
The Inference Cost Of Search Disruption – Large Language Model Cost Analysis
搜索中断的推理成本 - 大型语言模型成本分析
$30B Of Google Profit Evaporating Overnight, Performance Improvement With H100 TPUv4 TPUv5
300 亿美元的谷歌利润一夜之间蒸发,H100 TPUv4 TPUv5 性能提升


OpenAI’s ChatGPT took the world by storm, quickly amassing over 100 million active users in January alone. This is the fastest any application has ever grown to this size, with the prior two record keepers being TikTok at 9 months and Instagram at 2.5 years. The top question on everyone’s mind is how disruptive large language models (LLMs) will be for search. Microsoft rocked the world this week with their Bing announcement, incorporating OpenAI’s technology into search.
OpenAI 的 ChatGPT 迅速席卷全球,仅在 1 月份就迅速积累了超过 1 亿的活跃用户。这是任何应用程序达到如此规模的最快速度,之前的两个记录保持者是 TikTok,耗时 9 个月,Instagram 则耗时 2.5 年。大家最关心的问题是大型语言模型(LLMs)将对搜索产生多大的颠覆。微软本周通过其 Bing 公告震撼了世界,将 OpenAI 的技术融入搜索中。
This new Bing will make Google come out and dance, and I want people to know that we made them dance.
这个新的必应将让谷歌出来跳舞,我希望人们知道我们让他们跳舞。
Google’s recent actions make it look like they are dancing. While we believe Google has better models and AI expertise than any other firm in the world, they do not have a culture conducive to implementing and commercializing much of its leading technology. The competitive pressures from Microsoft and OpenAI are changing this rapidly.
谷歌最近的举动让人感觉他们在跳舞。虽然我们相信谷歌拥有比世界上任何其他公司更好的模型和人工智能专业知识,但他们并没有一种有利于实施和商业化其领先技术的文化。来自微软和 OpenAI 的竞争压力正在迅速改变这一点。
Disruption and innovation in search don’t come for free. The costs to train an LLM, as we detailed here, are high. More importantly, inference costs far exceed training costs when deploying a model at any reasonable scale. In fact, the costs to inference ChatGPT exceed the training costs on a weekly basis. If ChatGPT-like LLMs are deployed into search, that represents a direct transfer of $30 billion of Google’s profit into the hands of the picks and shovels of the computing industry.
搜索中的颠覆和创新并不是免费的。训练一个LLM的成本,如我们在这里详细说明的,十分高昂。更重要的是,在任何合理规模下部署模型时,推理成本远远超过训练成本。事实上,推理 ChatGPT 的成本每周都超过训练成本。如果像 ChatGPT 这样的LLMs被部署到搜索中,这将直接将 300 亿美元的谷歌利润转移到计算行业的“铲子和镐”手中。
Today we will dive into the differing uses of LLMs for search, the daily costs of ChatGPT, the cost of inference for LLMs, Google’s search disruption effects with numbers, hardware requirements for LLM inference workloads, including performance improvement figures for Nvidia’s H100 and TPU cost comparisons, sequence length, latency criteria, the various levers that can be adjusted, the differing approaches to this problem by Microsoft, Google, and Neeva, and how the model architecture of OpenAI’s next model architecture, which we detailed here dramatically reduces costa on multiple fronts.
今天我们将深入探讨LLMs在搜索中的不同用途,ChatGPT 的每日成本,LLMs的推理成本,谷歌搜索中断的影响及其数据,LLM推理工作负载的硬件要求,包括 Nvidia H100 和 TPU 成本比较的性能提升数据,序列长度,延迟标准,各种可调节的杠杆,微软、谷歌和 Neeva 在这个问题上的不同解决方案,以及 OpenAI 下一个模型架构的模型架构如何在多个方面显著降低成本。
The Search Business 搜索业务
First off, let’s define the parameters of the search market. Our sources indicate that Google runs ~320,000 search queries per second. Compare this to Google’s Search business segment, which saw revenue of $162.45 billion in 2022, and you get to an average revenue per query of 1.61 cents. From here, Google has to pay for a tremendous amount of overhead from compute and networking for searches, advertising, web crawling, model development, employees, etc. A noteworthy line item in Google’s cost structure is that they paid in the neighborhood of ~$20B to be the default search engine on Apple’s products.
首先,让我们定义搜索市场的参数。我们的来源显示,谷歌每秒处理约 320,000 个搜索查询。与谷歌搜索业务部门相比,2022 年的收入为 1624.5 亿美元,平均每个查询的收入为 1.61 美分。在此基础上,谷歌必须支付大量的计算和网络开销,包括搜索、广告、网络爬虫、模型开发、员工等。谷歌成本结构中一个值得注意的项目是,他们支付了约 200 亿美元成为苹果产品的默认搜索引擎。
Google’s Services business unit has an operating margin of 34.15%. If we allocate the COGS/operating expense per query, you arrive at the cost of 1.06 cents per search query, generating 1.61 cents of revenue. This means that a search query with an LLM has to be significantly less than <0.5 cents per query, or the search business would become tremendously unprofitable for Google.
谷歌的服务业务部门的营业利润率为 34.15%。如果我们按每个查询分配销售成本/运营费用,得出的每个搜索查询的成本为 1.06 美分,产生 1.61 美分的收入。这意味着一个带有LLM的搜索查询的成本必须显著低于每个查询 0.5 美分,否则搜索业务将对谷歌变得极其不盈利。
We’re excited to announce the new Bing is running on a new, next-generation OpenAI large language model that is more powerful than ChatGPT and customized specifically for search. It takes key learnings and advancements from ChatGPT and GPT-3.5 – and it is even faster, more accurate and more capable.
我们很高兴地宣布,新的必应正在运行一个新的、下一代的 OpenAI 大型语言模型,比 ChatGPT 更强大,并专门为搜索定制。它吸取了 ChatGPT 和 GPT-3.5 的关键经验和进展——而且它的速度更快、准确性更高、能力更强。
ChatGPT Costs ChatGPT 成本
Estimating ChatGPT costs is a tricky proposition due to several unknown variables. We built a cost model indicating that ChatGPT costs $694,444 per day to operate in compute hardware costs. OpenAI requires ~3,617 HGX A100 servers (28,936 GPUs) to serve Chat GPT. We estimate the cost per query to be 0.36 cents.
估算 ChatGPT 的成本是一个棘手的命题,因为有几个未知变量。我们建立了一个成本模型,表明 ChatGPT 的计算硬件成本为每天 694,444 美元。OpenAI 需要大约 3,617 台 HGX A100 服务器(28,936 个 GPU)来服务 Chat GPT。我们估计每个查询的成本为 0.36 美分。
Our model is built from the ground up on a per-inference basis, but it lines up with Sam Altman’s tweet and an interview he did recently. We assume that OpenAI used a GPT-3 dense model architecture with a size of 175 billion parameters, hidden dimension of 16k, sequence length of 4k, average tokens per response of 2k, 15 responses per user, 13 million daily active users, FLOPS utilization rates 2x higher than FasterTransformer at <2000ms latency, int8 quantization, 50% hardware utilization rates due to purely idle time, and $1 cost per GPU hour.
我们的模型是从零开始构建的,基于每次推理,但它与萨姆·阿尔特曼的推文以及他最近的采访相一致。我们假设 OpenAI 使用了一个 1750 亿参数的 GPT-3 密集模型架构,隐藏维度为 16k,序列长度为 4k,每个响应的平均标记数为 2k,每个用户 15 个响应,1300 万日活跃用户,FLOPS 利用率比 FasterTransformer 高出 2 倍,延迟低于 2000 毫秒,int8 量化,由于纯闲置时间,硬件利用率为 50%,每个 GPU 小时成本为 1 美元。
Please challenge our assumptions; we would love to make this more accurate, although we believe we are in the correct ballpark.
请挑战我们的假设;我们希望能使这更准确,尽管我们相信我们在正确的范围内。
Search Costs With ChatGPT
使用 ChatGPT 的搜索成本
If the ChatGPT model were ham-fisted into Google’s existing search businesses, the impact would be devastating. There would be a $36 Billion reduction in operating income. This is $36 Billion of LLM inference costs. Note this is not what search would look like with LLMs, that analysis is here.
如果将 ChatGPT 模型生硬地融入谷歌现有的搜索业务,影响将是毁灭性的。运营收入将减少 360 亿美元。这是 360 亿美元的LLM推断成本。请注意,这不是LLMs下搜索的样子,相关分析在这里。
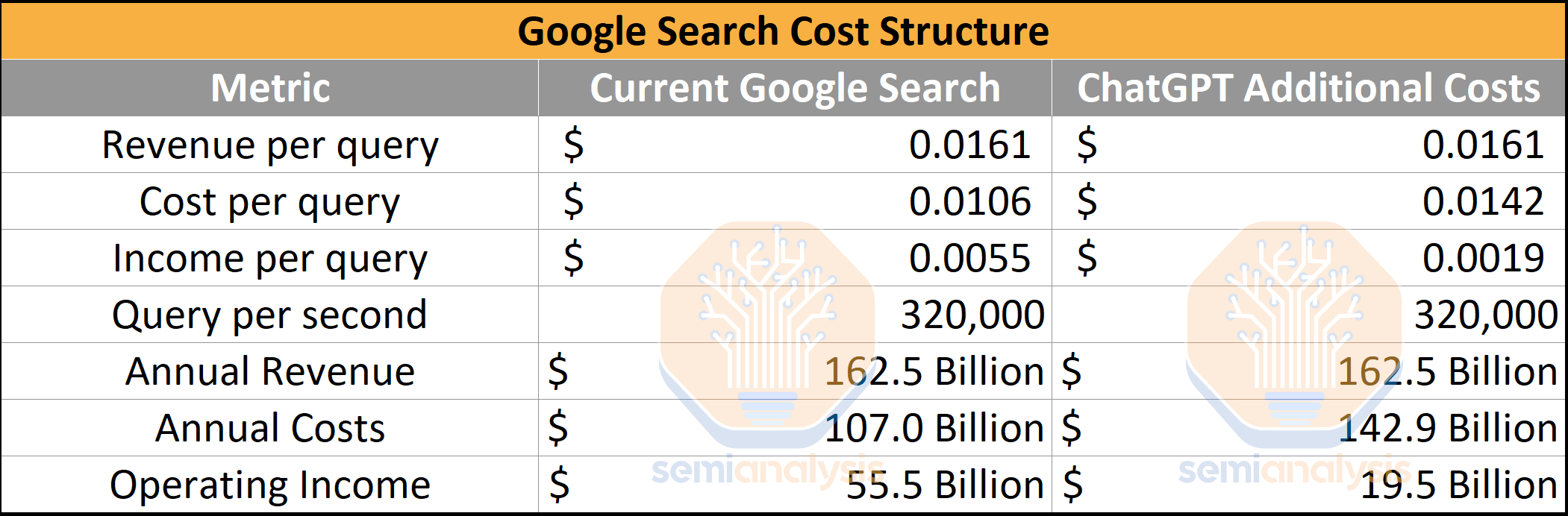
Deploying current ChatGPT into every search done by Google would require 512,820.51 A100 HGX servers with a total of 4,102,568 A100 GPUs. The total cost of these servers and networking exceeds $100 billion of Capex alone, of which Nvidia would receive a large portion. This is never going to happen, of course, but fun thought experiment if we assume no software or hardware improvements are made. We also have inference costs using Google’s TPUv4 and v5 modeled in the subscriber section, which are pretty different. We also have some H100 LLM inference performance improvement figures as well.
将当前的 ChatGPT 部署到每一次 Google 搜索中,需要 512,820.51 台 A100 HGX 服务器,总共需要 4,102,568 个 A100 GPU。这些服务器和网络的总成本超过 1000 亿美元的资本支出,其中 Nvidia 将获得很大一部分。当然,这永远不会发生,但如果假设没有软件或硬件改进,这个想法实验还是很有趣的。我们在订阅者部分还考虑了使用 Google 的 TPUv4 和 v5 的推理成本,这些成本差异很大。我们还有一些 H100 LLM推理性能提升的数据。
The amazing thing is that Microsoft knows that LLM insertion into search will crush the profitability of search and require massive Capex. While we estimated the operating margin shift, check out what Satya Nadella says about the gross margin.
令人惊讶的是,微软知道LLM插入搜索将压缩搜索的盈利能力,并需要大量资本支出。虽然我们估算了运营利润率的变化,但看看萨提亚·纳德拉对毛利率的看法。
From now on, the [gross margin] of search is going to drop forever.
从现在开始,搜索的[毛利率]将永远下降。
This doesn’t even account for the fact that search volumes likely decrease somewhat as search quality improves, the difficulties in inserting ads into an LLM’s response, or a myriad of other technical issues that we will discuss later in this report.
这甚至没有考虑到随着搜索质量的提高,搜索量可能会有所下降,插入广告到LLM的响应中的困难,或我们将在本报告后面讨论的其他无数技术问题。
Microsoft is happily blowing up the profitability of the search market.
微软正在愉快地提升搜索市场的盈利能力。
For every one point of share gain in the search advertising market, it’s a $2 billion revenue opportunity for our advertising business.
在搜索广告市场每增加一个百分点的市场份额,对我们的广告业务来说就是一个 20 亿美元的收入机会。
Bing has a meager market share. Any share gains Microsoft grabs will give them tremendous top-line and bottom-line financials.
必应的市场份额微薄。微软获得的任何市场份额增长都将为他们带来巨大的收入和利润。
I think there’s so much upside for both of us here. We’re going to discover what these new models can do, but if I were sitting on a lethargic search monopoly and had to think about a world where there was going to be a real challenge to the way that monetization of this works and new ad units, and maybe even a temporary downward pressure, I would not feel great about that.
我认为我们双方在这里都有很大的上行空间。我们将会发现这些新模型能做什么,但如果我坐在一个迟钝的搜索垄断上,必须考虑一个将会对这种货币化方式和新的广告单元构成真正挑战的世界,甚至可能会有暂时的下行压力,我对此不会感到乐观。There’s so much value here, it’s inconceivable to me that we can’t figure out how to ring the cash register on it.
这里有如此多的价值,我无法想象我们无法找到方法来实现盈利。Sam Altman, CEO OpenAI on Stratechery
萨姆·阿尔特曼,OpenAI 首席执行官,关于 Stratechery
Meanwhile, Google is on the defensive. If their search franchise falters, they have a tremendous problem with their bottom line. Share losses will look even worse than the analysis above as Google is quite bloated in operating costs.
与此同时,谷歌处于防守状态。如果他们的搜索业务出现问题,他们的底线将面临巨大的挑战。由于谷歌在运营成本方面相当臃肿,股价损失将比上述分析看起来更糟。
Google’s Response 谷歌的回应
Google isn’t taking this lying down. Within just a couple of months of ChatGPT’s release, Google is already putting their version of search with an LLM into the public sphere. There are advantages and disadvantages from what we have seen on the new Bing vs. the new Google.
谷歌并没有对此坐视不理。在 ChatGPT 发布仅几个月内,谷歌已经将他们的搜索版本与LLM投入公众领域。从我们看到的新必应与新谷歌来看,存在优缺点。
Bing GPT seems tremendously more potent in terms of LLM capabilities. Google has already had issues with accuracy, even in their on-stage demonstrations of this new technology. If you measure both Bing GPT and Google Bard response time, Bard crushes Bing in response time. These model response time and quality differences are directly related to model size.
必应 GPT 在LLM能力方面似乎强大得多。谷歌在其新技术的现场演示中已经出现了准确性问题。如果你测量必应 GPT 和谷歌 Bard 的响应时间,Bard 在响应时间上远远超过必应。这些模型的响应时间和质量差异与模型大小直接相关。
Bard combines the breadth of the world’s knowledge with the power, intelligence, and creativity of a large language model. It draws on the information from the web to provide fresh and high-quality responses. We’re releasing it initially with our lightweight model version of LaMDA. This much smaller model requires significantly less computing power, enabling us to scale to more users, allowing for more feedback.
巴德结合了世界知识的广度与大型语言模型的力量、智能和创造力。它利用网络上的信息提供新鲜且高质量的回应。我们最初将其与我们轻量级的 LaMDA 模型版本一起发布。这个更小的模型需要显著更少的计算能力,使我们能够扩展到更多用户,从而获得更多反馈。
Google is playing defense on margins with this smaller model. They could have deployed their full-size LaMDA model or the far more capable and larger PaLM model, but instead, they went for something much skinnier.
谷歌在这个较小的模型上采取了防御措施以保护利润率。他们本可以部署全尺寸的 LaMDA 模型或更强大、更大的 PaLM 模型,但他们选择了一个更精简的方案。
This is out of necessity.
这是出于必要。
Google cannot deploy these massive models into search. It would erode their gross margins too much. We will talk more about this lighter-weight version of LaMDA later in this report, but it’s important to recognize that the latency advantage of Bard is a factor in its competitiveness.
谷歌无法将这些大型模型部署到搜索中。这会过度侵蚀他们的毛利率。我们将在本报告后面进一步讨论这种轻量级的 LaMDA 版本,但重要的是要认识到,Bard 的延迟优势是其竞争力的一个因素。
Since Google’s search revenue is derived from ads, different users generate different revenue levels per search. The average suburban American woman is much more revenue per targeted ad than a male farmer in India. This also means they generate vastly different operating margins too.
由于谷歌的搜索收入来自广告,不同用户每次搜索产生的收入水平不同。平均而言,郊区的美国女性每个目标广告产生的收入远高于印度的男性农民。这也意味着他们的运营利润率差异巨大。

想象一个反乌托邦,富裕的郊区妈妈可以使用最好的搜索引擎,而其他人只能使用低成本的搜索引擎…… 考虑到每次推理的成本为LLMs,谷歌和微软必应有充分的理由仅将其部署给最高 CPM 的用户... $GOOGL $MSFT
The Future of Large Language Models In Search
大型语言模型在搜索中的未来
Ham fisting an LLM directly into search is not the only way to improve search. Google has been using language models within search to generate embeddings for years. This should improve results for the most common searches without blowing up inference cost budgets because those can be generated once and served to many. We peel that onion here and some of the numerous cost optimizations that can be done.
将 LLM 直接放入搜索并不是改善搜索的唯一方法。谷歌多年来一直在搜索中使用语言模型来生成嵌入。这应该能改善最常见搜索的结果,而不会大幅增加推理成本预算,因为这些可以一次生成并服务于许多请求。我们在这里剖析这个问题,以及可以进行的一些众多成本优化。
One of the biggest challenges with inserting LLM into search is sequence length growth and low latency criteria. We will discuss those below and how those will shape the future of search.
在搜索中插入LLM面临的最大挑战之一是序列长度增长和低延迟标准。我们将在下面讨论这些问题以及它们将如何塑造搜索的未来。
We will also discuss Nvidia A100, H100, and Google’s TPU in the context of LLM inference and costs per query. We will also be sharing H100 inference performance improvement and the impact that it will have on the hardware market. The competitiveness of GPU vs. TPU is inherent in this battle.
我们还将讨论 Nvidia A100、H100 和 Google 的 TPU 在LLM推理和每个查询成本的背景下。我们还将分享 H100 推理性能的提升及其对硬件市场的影响。GPU 与 TPU 的竞争性在这场战斗中是固有的。
Furthermore, the cost per inference can be significantly reduced without new hardware. We discussed OpenAI’s next LLM architecture improvement on the training side here, but there are also improvements in inference costs. Furthermore, Google is also utilizing some unique, exciting techniques that we will also discuss below.
此外,每次推理的成本可以在不增加新硬件的情况下显著降低。我们在这里讨论了 OpenAI 的下一个LLM架构在训练方面的改进,但在推理成本方面也有改进。此外,谷歌还利用了一些独特而令人兴奋的技术,我们将在下面讨论。
Sequence Length 序列长度
Sequence length is essentially how much context an LLM can have. In a chatbot application, this effectively means how far back it can look. This is easily visible in ChatGPT because there is a sequence length of 4k. ChatGPT can only see 4k tokens backward. This is the practical limit on input and response length. The average token is 3 to 4 letters, so responses are limited to 5k or so words. The last words, when generated, may not even be able to see the prompt.
序列长度本质上是一个LLM可以拥有多少上下文。在聊天机器人应用中,这实际上意味着它可以回溯多远。这在 ChatGPT 中很容易看出,因为它的序列长度为 4k。ChatGPT 只能向后查看 4k 个标记。这是输入和响应长度的实际限制。平均每个标记为 3 到 4 个字母,因此响应限制在大约 5k 个单词。生成的最后几个单词甚至可能无法看到提示。
In the context of search, this is even more important. While the beauty of LLM insertion into search is that they can read web pages before answering, this is extremely limited with modern sequence lengths. The LLM can only scan a certain number of tokens from the traditional search and your prompt before delivering the answer. The LLM must rely on the standard search’s ability to give the best possible context within that sequence length.
在搜索的背景下,这一点更加重要。虽然LLM插入搜索的美在于它们可以在回答之前读取网页,但现代序列长度对此极为有限。LLM只能从传统搜索和您的提示中扫描一定数量的标记,然后才能给出答案。LLM必须依赖标准搜索在该序列长度内提供最佳上下文的能力。
The Google Bard LLM has a very limited sequence length of around 2k from the limited screenshots they have shown off, which is half of what ChatGPT has. This goes back to Google going lightweight to reduce compute costs. Sequence length contributes significantly to the total FLOPS required during the attention mechanism. In most LLMs, the attention mechanism is not a significant portion of FLOPS, but as you scale sequence length, it impacts memory bandwidth and attention FLOPS hugely. This crushes the memory which is already the wall.
谷歌的 Bard LLM 具有非常有限的序列长度,大约为 2k,从他们展示的有限截图来看,这仅为 ChatGPT 的一半。这与谷歌为了降低计算成本而选择轻量化有关。序列长度对注意机制所需的总 FLOPS 有显著影响。在大多数情况下 LLMs,注意机制并不是 FLOPS 的一个重要部分,但随着序列长度的增加,它对内存带宽和注意 FLOPS 的影响巨大。这压垮了已经是瓶颈的内存。
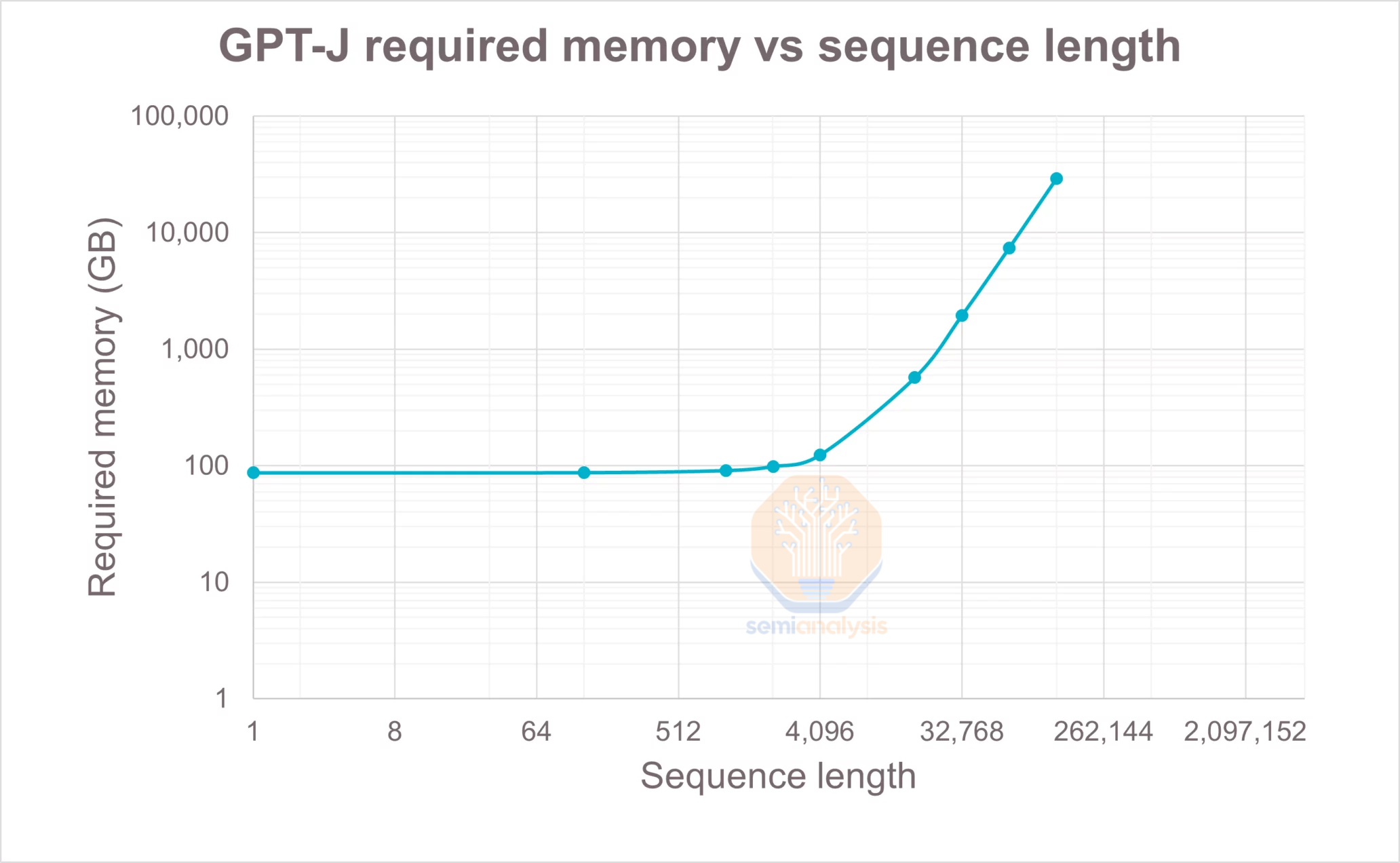
There don’t seem to be many tricks to solve sequence length scaling beyond operand fusion strategies such as FlashAttention, which reduces memory capacity requirements, but not FLOPS requirements.
似乎没有太多技巧可以解决序列长度扩展,除了操作数融合策略,如 FlashAttention,它减少了内存容量需求,但没有减少 FLOPS 需求。
Latency 延迟
One of the biggest troubles with LLMs for search and ChatBot applications is their required latency. Users of ChatGPT know it is simply too slow for many searches that you do throughout the day. While ChatGPT is fantastic for the deep context, there are many cases where the high latency is not conducive to the search experience.
LLMs在搜索和聊天机器人应用中的最大问题之一是其所需的延迟。ChatGPT 的用户知道,对于你在一天中进行的许多搜索,它的速度实在太慢。虽然 ChatGPT 在深度上下文方面表现出色,但在许多情况下,高延迟并不利于搜索体验。
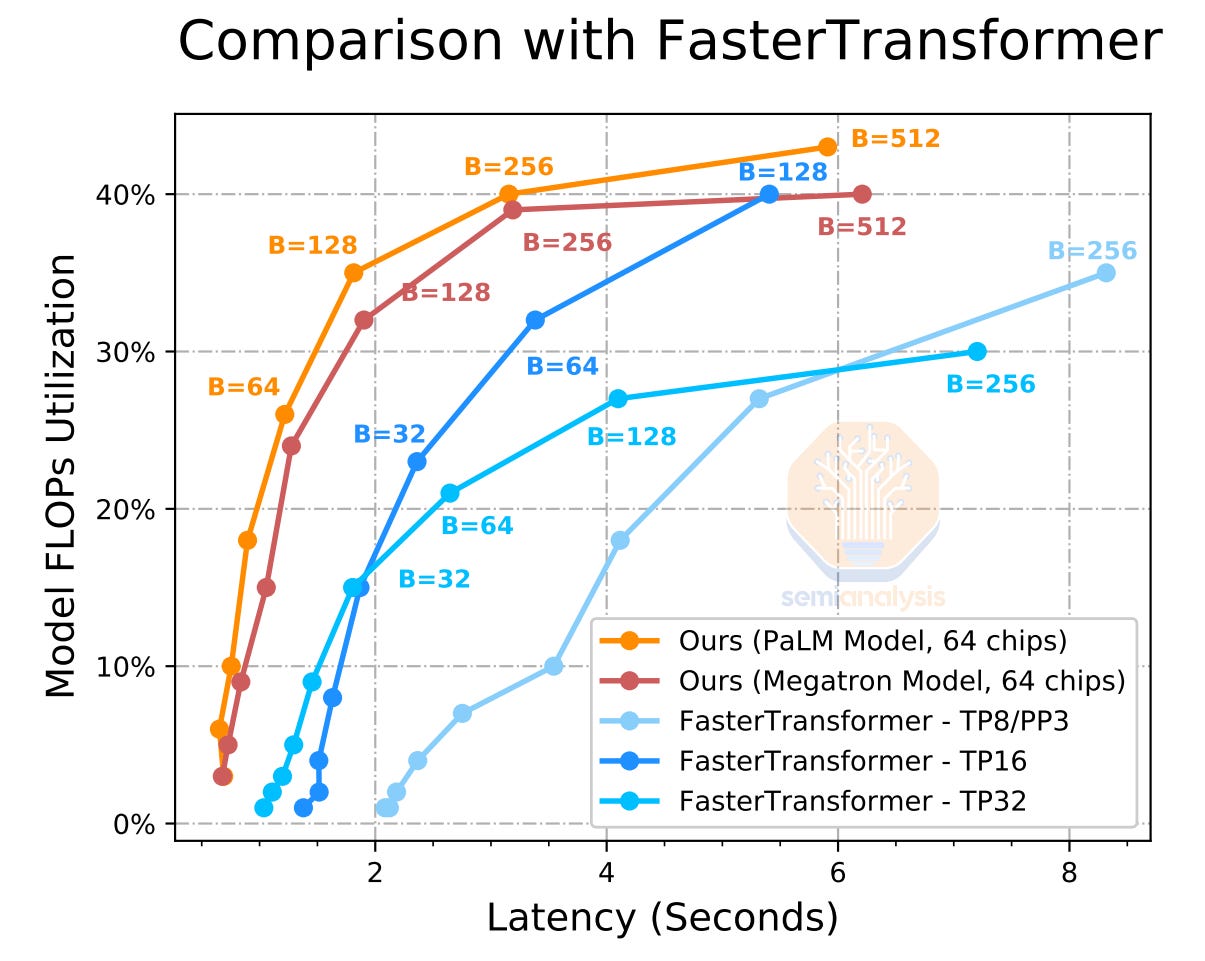
Google revealed some eye-popping results on latency for huge models. These results use PaLM, a much larger model than Bard, and GPT-3. Google showed that if you increase batch size, that balloons the latency of your response. If you keep batch sizes low, then utilization rates are horrible. Furthermore, Google’s results are only for generating 20 tokens output, or ~80 characters. It takes 64 TPUv4s more than 2 seconds of response time to break >30% model flops utilization. This is horrible utilization rates for inference on huge models.
谷歌揭示了一些关于大型模型延迟的惊人结果。这些结果使用了比 Bard 和 GPT-3 更大的模型 PaLM。谷歌显示,如果增加批量大小,响应的延迟会大幅上升。如果保持批量大小较低,则利用率非常糟糕。此外,谷歌的结果仅针对生成 20 个标记的输出,或约 80 个字符。使用 64 个 TPUv4,响应时间超过 2 秒才能打破>30%的模型浮点运算利用率。这对于大型模型的推理来说,利用率非常糟糕。
It remains to be seen how sensitive users are to latency in many new applications, but search is one where they are susceptible. We will move to a world where the largest models have very long inference times/costs and cannot be used effectively for search and chatbot applications.
尚待观察用户在许多新应用中对延迟的敏感程度,但搜索是一个他们容易受到影响的领域。我们将进入一个世界,在这个世界中,最大的模型具有非常长的推理时间/成本,无法有效用于搜索和聊天机器人应用。
Hardware Improvements 硬件改进
While performance improvements from hardware are slowing down generally, the improvements in inference are still chugging along at an incredible speed. Nvidia’s H100 brings about huge improvements that will make adoption for LLM search applications massive, especially at low latency.
尽管硬件的性能提升总体上正在放缓,但推理的改进仍在以惊人的速度进行。Nvidia 的 H100 带来了巨大的改进,这将使LLM搜索应用的采用量巨大,特别是在低延迟情况下。

英伟达预测性能,MT-NLG 32(批量大小:A100 为 4,H100 为 60,时长 1 秒;A100 为 8,H100 为 64,时长 1.5 秒和 2 秒)
These numbers are the first party from Nvidia. We hear performance improvement is more like 5x to 8x, depending on the latency threshold for GPT-3 175B sized model from a friend at Microsoft. The improvements are bigger in LLM inference than they are even in training. Also, note that H100 is ~80% more expensive than A100. This massive improvement in inference costs enables new experiences in LLM inference and will drive a large adoption wave. We expect the H100 upgrade cycle to be massive.
这些数字是来自 Nvidia 的第一方数据。我们听说性能提升更像是 5 倍到 8 倍,这取决于来自微软的一位朋友对 GPT-3 175B 模型的延迟阈值的看法。在LLM推理中的改进比训练中的改进更大。此外,请注意 H100 的价格比 A100 贵约 80%。这种推理成本的巨大改善使得在LLM推理中能够实现新的体验,并将推动大规模的采用浪潮。我们预计 H100 的升级周期将是巨大的。
Google’s TPU is generally better for large model inference workloads, or so all the Googlers claim. We get a massive cost improvement using similar albeit tweaked assumptions with higher utilization than the original example.
谷歌的 TPU 通常更适合大型模型推理工作负载,或者说所有谷歌员工都这样声称。我们在使用类似但经过调整的假设下,利用率高于原始示例,从而获得了巨大的成本改善。
TPUv4 drops the cost per query to 0.19 cents, assuming $0.80 per TPUv4 per hour. This is a tremendous improvement versus our projected cost per query of 0.36 cents for OpenAI’s current ChatGPT.
TPUv4 将每次查询的成本降低到 0.19 美分,假设每小时 TPUv4 的费用为 0.80 美元。这与我们对 OpenAI 当前 ChatGPT 的每次查询预计成本 0.36 美分相比,取得了巨大的改善。
We have also heard that TPUv5 brings a ~3x improvement in perf/TCO. While this is a very shaky rumor, this would imply ~0.06 cents per inference. The TPUv5 figures are rumors; please take them as such, especially with all the other assumptions we outlined above.
我们还听说 TPUv5 在性能/总拥有成本方面带来了约 3 倍的提升。虽然这只是一个非常不可靠的传闻,但这将意味着每次推理约 0.06 美分。TPUv5 的数字都是传闻;请将其视为如此,特别是考虑到我们上面列出的所有其他假设。
Software Improvements 软件改进
One of the things that we’ve gotten a lot of confidence in over the past handful of years is our ability to performance-optimize all of this stuff, both on the training and the inference side of things. Already the cost envelope for Bing looks very favorable to us. We think we actually have a lot of flexibility in bringing it to market as an ad-supported product that we wouldn’t have had if we hadn’t spent so much money on performance optimization and the cost is just going to go down over time.
在过去的几年里,我们对自己在训练和推理方面优化所有这些内容的能力充满信心。Bing 的成本范围对我们来说已经显得非常有利。我们认为,作为一种广告支持的产品,我们在将其推向市场时实际上有很大的灵活性,如果我们没有在性能优化上花费如此多的资金,就不会有这样的灵活性,而且成本会随着时间的推移而下降。Kevin Scott, Microsoft CTO on Stratechery
凯文·斯科特,微软首席技术官在 Stratechery 上
We didn’t expect ChatGPT to be such a success, so we had not gotten as disciplined about optimization at that point as we needed to.
我们没有预料到 ChatGPT 会如此成功,因此在那时我们并没有像需要的那样对优化进行严格管理。Sam Altman, OpenAI CTO on Stratechery
萨姆·阿尔特曼,OpenAI 首席技术官在 Stratechery 上
While the hardware side can deliver an order magnitude of scaling, the software can provide 2 orders of magnitude within the same compute cost budget.
尽管硬件方面可以实现一个数量级的扩展,但软件可以在相同的计算成本预算内提供两个数量级的扩展。
Sparsity and Pruning were discussed here before in detail, but those could improve performance by as much as 4x. Stochastic rounding support in hardware and quantization down to FP8 likely enables 2x performance alone. Pruning could also easily do another 2x, as shown here.
稀疏性和剪枝在这里之前已经详细讨论过,但这些可以提高性能多达 4 倍。硬件中的随机舍入支持和量化到 FP8 可能单独实现 2 倍的性能。剪枝也可以轻松再提高 2 倍,如此处所示。
The most significant improvements will come from Mixture of Experts. OpenAI’s next generation of LLMs will utilize mixture of experts heavily, as we discussed here. The concept is explained there in great detail, but the performance improvements could be as much as 7x, and when combined with certain latency thresholds, it could be an order of magnitude alone. Google likely implements this rapidly as well, assuming they haven’t already.
最显著的改进将来自专家混合。OpenAI 的下一代LLMs将大量利用专家混合,正如我们在这里讨论的那样。该概念在那里的详细解释中,但性能提升可能高达 7 倍,并且当与某些延迟阈值结合时,可能单独达到一个数量级。谷歌也可能迅速实施这一点,假设他们还没有这样做。
Model Distillation is another technique that is being researched heavily and likely makes it to production in Google’s Bard or future models. Model distillation is a technique used to transfer knowledge from a large, complex model (known as the "teacher model") to a smaller, simpler model (known as the "student model"). The goal of distillation is to produce a student model with similar or better performance than the teacher model but is smaller and more computationally efficient.
模型蒸馏是另一种正在被广泛研究的技术,可能会在谷歌的 Bard 或未来的模型中投入生产。模型蒸馏是一种将知识从一个大型复杂模型(称为“教师模型”)转移到一个较小、较简单模型(称为“学生模型”)的技术。蒸馏的目标是生成一个性能与教师模型相似或更好的学生模型,但体积更小且计算效率更高。
The basic idea behind model distillation is to use the teacher model to generate predictions for a set of training examples. These predictions are then used as "soft targets" to train the student model instead of the ground-truth labels. The intuition behind this approach is that the teacher model has seen many more examples and has learned more complex patterns and relationships between inputs and outputs and that these patterns can be distilled into the student model through the soft targets.
模型蒸馏的基本思想是使用教师模型为一组训练样本生成预测。这些预测随后作为“软目标”来训练学生模型,而不是使用真实标签。这种方法的直觉在于,教师模型已经看到了更多的样本,并学习了输入和输出之间更复杂的模式和关系,这些模式可以通过软目标蒸馏到学生模型中。
The last major technique is early exit. Google will likely implement this in the next generation after Bard. The primary idea with these techniques is to reduce the compute required when you already know the answer partway through the model. While this has existed in some capacity in the past, Google presented “Confident Adaptive Language Modeling” (CaLM) at NeurIPS last month. It seems like it will revolutionize the space once it is built into production models.
最后一个主要技术是提前退出。谷歌可能会在 Bard 之后的下一代中实施这一点。这些技术的主要思想是在你已经知道答案的情况下,减少模型所需的计算量。虽然在过去某种程度上已经存在这种技术,但谷歌在上个月的 NeurIPS 上展示了“自信自适应语言建模”(CaLM)。一旦它被构建到生产模型中,似乎将会彻底改变这个领域。
Instead of waiting for all decoder layers to complete, CaLM attempts to predict the next word before the token has made it through the entire model instead of waiting for all decoder layers to complete. At various intermediate points in the model, the model can decide whether to commit to a specific prediction or postpone it to a later layer. The model’s confidence is measured at each intermediate prediction point. The rest of the computation is skipped only when the model is confident that the prediction won’t change. The researcher can adjust this confidence value.
CaLM 尝试在令牌通过整个模型之前预测下一个词,而不是等待所有解码器层完成。在模型的各个中间点,模型可以决定是承诺一个特定的预测还是将其推迟到后面的层。模型的信心在每个中间预测点进行测量。只有当模型确信预测不会改变时,剩余的计算才会被跳过。研究人员可以调整这个信心值。
This can massively improve performance by as much as 3x, and latency improvements will enable much larger batch sizes, so higher hardware utilization can also be achieved.
这可以将性能大幅提升多达 3 倍,延迟的改善将使得更大的批量处理成为可能,从而也能实现更高的硬件利用率。

The future is bright here. With Google and Microsoft at all-out war over search, the consumer and semiconductor companies win. Microsoft likely pushes right up against the edge of profitability, while Google will rely on the TPU and superior software to use less costly models with similar accuracy.
未来在这里是光明的。随着谷歌和微软在搜索领域的全面竞争,消费者和半导体公司受益。微软可能会逼近盈利的边缘,而谷歌将依靠 TPU 和更优越的软件使用成本更低但准确性相似的模型。
It seems like the promising startup of Neeva was effectively killed this week. Their model doesn’t seem comparable to either Google or Microsoft, and the monetization method is also lacking. While Microsoft has discussed a potential paid search option, Google seems only to be bringing these technologies to the ad-supported model. Google may need to adapt its business model to offer both, or they risk being outcompeted. Neeva’s offering is untenable in the new market that burst into view this week.
看起来,Neeva 这个有前途的初创公司在本周实际上已经被扼杀了。他们的模式似乎无法与谷歌或微软相提并论,变现方式也存在不足。虽然微软讨论了潜在的付费搜索选项,但谷歌似乎只是将这些技术引入到广告支持的模式中。谷歌可能需要调整其商业模式,以提供两者,否则他们面临被竞争对手超越的风险。Neeva 的产品在本周突现的新市场中是不可行的。














Probably worth updating your estimate:
可能值得更新您的估计:
https://openai.com/blog/introducing-chatgpt-and-whisper-apis
ChatGPT and Whisper models are now available on our API, giving developers access to cutting-edge language (not just chat!) and speech-to-text capabilities. Through a series of system-wide optimizations, we’ve achieved 90% cost reduction for ChatGPT since December; we’re now passing through those savings to API users. Developers can now use our open-source Whisper large-v2 model in the API with much faster and cost-effective results. ChatGPT API users can expect continuous model improvements and the option to choose dedicated capacity for deeper control over the models. We’ve also listened closely to feedback from our developers and refined our API terms of service to better meet their needs.
ChatGPT 和 Whisper 模型现在可以在我们的 API 上使用,为开发者提供尖端的语言(不仅仅是聊天!)和语音转文本功能。通过一系列系统范围的优化,自去年 12 月以来,我们已实现 ChatGPT 成本降低 90%;我们现在将这些节省传递给 API 用户。开发者现在可以在 API 中使用我们的开源 Whisper large-v2 模型,获得更快且更具成本效益的结果。ChatGPT API 用户可以期待持续的模型改进,并可以选择专用容量以更深入地控制模型。我们还密切关注开发者的反馈,优化了我们的 API 服务条款,以更好地满足他们的需求。
3 条回复来自 Dylan Patel 及其他人
Could you list data sources and basically the method used to estimate Google's cost per query? And where do you think we can find out how those costs have declined throughout the years (which is what I'm assuming has happened)? Any help is appreciated.
您能列出数据来源以及用于估算谷歌每次查询成本的方法吗?您认为我们可以在哪里找到这些成本在过去几年中如何下降的信息(我假设确实发生了这种情况)?任何帮助都将不胜感激。