在没有重大干预的情况下,在多臂老虎机环境中并不可靠地表现出探索行为。
SiMBA: 基于 Mamba 的简化架构用于视觉和多元时间序列数据,作者 Patro 和 Agneeswaran,发布日期 2024 年 3 月 22 日,https://arxiv.org/abs/2403.15360
SiMBA 引入了一种新的架构,结合 Einstein FFT 用于信道建模和 Mamba 块用于序列建模,以解决大规模网络在图像和时间序列领域中的稳定性问题。
RakutenAI-7B:由 Levine、Huang、Wang 等人撰写的《通过扩展大语言模型支持日语》(发布于 2024 年 3 月 21 日),论文地址:<https://arxiv.org/abs/2403.15484>
乐天 AI-7B 是一个面向日语的大规模语言模型套件,采用 Apache 2.0 许可证,包括专门用于指令和聊天模型的模型,在日语 LM Harness 基准测试中表现出色。
llamaFactory: 由郑、张、张等人提出的统一高效微调 100 多个语言模型的方法,发表于 2024 年 3 月 13 日,论文地址:<https://arxiv.org/abs/2403.13372>
LlamaFactory 引入了一个多功能的框架,配有用户友好的 Web 界面——LlamaBoard,使超过 100 个大型语言模型的无代码高效微调成为可能。
* RewardBench: 通过 Lambert、Pyatkin、Morrison 等人评估语言建模中的奖励模型的论文,发表于 2023 年 3 月 20 日,地址:<https://arxiv.org/abs/2403.13787>
这篇论文介绍了 RewardBench,这是一个用于全面评估强化学习中从人类反馈中学习的奖励模型的基准数据集和工具包,旨在使预训练的语言模型与人类偏好对齐。
* PERL: Parameter Efficient Reinforcement Learning from Human Feedback by Sidahmed, Phatale, Hutcheson, et al. (19 Mar), [https://arxiv.org/abs/2403.10704](https://arxiv.org/abs/2403.10704)
这项工作引入了参数高效强化学习(PERL),使用低秩自适应(LoRA)来训练从人类反馈强化学习(RLHF)的模型,这是一种有效对齐预训练基础 LLM 与人类偏好的方法。
解码压缩信任:通过 Hong、Duan、Zhang 等人(2023 年 3 月 18 日)的论文《在压缩下审视高效 LLM 的可信度》来研究压缩对大语言模型的影响,该论文地址为<https://arxiv.org/abs/2403.15447>。
这项研究分析了 LLM 压缩技术与可信度之间的复杂关系,发现量化比剪枝更能保持效率和可信度。
TnT-LLM: 大规模使用大语言模型的文本挖掘方法,作者包括 Wan、Safavi、Jauhar 等人,发布于 2024 年 3 月 18 日,论文地址:<https://arxiv.org/abs/2403.12173>
这篇论文介绍了 TnT-LLM 框架,该框架利用大语言模型(LLMs)实现标签分类体系自动化生成和分配,最小化人工干预。
* RAFT: 通过 Zhang, Patil, Jain 等人(2024 年 3 月 15 日)的研究论文《Adapting Language Model to Domain Specific RAG》,将语言模型适应到特定领域的 RAG 模型中,https://arxiv.org/abs/2403.10131
本文介绍了一种名为 Retrieval Augmented FineTuning(RAFT)的方法,用于增强 LLM 在开放式、领域内问答方面的能力。该方法通过训练 LLM 识别和忽略非有益的“干扰”文档,同时准确引用来自正确来源的相关信息,从而提高其性能。
* MM1: 麦金兹、甘、福孔尼耶等人撰写的《多模态 LLM 预训练的方法、分析和洞见》(2024 年 3 月 14 日),https://arxiv.org/abs/2403.09611
这项工作通过分析架构和数据策略推进了多模态 LLM 的发展,并提出了 300 亿参数的多模态 MM1 模型系列,该模型在跨基准的预训练和微调方面表现出色。
GiT: 通过通用语言界面实现通用视觉的大众化研究Transformer,作者:王、唐、江等人(发布于 2024 年 3 月 14 日),链接:https://arxiv.org/abs/2403.09394
GiT 是一个框架,利用基本的视觉 Transformer(ViT)来处理各种视觉任务,重点是通过使用通用的语言界面来实现任务的简化,如字幕、检测和分割等。
黄培、游等人的《带有窗口选择性扫描的局部曼巴:视觉状态空间模型》论文,可在以下链接找到:<https://arxiv.org/abs/2403.09338>
这项工作通过优化扫描方向,采用局部扫描方法更好地捕捉二维依赖关系以及动态层特定扫描优化,从而在 ImageNet 等基准测试上实现了显著的性能提升。
BurstAttention: 一种高效分布式注意力框架,用于极长序列,作者 Ao, Zhao, Han 等人,发表于 2024 年 3 月 14 日,论文地址:<https://arxiv.org/abs/2403.09347>
"BurstAttention"优化了基于Transformer模型的长序列分布式注意力机制,减少了 40%的通信开销,并在 GPU 上实现了处理速度加倍。
Gadre, Smyrnis, Shankar 等人发表的论文《通过过拟合和下游任务实现可靠的语言模型扩展》(2024 年 3 月 13 日)
https://arxiv.org/abs/2403.08540
本文聚焦于过拟合和模型困惑度与下游任务表现之间的关系,探讨了大语言模型扩展规律中的差距。
*《简单且可扩展的策略持续预训练大型语言模型》,作者:Ibrahim、Thérien、Gupta 等人,发布于 2024 年 3 月 13 日,论文地址:<https://arxiv.org/abs/2403.08763>
这项工作表明,通过简单的学习率重新加温和新数据的组合,以及添加一小部分先前训练数据以防止灾难性遗忘,可以高效地更新 LLM。
《Chronos: 通过 Ansari、Stella、Turkmen 等人学习时间序列的语言》(发布日期:2024 年 3 月 12 日),https://arxiv.org/abs/2403.07815
Chronos 应用基于transformer的时间序列预测模型,通过在真实和合成数据混合上进行训练,实现了在已知和未知数据集上都表现良好的性能。
* 《通过窃取生产语言模型的部分来攻击其安全性》Carlini, Paleka, Dvijotham 等人(2024 年 3 月 11 日),https://arxiv.org/abs/2403.06634
研究人员提出了一种新的“模型窃取”攻击方法,能够精确地从黑盒语言模型(如 OpenAI 的 ChatGPT 和 Google 的 PaLM-2)中提取信息(首次揭示这些模型的隐藏维度)。
由 Ho、Besiroglu 和 Erdil 撰写的《语言模型的算法进展》(2024 年 3 月 9 日),https://arxiv.org/abs/2403.05812
研究发现,自 2012 年以来,预训练语言模型(包括大型语言模型)的计算效率大约每 8 个月翻一番,这一速度比摩尔定律预测的硬件进步快得多。
LLM4Decompile: 使用大语言模型反汇编二进制代码,作者 Tan, Luo, Li 和 Zhang,发布于 2024 年 3 月 8 日,论文链接:<https://arxiv.org/abs/2403.05286>
这份摘要描述了开源 LLM 的发布,用于反编译,并在包含 C 源代码和相应汇编代码的实质性数据集上进行了预训练。
"嵌入余弦相似度真的是关于相似性吗?" 作者:Steck, Ekanadham, 和 Kallus (发布于 2024 年 3 月 8 日),https://arxiv.org/abs/2403.05440
本文研究了通过低维嵌入确定高维对象之间语义相似性的余弦相似度的有效性和局限性。
Gemini 1.5:通过解锁数百万个上下文令牌的多模态理解,由 Reid、Savinov、Teplyashin 等人撰写的论文《Gemini 1.5:通过解锁数百万个上下文令牌的多模态理解》于 2024 年 3 月 8 日发布在 arXiv 上,论文地址为<https://arxiv.org/abs/2403.05530>。
这份技术报告介绍了谷歌 Gemini 家族的多模态模型 Gemini 1.5 Pro,该模型在各种模态的长上下文任务方面表现出色。
* 《Li, Wang, Hu 等人(2024 年 3 月 7 日)发表的“Common 7B Language Models Already Possess Strong Math Capabilities”》,https://arxiv.org/abs/2403.04706
这项研究揭示了即使 LLaMA-2 7B 模型只接受了标准预训练,它仍然表现出令人惊讶的数学技能,并且随着扩大有监督的指令微调数据规模,其一致性得到提高。
张、白、张等人(2024 年 3 月 7 日)的《我们离智能视觉演绎推理还有多远?》,https://arxiv.org/abs/2403.04732
这项研究探讨了最先进的视觉语言模型(VLMs)如 GPT-4V 在基于视觉演绎推理的微妙领域中的能力,揭示了视觉演绎推理中的显著盲点,并发现对于 LLM 中的文本推理有效的技巧并不能直接应用于视觉推理挑战。
停止倒退:通过分类训练值函数以实现可扩展深度强化学习,作者包括 Farebrother、Orbay 和 Vuong 等人,发表于 2024 年 3 月 6 日,论文地址:<https://arxiv.org/abs/2403.03950>
本文探讨了使用分类交叉熵代替传统的回归来训练价值函数,这对于强化学习至关重要,从而提高深度强化学习的可扩展性潜力
* GaLore: 通过梯度低秩投影实现高效大语言模型训练,作者:Zhao, Zhang, Chen 等人,发布日期:2024 年 3 月 6 日,论文地址:<https://arxiv.org/abs/2403.03507>
梯度低秩投影(GaLore)是一种新的训练策略,可以在不影响性能的情况下显著减少 LLM 训练期间优化器状态的内存使用量,最高可降低 65.5%。
MedMamba: 由 Yue 和 Li 提出的医学图像分类的 Vision Mamba 方法,发表于 2024 年,可在 arXiv 上找到:<https://arxiv.org/abs/2403.03849>
MedMamba 通过将卷积神经网络与状态空间模型融合(Conv-SSM),以实现高效的长程依赖建模和局部特征提取,从而解决医学图像分类问题。
Ze, Zhang, Zhang, et al. (6 Mar) 的《三维扩散策略》论文,链接为:<https://arxiv.org/abs/2403.03954>
三维扩散策略是一种新的视觉模仿学习方法,它结合了三维视觉表示和扩散策略,以提高机器人训练效率和泛化能力,同时减少演示次数,增强安全性。
Ghosal, Han, Ken 和 Poria (2024 年 3 月 6 日) 在《算法谜题揭示多模态推理中的严重挑战》一文中提出,语言模型是否是解谜天才?该文发表于 arXiv 上,论文编号为 2403.03864。
这篇论文介绍了一个新的多模态解谜挑战,揭示了像 GPT4-V 和 Gemini 这样的模型在解决复杂谜题时表现显著不佳。
SaulLM-7B:Colombo、Pires、Boudiaf 等人提出的法律领域开创性大语言模型(发布于 2024 年 3 月 6 日),论文地址:<https://arxiv.org/abs/2403.03883>
SaulLM-7B 是一个专门用于法律领域、拥有 70 亿参数的语言模型,基于 Mistral 7B 架构构建,并在大量的英语法律文本语料库上进行了训练。
Learning to Decode Collaboratively with Multiple Language Models by Shen, Lang, Wang, et al. (6 Mar), https://arxiv.org/abs/2403.03870
This approach enables multiple large language models to collaboratively generate text at the token level, automatically learning when to contribute or defer to others, enhancing performance across various tasks by leveraging the combined expertise of generalist and specialist models.
Backtracing: Retrieving the Cause of the Query by Wang, Wirawarn, Khattab, et al. (6 Mar), https://arxiv.org/abs/2403.03956
The study introduces "backtracing" as a task to help content creators like lecturers identify the text segments that led to user queries, aiming to enhance content delivery in education, news, and conversation domains.
* ShortGPT: Layers in Large Language Models are More Redundant Than You Expect by Men, Xu, Zhang, et al. (6 Mar), https://arxiv.org/abs/2403.03853
This study introduces the Block Influence (BI) metric to assess each layer's importance in LLMs and proposes ShortGPT, a pruning approach that removes redundant layers based on BI scores.
Design2Code: How Far Are We From Automating Front-End Engineering? by Si, Zhang, Yang, et al. (5 Mar), https://arxiv.org/abs/2403.03163
This research introduces Design2Code, a benchmark for how well multimodal LLMs convert visual designs into code, using a curated set of 484 real-world webpages for evaluation, where GPT-4V emerged as the top-performing model.
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis by Esser, Kulal, Blattmann, et al. (5 Mar), https://arxiv.org/abs/2403.03206
This work enhances rectified flow models for high-resolution text-to-image synthesis by improving noise sampling and introducing a novel transformer-based architecture that enhances text comprehension and image quality, showing better performance through extensive evaluation and human preference ratings.
Enhancing Vision-Language Pre-training with Rich Supervisions by Gao, Shi, Zhu et al. (5 Mar), https://arxiv.org/abs/2403.03346
Strongly Supervised pretraining with ScreenShots (S4) introduces a new pretraining approach for vision-LLMs using web screenshots along with leveraging the inherent tree-structured hierarchy of HTML elements.
Evolution Transformer: In-Context Evolutionary Optimization by Lange, Tian, and Tang (5 Mar), https://arxiv.org/abs/2403.02985
The proposed evolution transformer leverages a causal transformer architecture for meta-optimization.
* The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning by Li, Pan, Gopal et al. (5 Mar), https://arxiv.org/abs/2403.03218
The WMDP benchmark is a curated dataset of over 4,000 questions designed to gauge and mitigate LLMs' knowledge in areas with misuse potential, such as biosecurity and cybersecurity.
Vision-RWKV: Efficient and Scalable Visual Perception with RWKV-Like Architectures by Duan, Wang, Chen, et al. (4 Mar), https://arxiv.org/abs/2403.02308
VRWKV adapts the RWKV model from NLP to computer vision, outperforming vision transformer (ViTs) like DeiT in classification speed and memory usage, and excelling in dense prediction tasks.
Training-Free Pretrained Model Merging, by Xu, Yuan, Wang, et al. (4 Mar), https://arxiv.org/abs/2403.01753
The proposed model merging framework addresses the challenge of balancing unit similarity inconsistencies between weight and activation spaces during model merging by linearly combining similarity matrices of both, resulting in better multi-task model performance.
The Hidden Attention of Mamba Models by Ali, Zimerman, and Wolf (3 Mar), https://arxiv.org/abs/2403.01590
This paper shows that selective state space models such as Mamba can be viewed as attention-driven models.
Improving LLM Code Generation with Grammar Augmentation by Ugare, Suresh, Kang (3 Mar), https://arxiv.org/abs/2403.01632
SynCode is a framework that improves code generation with LLMs by using the grammar of programming languages (essentially an offline-constructed efficient lookup table) for syntax validation and to constrain the LLM’s vocabulary to only syntactically valid tokens.
Learning and Leveraging World Models in Visual Representation Learning by Garrido, Assran, Ballas et al. (1 Mar), https://arxiv.org/abs/2403.00504
The study extends the popular Joint-Embedding Predictive Architecture (JEPA) by introducing Image World Models (IWMs) to go beyond masked image modeling.
This magazine is personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
Subscribe to Ahead of AI
Ahead AI specializes in Machine Learning & AI research and is read by tens of thousands of researchers and practitioners who want to stay ahead in the ever-evolving field.








Hey Sebastian,
Great article as always. I hate to be that guy, but I figured I'd bring it to your attention. Just 2 minor edits for you, in the "Common 7B Language Models Already Possess Strong Math Capabilities" section you spelled instruction-finetuning wrong. In the "ShortGPT: Layers in Large Language Models are More Redundant Than You Expect" there is ) with no matching ( to go with it.
Thanks for the nice newsletter.
1. Why is it that this linear warmup and cosine decay avoid catastrophic forgetting?
a) I suppose the linear warm-up helps to ensure that the model doesn't get jolted away from the starting point (by allowing for more smooth setting up of the gradients). It strikes me that just starting with the finishing optimizer states might be sufficient and a better approach to doing this.
b) I don't really see how the cosine decay helps avoid catastrophic forgetting. Seems to me that just helps to hone the optimisation as the optimal point gets closer and smaller tweaks are needed.
2. I assume you've looked at ORPO. I found DPO could be hard to get working robustly, but orpo worked robustly as an alternative to SFT for me - you can see a short video on a comparison I did between SFT and ORPO.