Convolutional Neural Network
卷積神經網絡
Understanding the intuition behind the layers
理解層的直覺
In 1950 Alan Turing presented a paper called The Turing Test, where he laid the ground rules for a machine to be called intelligent. Despite having breakthroughs in the field of Artificial Intelligence, even today machines are incapable of being regarded as intelligent. Neural Network is a domain of Artificial Intelligence which aims at mimicking the brain structure of the human body. One of the basic types of Neural Network called Artificial Neural Network(ANN) is efficient in finding the hidden patterns in the provided data and give out the result.
在 1950 年,艾倫·圖靈發表了一篇名為圖靈測試的論文,他在其中為機器被稱為智能制定了基本規則。儘管在人工智能領域取得了突破,但即使在今天,機器仍然無法被視為智能。神經網絡是人工智能的一個領域,旨在模仿人體的大腦結構。一種基本類型的神經網絡稱為人工神經網絡(ANN),它能有效地發現提供數據中的隱藏模式並給出結果。
NOTE: This article assumes the reader to have a basic understanding of Neural Networks
注意:本文假設讀者對神經網路有基本的了解
A question still persists that even though machines can process and understand the data given to them but do they have the capability to see things like humans?
一個問題仍然存在,即使機器能夠處理和理解給予它們的數據,但它們是否具備像人類一樣看待事物的能力?
YES! Providing vision to the machine seems an absurd thing to say but one such Neural Network called Convolutional Neural Network imparts the partial sense of vision to the Machines.
是的!讓機器擁有視覺似乎是一件荒謬的事情,但有一種神經網絡稱為卷積神經網絡,它賦予機器部分的視覺感知能力。
Since an image is just a collection of numerical pixel values, can’t ANN’s process it? The answer to this is NO! Though ANN classifies well on the numerical data, it lacks the consideration of spatial relationships while processing the image. Let me simplify it. While processing the list of images, if ANN finds that a cat occurs in the top right corner of one image then it will assume that it will always appear there. Hence no matter where your cat is in the image, if it cannot find it in the top right corner then it will give out a negative result.
由於圖像只是一組數值像素值,難道人工神經網路(ANN)不能處理它嗎?答案是不行!雖然人工神經網路在數據分類上表現良好,但在處理圖像時缺乏對空間關係的考量。讓我簡化一下。在處理圖像列表時,如果人工神經網路發現一隻貓出現在某張圖像的右上角,它會假設貓總是出現在那裡。因此,無論你的貓在圖像中的哪個位置,如果它無法在右上角找到貓,它就會給出一個負面的結果。
On the other side, Convolutional Neural Network, also known as ConvNet performs exceptionally well in finding an object anywhere in the image. Also, don’t worry if your cat is grumpy, it will still identify it.
在另一方面,卷積神經網絡,也被稱為ConvNet 在圖像中的任何地方找到物體的表現都非常出色。而且,不用擔心你的貓是否脾氣暴躁,它仍然能夠識別出來。

照片來源:Adesh Deshpande 經由 GitHub (MIT)
The above image represents the basic architecture of the ConvNet which contains terms such as Pooling, FC Layer, Convolution that may seem overwhelming at first glance. This article aims at demystifying such terms and getting intuition behind using it.
上圖展示了卷積神經網路的基本架構,其中包含了像池化、全連接層、卷積等術語,這些術語乍看之下可能會讓人感到困惑。本文旨在解釋這些術語並幫助理解其背後的直覺。
Getting started, let’s understand what are we feeding to the network!
開始之前,讓我們了解一下我們正在餵給網路的是什麼!

照片由Andrei Mike攝於Unsplash
The image that we see looks mesmerizing to us. But that’s not how the machine looks at it. It sees it as a collection of numerical pixel values representing the intensity values of color channels. The dimension of this image is 5999 x 4000 x 3; where 3 depicts the number of color channels i.e. RGB. Other color channels can be HSV, GrayScale, and many more.
我們看到的圖像讓我們感到著迷。但機器並不是這樣看待它的。它將圖像視為一組數字像素值,這些值代表顏色通道的強度值。該圖像的尺寸為 5999 x 4000 x 3,其中 3 表示顏色通道的數量,即 RGB。其他顏色通道可以是 HSV、灰階等。
How do machines extract features from pixel values?
機器如何從像素值中提取特徵?
In mathematics, a concept called Convolution takes two functions into account and produces a third function expressing how the shape of one function is affected by the other. Imagine applying a filter to your photo. What happens here is, it takes your photo and applies the function of the filter which may be to highlight the shadows. Filter activates certain features of your image and produces an output image.
在數學中,有一個稱為卷積的概念,它考慮兩個函數並產生第三個函數,該函數表達一個函數的形狀如何受到另一個函數的影響。想像一下對你的照片應用濾鏡。這裡發生的情況是,它採用你的照片並應用濾鏡的函數,該函數可能是用來突出陰影。濾鏡激活了圖像的某些特徵,並產生輸出圖像。
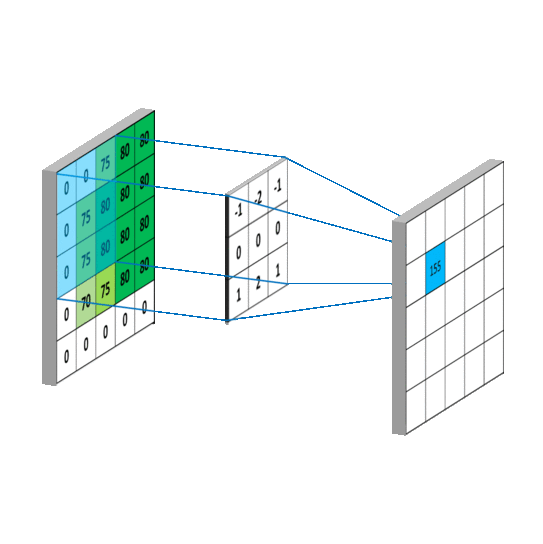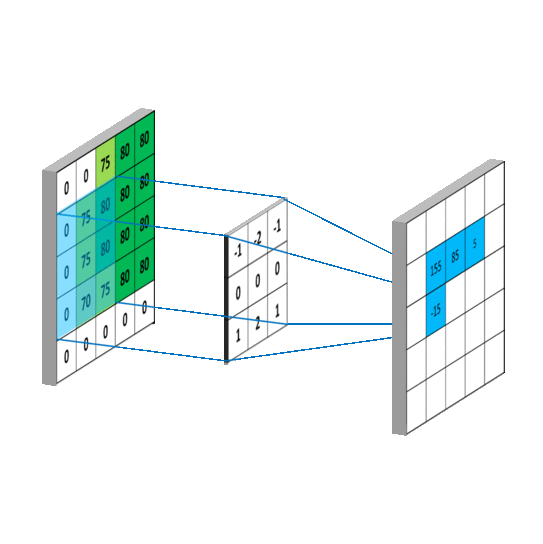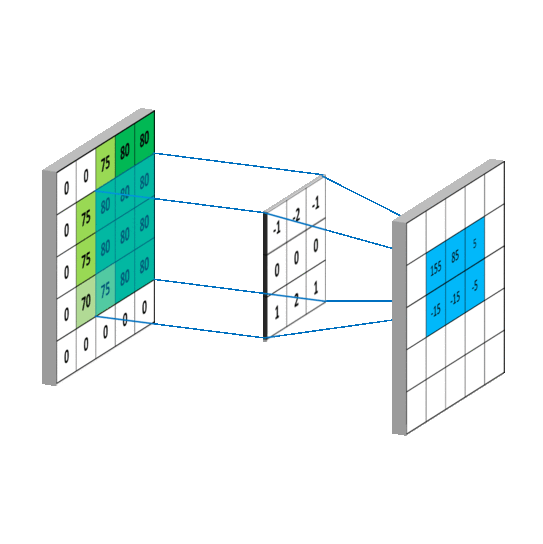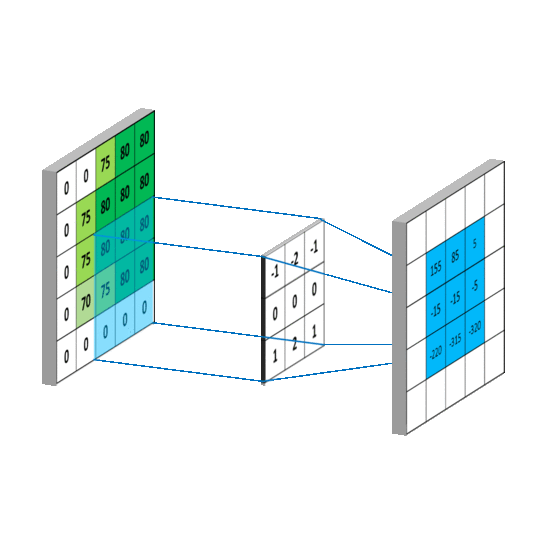
So the question arises, what are these filters? Filters are nothing but 3D matrices having specific values that get excited when they see a desired pattern in the neighborhood. They are considerably smaller than the input image which slides over the width and height of the image.
那麼問題來了,這些過濾器是什麼?過濾器只不過是具有特定值的 3D 矩陣,當它們在鄰域中看到所需的模式時會被激發。它們比輸入圖像小得多,會在圖像的寬度和高度上滑動。
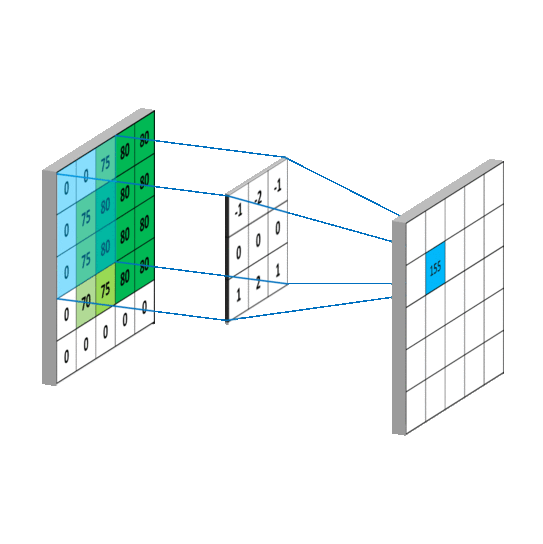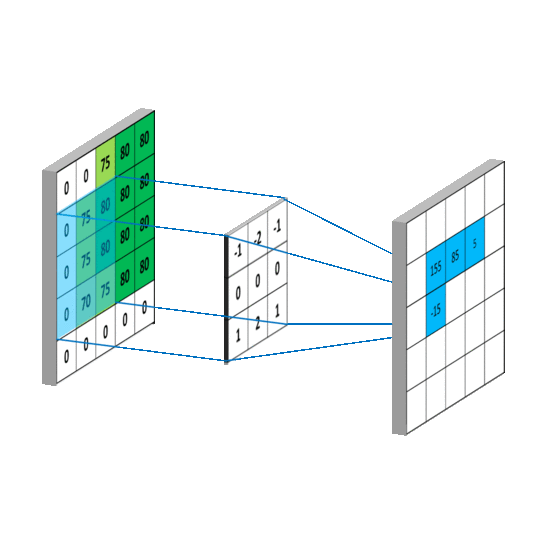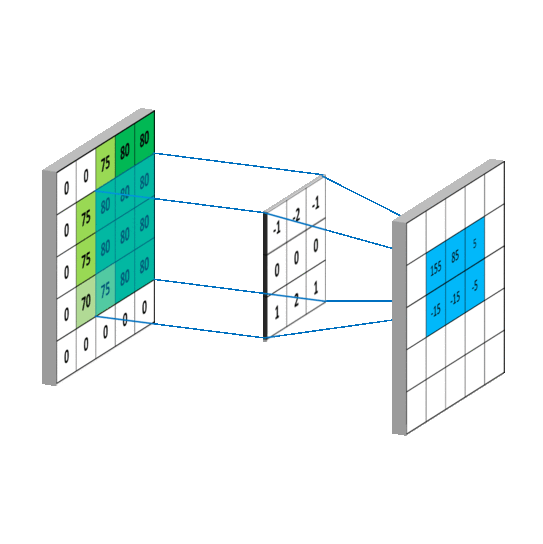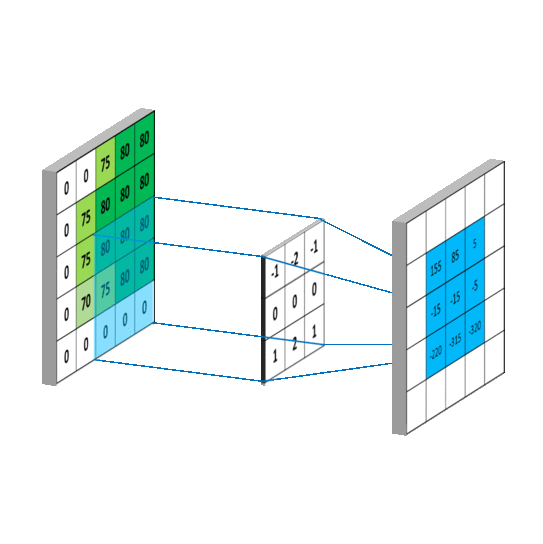
5 x 5 圖像與 3 x 3 濾波器的卷積運算。照片來源:Rob Robinson 於 MLNoteBook
When the filter slides over the image it focuses on a certain neighborhood of the image. It performs an arithmetic operation of the filter and the portion of the image and stores the result in a single cell. In technical terminology, cells are regarded as Neurons. Multiple such neurons, when combined, form a 2D matrix called Activation Map/ Feature Map, or rather I would say the collection of the likings of the filter from the image. The neighborhood which is pointed by a single neuron is called a Local Receptive Field.
當濾波器滑過圖像時,它會聚焦於圖像的某個區域。它執行濾波器與圖像部分的算術運算,並將結果存儲在單個單元中。在技術術語中,這些單元被視為神經元。當多個這樣的神經元結合在一起時,會形成一個稱為激活圖/特徵圖的二維矩陣,或者更確切地說,我會稱之為濾波器從圖像中挑選出的集合。由單個神經元指向的區域稱為局部感受野。
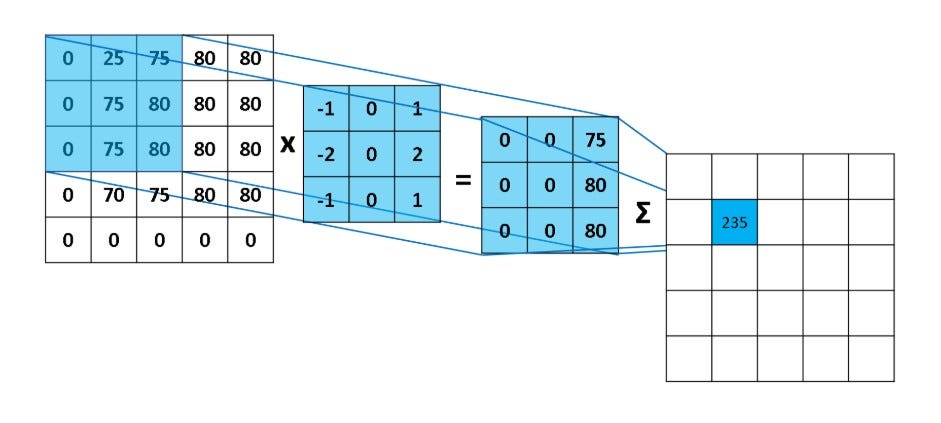
算術運算和局部感受野。照片由 Rob Robinson 拍攝於 MLNoteBook
Now, this feature map is a result of feature extraction done by one filter. In the case of the Convolution layer, multiple features are used which in turn produces multiple feature maps. The feature maps are stacked together to be passed on as input to the next layer.
現在,這個特徵圖是由一個濾波器進行特徵提取的結果。在卷積層的情況下,使用了多個特徵,從而產生多個特徵圖。這些特徵圖被堆疊在一起,作為輸入傳遞到下一層。
Higher the number of filters, higher is the number of feature maps and deeper is the extraction of the features.
過濾器的數量越多,特徵圖的數量越多,特徵提取的深度越深。
What happens to the size of the output image?
輸出圖像的大小會發生什麼變化?
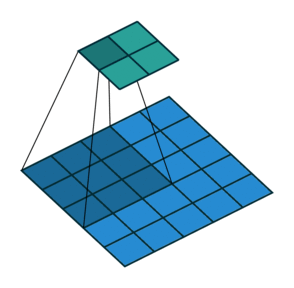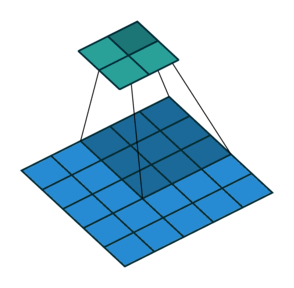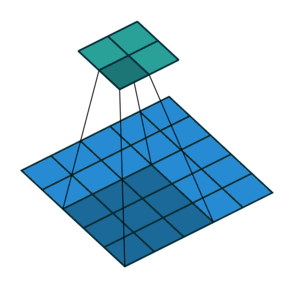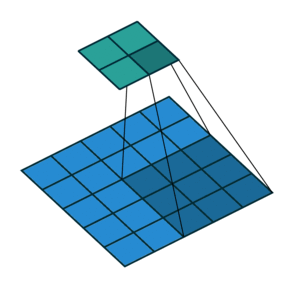
卷積運算。照片來源:vdumoulin 於 GitHub (MIT)
The size of the output image is bound to reduce after the convolution operation. The parameters which control the size of the output volume are stride, filter size, and padding.
輸出圖像的大小在卷積操作後必然會減少。控制輸出體積大小的參數是步幅、濾波器大小和填充。
- Stride: Stride is the number of pixels that we move while sliding the filter. When the stride is 2, we move the filter by 2 pixels. Higher the stride, lower the dimension of the output volume. Usually, we set the stride to either 1 or 2.
步幅:步幅是我們在滑動濾波器時移動的像素數。當步幅為 2 時,我們將濾波器移動 2 個像素。步幅越大,輸出體積的維度越小。通常,我們將步幅設置為 1 或 2。 - Filter Size: While we increase the filter size, we indirectly increase the amount of information to be stored in a single neuron. In that case, the number of resulting moves made by filter over the image would reduce. This would eventually result in the reduction of the spatial size of output volume.
濾波器大小:當我們增加濾波器大小時,我們間接增加了需要存儲在單個神經元中的信息量。在這種情況下,濾波器在圖像上移動的次數會減少。這最終會導致輸出體積的空間大小減少。

3. Padding: As the name suggests it adds an insignificant cover around the original image to keep the size of the output image intact. Calculation of the number of layers to be added is done using the formula P=(((O-1)*S)+F-W)/2 where O is the size of the output image, W is the size of an input image, F is the filter size, P is the number of layers pixels to be added as padding, and S is the stride. For example, if the size of the input image is 5x 5, the filter size is 3 x 3, the stride is 1 and we want the same size of the output image as the input image, the valid padding would be 1.
3. 填充:顧名思義,它在原始圖像周圍添加一個無關緊要的覆蓋層,以保持輸出圖像的大小不變。添加層數的計算使用公式 P=(((O-1)*S)+F-W)/2 ,其中 O 是輸出圖像的大小,W 是輸入圖像的大小,F 是濾波器大小,P 是作為填充添加的像素層數,S 是步幅。例如,如果輸入圖像的大小是 5x5,濾波器大小是 3x3,步幅是 1,並且我們希望輸出圖像的大小與輸入圖像相同,則有效的填充應為 1。
Now that we have done the heavy lifting on the image, its time to think of the next step in the process.
現在我們已經完成了圖像的繁重工作,該考慮下一步的流程了。
We aspire to make our neural network to be flexible i.e. no matter what the data is, it should be efficient enough to identify from the data. Since the feature maps we have can be represented using some linear function, the uncertainty factor seems to be missing. We need functions to introduce uncertainty, or rather I should say non-linearity, into our neural network.
我們渴望使我們的神經網絡具有靈活性,即無論數據是什麼,它都應該足夠高效地從數據中識別出來。由於我們擁有的特徵圖可以用某些線性函數來表示,因此似乎缺少了不確定性因素。我們需要一些函數來引入不確定性,或者更確切地說,非線性,進入我們的神經網絡。
There are many functions capable of performing this task but, these two functions are widely used.
有許多功能能夠執行此任務,但這兩個功能被廣泛使用。
Sigmoid: It introduces non-linearity using the function g(z)=1/1+e⁻ᶻ which transforms the numbers to range between 0–1. One of the major problems with the Sigmoid function is the Vanishing Gradient Problem. Don’t worry if you are unfamiliar with the term. This post by Chi-Feng Wang explains the phenomenon of the Vanishing gradient.
Sigmoid:它使用函數 g(z)=1/1+e⁻ᶻ 引入非線性,將數字轉換為 0 到 1 之間的範圍。Sigmoid 函數的一個主要問題是梯度消失問題。如果你對這個術語不熟悉,別擔心。這篇由文章的 王啟峰 解釋了梯度消失現象。
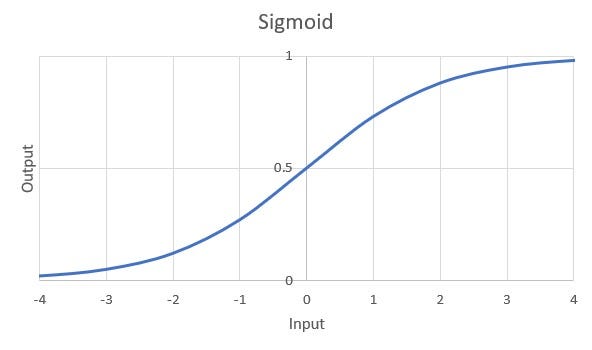
S 型函數的圖
ReLU: ReLU stands for the Rectified Linear Unit. It thresholds the input at 0 using the function g(w)=max(0,w). Performance of the ReLU is better than Sigmoid function also, it partly tackles with the vanishing gradient problem. Though one problem that ReLU suffers from is the dying ReLU problem which is resolved by its variant called Leaky ReLU.
ReLU: ReLU 代表修正線性單元。它使用函數 g(w)=max(0,w)。將輸入閾值設為 0。ReLU 的性能優於 Sigmoid 函數,並且部分解決了梯度消失問題。不過,ReLU 面臨的一個問題是死亡 ReLU問題,這個問題可以通過其變體Leaky ReLU來解決。
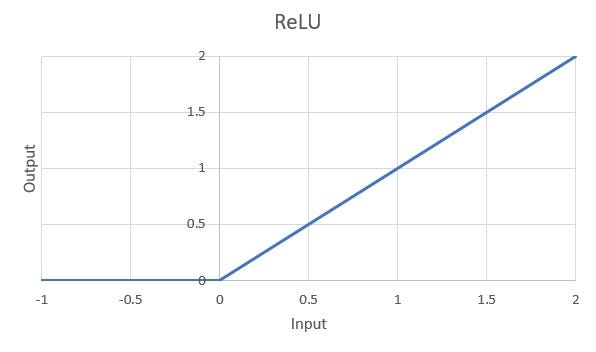
ReLU 函數的圖
Now that we have made our network strong enough to adapt to changes, we can focus on the other problem of computation time. If you remember, the dimension of our image was 5999 x 4000 x 3 which counts to 71,988,000 pixel values for a single image and we have many such. Though machines are exceptionally fast, it will take quite some time to process these humongous number of pixel values.
現在我們已經使我們的網絡足夠強大以適應變化,我們可以專注於另一個計算時間的問題。如果你還記得,我們的圖像尺寸是 5999 x 4000 x 3,這意味著單張圖像有 71,988,000 個像素值,而且我們有很多這樣的圖像。儘管機器運算速度極快,但處理這些龐大的像素值仍然需要相當多的時間。
One basic instinct would be to select a dominant value among the group. This is achieved by the machines using an operation called Pooling.
一個基本的本能是從群體中選擇一個主導值。這是通過機器使用一種稱為池化的操作來實現的。
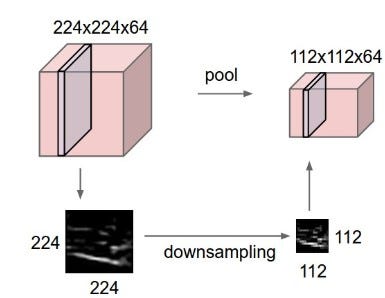
圖像的降採樣。照片來自Github(MIT)
We define a pooling window, let’s say 2 x 2. Similar to filters this window slides over the image and selects a dominant value from the window. Definition of the dominant changes with the approach.
我們定義了一個池化窗口,假設是 2 x 2。與濾波器類似,這個窗口在圖像上滑動並從窗口中選擇一個主導值。主導的定義會隨著方法的不同而改變。
One of the approaches is Max Pooling which is widely popular where the maximum value from the image within the window is selected. This reduces the size to 25%. Other pooling approaches include Average Pooling, L2 norm of the rectangular neighborhood which differs in the approach of selecting the dominant value.
其中一種方法是最大池化,這種方法非常流行,選擇視窗內圖像的最大值。這將尺寸減少到 25%。其他池化方法包括平均池化、矩形鄰域的 L2 範數,它們在選擇主導值的方法上有所不同。
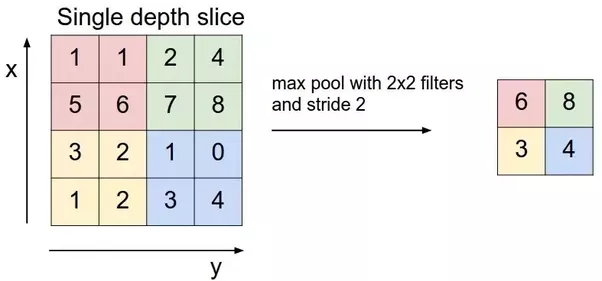
最大池化。照片來自 Github (MIT)
Hence, the main motive for having the Pooling layer is for dimensionality reduction. Although, there have been talks about removing the pooling layers and substituting it with the Convolution Layer instead. Striving for Simplicity: The All Convolutional Net proposes one such architecture where they suggest using larger stride once a while to reduce the dimensionality of the initial representation.
因此,池化層的主要動機是進行維度縮減。儘管如此,也有討論過移除池化層,並以卷積層來取代。追求簡單性:全卷積網絡提出了一種這樣的架構,他們建議偶爾使用較大的步幅來減少初始表示的維度。
The key difference between the ANN and CNN is the ability of CNN to process the spatial relationships in the image and apart from that, the computation power is the same for both. Since we have provided a platform to process the spatial relationships using Convolution, Activation, and Pooling, we can now leverage the power of ANN.
ANN 和 CNN 之間的主要區別在於 CNN 能夠處理圖像中的空間關係,除此之外,兩者的計算能力是相同的。由於我們提供了一個使用卷積、激活和池化來處理空間關係的平台,我們現在可以利用 ANN 的強大功能。
Fully Connected Layers are the representation of the regular neural network or Multi LayerPerceptron (MLP).
全連接層 是常規神經網絡或多層感知器 (MLP) 的表示。
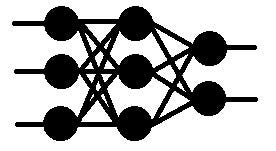
The main idea behind using these layers is to learn through the non-linear combinations of the high-level features extracted by the convolution and pooling layers. While training the network, the weights between the neurons act as a parameter that is tweaked while training. As this layer accepts the input in the 1D vector form, we need to flatten the output from the previous layers to feed to the FC layer.
使用這些層的主要想法是通過卷積層和池化層提取的高階特徵的非線性組合來學習。在訓練網絡時,神經元之間的權重作為參數,在訓練過程中進行調整。由於這一層接受的是一維向量形式的輸入,我們需要展平前一層的輸出以傳遞給全連接層。
The output of this layer, in case of classification of multiple classes, are real values for each class. To gain some insight from these values, the Softmax function is used. More about the Softmax function can be found here. It converts these real values into class probabilities. The class with the highest probability is then extracted as the predicted class.
該層的輸出,在多類別分類的情況下,為每個類別的實數值。為了從這些數值中獲得一些見解,使用了Softmax 函數。有關 Softmax 函數的更多資訊可以在這裡找到。它將這些實數值轉換為類別概率。然後提取概率最高的類別作為預測類別。
While these are not the only layers used in building the CNN, they are the basic building blocks of it. Depending on the nature of the problem, multiple other types of layers such as DropOut Layer and Normalization Layer can be added.
雖然這些並不是構建 CNN 唯一使用的層,但它們是其基本構建塊。根據問題的性質,可以添加多種其他類型的層,例如 DropOut 層和正規化層。
There are numerous architectures of CNN that have proven to perform exceptionally well on the classification of images. Few of them are:
有許多卷積神經網路(CNN)的架構已被證明在圖像分類方面表現非常出色。其中一些包括:
- AlexNet
- VGGNet VGG 網絡
- ResNet 殘差網絡
- Inception 全面啟動
- DenseNet 稠密網絡
While these architectures are ready to use, I urge you to play around with the architecture and build one of your own.
雖然這些架構已經可以使用,但我鼓勵你嘗試修改這些架構並建立你自己的架構。
Thanks for reading! Hope this article helps in getting a basic intuition about the Convolutional Neural Network. You can reach out to me on my Email, LinkedIn in case of any feedback or suggestions. I would love to hear them!
感謝閱讀!希望這篇文章能幫助您對卷積神經網絡有基本的直覺。您可以通過我的電子郵件,LinkedIn聯繫我,提供任何反饋或建議。我很樂意聽取您的意見!
Next article will be focused on an end to end example for CNN!
下一篇文章將專注於一個關於卷積神經網絡的端到端範例!
Happy Learning! 快樂學習!




{kind=link}
{kind=link}
{kind=link}