Mother's Day: How AI can help you show the ultimate appreciation
母亲节:人工智能如何帮助您表达最终的感激之情

Lisa Coulouris 丽莎·库洛里斯
Director of Public Relations公共关系总监

Solving the Million Songs Challenge
解决百万首歌挑战

Jaden Baptista 贾登·巴蒂斯塔

Drive personalization, performance and growth at scale with AI search on Salesforce
利用 Salesforce 上的 AI 搜索,在规模上推动个性化、性能和增长

Valeriia Pierzinski 瓦列里娅·皮尔津斯基
Product Marketing Manager, AlgoliaAlgolia 产品营销经理

CI/CDay 2024: What makes a good CI/CD platform?
CI/CDay 2024:什么构成了一个好的 CI/CD 平台?

Tim Carry 蒂姆·凯瑞
Developer Advocate 开发者倡导者
What does it mean for AI search to “understand” customers?
AI 搜索“理解”客户意味着什么?

Catherine Dee 凯瑟琳·迪
Search and Discovery writer搜索与发现作家

The future of B2B is powered by AI. Here’s how to get started.
B2B 的未来由人工智能驱动。以下是如何开始的方法。

Tariq Khan
Director of Content Marketing内容营销总监

The definitive guide to semantic search engines
语义搜索引擎的权威指南

Jon Silvers 乔恩·席尔弗斯
Director, Digital Marketing数字营销总监

How do I look? — Image recommendation AI in practice
我看起来怎么样?——实践中的图像推荐人工智能

Jaden Baptista 贾登·巴蒂斯塔
Technical Writer 技术作家
Paul-Louis Nech 保罗-路易·内克
Senior ML Engineer 高级机器学习工程师
Why is conscious friction in AI important?
为什么在人工智能中有意识的摩擦很重要?
Tariq Khan
Director of Content Marketing内容营销总监

Navigating the EU AI Act with Algolia AI Search
使用 Algolia AI 搜索导航欧盟 AI 法案

John Stewart 约翰·斯图尔特
VP, Corporate Communications and Brand副总裁,企业传播和品牌

AI is the answer to your fashion crisis
人工智能是解决您时尚危机的答案
John Stewart 约翰·斯图尔特
VP, Corporate Communications and Brand副总裁,企业传播和品牌
Why B2C business leaders rank AI personalization as a critical growth opportunity
为什么 B2C 业务领导者将 AI 个性化排名为关键增长机会
Tariq Khan
Director of Content Marketing内容营销总监

Driving Personalization at Scale: Key Highlights from Adobe Summit 2024
在规模上推动个性化:Adobe Summit 2024 的重点亮点

Michael Klein 迈克尔·克莱因
Principal, Klein4Retail 首席,Klein4Retail
How to automatically optimize your product listing pages
如何自动优化您的产品列表页面
Catherine Dee 凯瑟琳·迪
Search and Discovery writer搜索与发现作家

Reflections from the road: Takeaways from Shoptalk and Adobe Summit
路上的反思:Shoptalk 和 Adobe Summit 的收获

Marissa Wharton 玛丽莎·沃顿
Marketing Content Manager营销内容经理

Introducing Algolia for Flutter: Build Beautiful Search Experiences
介绍 Algolia for Flutter:构建美丽的搜索体验

Imogen Lovera 伊莫金·洛维拉
Senior Product Manager 高级产品经理
Backend search — how to embed AI search into your webapp
后端搜索 - 如何将 AI 搜索嵌入到您的 Web 应用程序中
Jaden Baptista 贾登·巴蒂斯塔
Technical Writer 技术作家
How and why events drive search ROI
事件如何以及为什么推动搜索投资回报率
Jaden Baptista 贾登·巴蒂斯塔
Technical Writer 技术作家
Ben Franz 本·弗兰茨
Sales Engineering and Product Leader at AlgoliaAlgolia 的销售工程和产品负责人
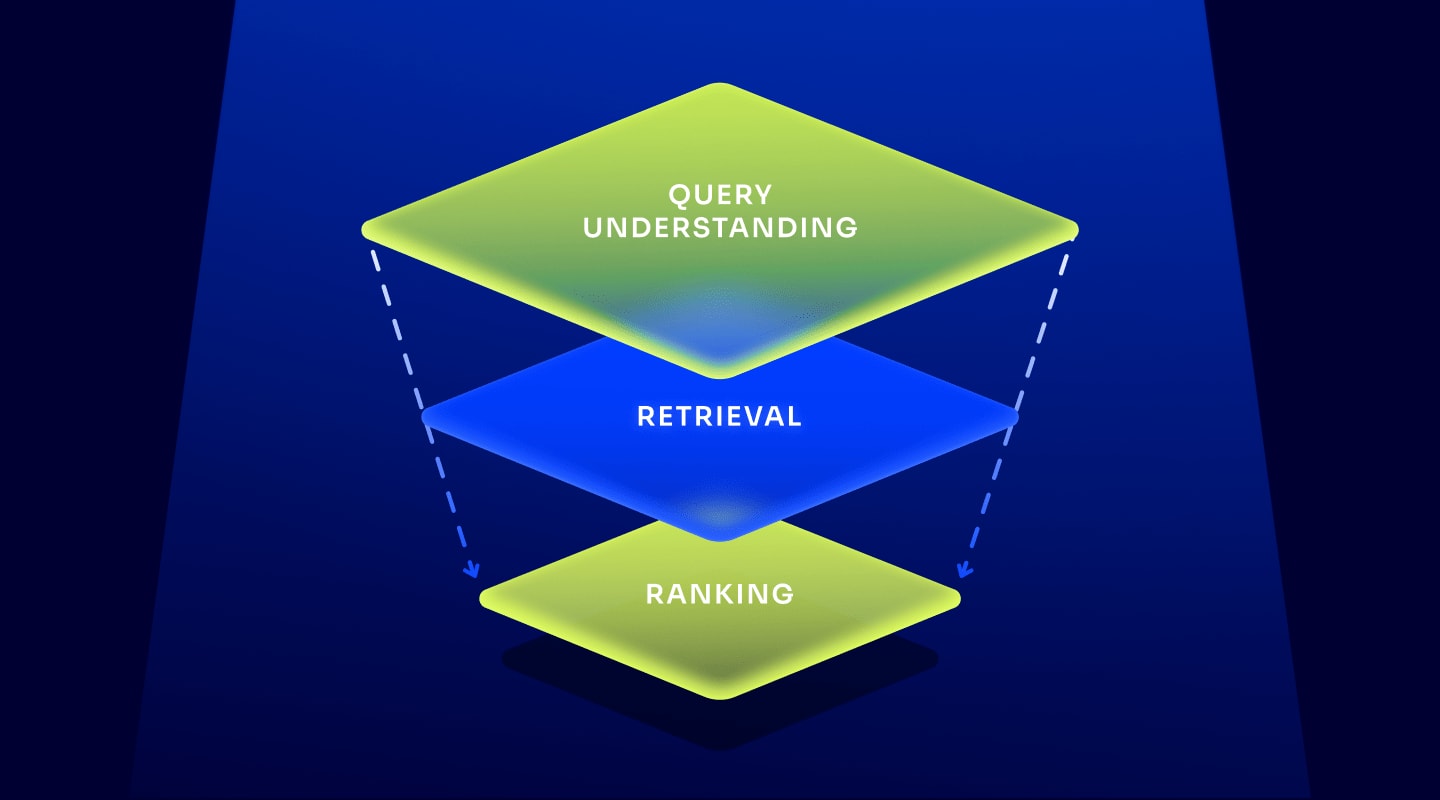
Query understanding 101 查询理解 101

What is query understanding?
什么是查询理解?
Query understanding is the process of analyzing search queries and translating them into an enhanced query that can produce better search results. It’s one of the most important keys to great search experiences.
查询理解是分析搜索查询并将其转换为可以产生更好搜索结果的增强查询的过程。这是提供出色搜索体验的关键之一。
What are some examples of query understanding?
有哪些查询理解的例子?
Query rewriting, synonyms, spelling corrections, classification, NLP, vectorization, bigram, and trigram detection for query segmentation, semantic query understanding, personalization, localization, and query scoping (attribute mapping).
查询重写、同义词、拼写纠正、分类、自然语言处理、向量化、二元组和三元组检测用于查询分割、语义查询理解、个性化、本地化和查询范围(属性映射)。
How important is query understanding to great search results?
查询理解对于出色的搜索结果有多重要?
Absolutely critical. People make a lot of spelling mistakes and language is also inherently ambiguous (“test”, “mobile”, “apps”, “summer”, “north” are all nouns; “Jaguar” is a car, an operating system, an animal, etc.). People also use slang and mention things that aren’t necessarily ever mentioned in result item text at all (e.g. “size 14 shoes”, “near a park”, “next Thursday evening”, etc.). All of this needs to be translated into something meaningful that can better query the underlying data structure.
绝对至关重要。人们经常拼写错误,语言本身也存在歧义(“测试”、“手机”、“应用程序”、“夏天”、“北方”都是名词;“Jaguar”既是汽车、操作系统、动物等)。人们还使用俚语并提及结果项文本中从未提到的事物(例如“14 号鞋”,“靠近公园”,“下周四晚上”等)。所有这些都需要被翻译成有意义的内容,以更好地查询底层数据结构。
In addition, query understanding can also be used to prioritize results. For example, historically, in the US or Australia, when people search a government website for “license,” they were most often looking for a driver’s license renewal page — not the hundreds of other pages mentioning “license”. Historical performance data can automatically elevate the value of the preferred destination, even if there is no indication otherwise in the query itself that it is most important.
Query understanding is often a great test of search technology. What if you need to map “size 14” to a size attribute, or “next Thursday” evening to a time filter, or automatically spell correct queries? Can your current implementation do this? If not, then you are frustrating your customers and falling behind.
Where should I begin with query understanding techniques?
Many highly useful query understanding techniques, such as synonyms, spell correction, and semantics, belong to the family of query rewriting, which aims to modify the query to represent the query intent better and thus improve overall precision, recall, or both. The order in which these techniques are applied can significantly impact the query outcomes as well as the processing complexity. Below are some of those techniques most commonly used.
Synonyms
Synonyms are fairly straightforward. They are typically run as an alternate reality, so if someone searched for “gigantic shoes,” this may expand to “(gigantic OR enormous) shoes”. This is pretty simple but can be more complex if working out which to prioritize. It can also be even more complex if synonyms are generated using machine learning, e.g., via word embeddings. Newer semantic search capabilities, such as vector search, have a built-in understanding of similar, common terms, so there’s no need to create additional synonym libraries. We’ll touch more on this below.
Spelling correction
Spell correction can work in different ways. One approach is to correct words by coming up with a single likeliest replacement and then allowing users to override it. Another approach is to be tolerant and allow up to two-letter spelling errors. This is called typo tolerance. However, the best alternative is not always to correct (language is ambiguous) and the penalty for being wrong is very high, as people may lose confidence and give up. Like synonyms, vector search solutions can help with many common misspellings.

Another approach to spell correction is to look at every possible variant and run all of them. This can explode very quickly and slow down queries. To retain query speed, a search engine would have to bake the prioritization of the ranking algorithm into the data structure itself at the expense of query flexibility. Depending on your application, this may or may not be a good tradeoff.
Our spell correction technique (as of this writing) is a combination of techniques. It looks at alternatives but can weigh them efficiently in terms of likelihood of the searcher’s intent using distance. This is very effective and is trained from not only query data, but also result items themselves — product names, titles, etc. It will understand your data immediately — in any language — and then continue to improve over time with more queries.
Query categorization
Query categorization helps the search engine to predict the most relevant category or selection of items. Search models will use previous searches and search data from your site to predict the likelihood that a query belongs to one category or another. In the case of Algolia’s Query Categorization, we use a vector-based semantic model to predict which classifications a search query is most likely to align with.
Semantic query understanding
Semantic query understanding is the process of actually trying to understand the intent of queries. Language is very ambiguous by nature and the notion of polysemy aptly describes why this is such an issue for search: “poly” means multiple and “semy” in this case means senses, or meanings. “Bank” is a classic example of this; does this mean a financial institution or the side of a river? Without added context, it is difficult to know. English, in particular, is littered with examples. Luckily there are methods to handle this.
For queries with multiple words, the context is typically more obvious. For single search terms, it is more difficult, but in these cases, the past query sequence history can be useful. For example, if someone searched for “atm” and then searched for “bank”, it would be unlikely the second query was to do with the side of a river!
Classification can also be used to understand the type of query intent. This is most useful for query boxes that search datasets with multiple distinct data types. An example is LinkedIn, where you can search for companies, people, jobs, etc. The historical patterns for each query can assist with predicting the most likely result type. Ecommerce is another example, where a support query is different from a product search. For example, searching for “return shoes” should include results for returns, not display shoes for purchasing.

Natural Language Processing (NLP)
NLP is the process of analyzing unstructured text to infer structure and meaning. Structure, in this case, is referring to information that is highly defined, for example, a category or a number, much like fields in a database. It can also represent relationships between things. Common examples include sizes, colors, places, names, times, entities, and intent, but there are many more. NLP is most valuable when the underlying data has a lot of structure that can be mapped from the queries.
NLP will also parse the query to make it simpler to understand. A common example is the use of stemming to revert terms to their roots — “running” and “ran” become “run”. By mapping words to their stems, we can identify synonyms to improve lookup. NLP will also have a list of stop words — words such as “the”, “is”, “and”, and other commonly used terms — to reduce noise from the query.

Query scoping

Query scoping can make ordinary text search appear highly intelligent. This technique attempts to find structure within the query that doesn’t necessarily match unstructured text (reverse indexes) but instead maps directly to structured data attributes.
An example may be the query “black size 14 basketball shoes”. Product information is highly unlikely to mention the text “size 14”, but the sizing is highly likely to appear in a list of sizes on relevant products. “Black” as color may be in the description, but may also map to a more specific color attribute. So this query may actually remove this text and query only for “basketball shoes”, but at the same time filter the result set to size=14 and color=black. This dramatically increases precision, and in the case of a strict AND based search can also increase recall.
The downside of the above technique is for understanding queries with potentially mixed meaning. For the example query “size 6 nike”, the sizing may refer to shoe size which could be men’s, women’s, kid’s, US, UK or other, a shirt size, sports bra size, or even a basketball size! Over-filtering (or over-boosting certain results) can cause a significant loss of precision.
Despite the potential issues, the upside far outweighs any downsides. The typical approach to implementing this technique is to remove specific text identified from the query and convert it into a structured operation (i.e., filter or boost). This allows people to use natural language to describe what they want and have it transitioned into something much more meaningful than the original unstructured query.
Lastly, if a structure is not present on your records, that doesn’t mean you can’t generate it yourself. Index time analysis and data extraction can be a powerful tool to add structure to your information. Clustering, classification, topic modeling, tagging, and entity extraction are just some of the powerful techniques available.
Word embeddings
Vectorization is the process of converting words into vectors (numbers) which allows their meaning to be encoded and processed mathematically. This underpins language translation and many other amazing applications. The magic in the vectors is they can also be added and subtracted, so the meaning of the text can also be added and subtracted. In practice, vectors are used for automating synonyms, clustering documents, detecting specific meanings, and intents in queries and ranking results.

Query segmentation
Query segmentation is the process of identifying sequences of tokens that mean much more together than they do individually. This assists in improving precision by not returning results for partial segments. Two and three-word phrases (bigram and trigrams in this context) are useful in that they can potentially have much more meaning than individual words (unigrams).
For example, take the phrase “new york”. On their own, these two words don’t mean much, but together they obviously do! So instead of treating them on their own, they can be combined into a single term which can even have its reverse index. We could look up the indexes of both terms and work out when they are in sequence to derive the phrase matches but a) this is more complex and b) we possibly don’t want people searching for “new” to get results with “new york”. Also, if people search for “new” it is possible to match results containing “new york”. This is also problematic for reinforcement learning and other techniques where we don’t want machine learning to penalize partial matches unfairly. Hopefully, this hasn’t lost you, but the key point is maximizing information context.
Languages like English and French use a space to separate words, but languages without separators such as Chinese, Japanese, and Korean need an additional segmentation algorithm. At Algolia, we also build dictionaries into our libraries. Starting from the left of the question, Algolia will attempt to break down the query using known dictionary terms. In the event of uncertainty, we prioritize the solution that maximizes the length of the words while minimizing the number of characters that do not belong to a known word.
Personalization
Personalization is the process of adding additional information to a query based on the individual that is searching to change the results to be more relevant to the individual. This can be as simple as a clothing size preference, gender, location, or any other individual characteristic that can influence their results.
个性化是根据正在搜索的个人添加额外信息的过程,以改变结果使其更相关于个人。这可以是简单的衣服尺码偏好、性别、位置或任何其他个人特征,这些特征可以影响他们的结果。
Typically, the first stage of personalization is sending the information through with the queries to be recorded with other analytics. The performance impact can then be analyzed offline to determine if this is valuable. It should be noted that this is useful in its own right from a business intelligence perspective, even if it is not used for personalization.
通常,个性化的第一阶段是将信息通过查询发送,以便与其他分析记录。然后可以离线分析性能影响,以确定其价值。值得注意的是,即使不用于个性化,从商业智能的角度来看,这也是有用的。

通常查询可以与个人信息相结合,以增强和影响查询,从而产生高度个性化的结果
Localization 本地化
Localization is the process of using the searcher’s location to enhance results. Meetup is a good example of this in action. Google also often prompts users to enable location services so it can deliver local results. It can also be extracted from the query text itself (see NLP above) as is typically done for real estate and job search engines.
本地化是利用搜索者的位置来增强结果的过程。Meetup 是这一过程的一个很好的例子。Google 也经常提示用户启用位置服务,以便提供本地结果。它也可以从查询文本本身中提取(参见上文的自然语言处理),通常用于房地产和职位搜索引擎。
Be warned it can cause issues. For example, geolocation in Australia is less than 80% accurate, so you will put a big number of people in the wrong random city, possibly even over 1000 miles away. These quirks are usually navigable, but design with caution and always account for the UX flow assuming the location is incorrect. Meetup.com is an example where the location is so critical to the search that it’s now deeply integrated into the search UX. It’s often worth thinking about the cost of a wrong guess. Query understanding is never going to be perfect, so often it’s better to make it easy for the user to self-select.

Meetup.com 将位置选择直接集成到搜索栏中。
Voice search 语音搜索
Voice-based queries are on the rise, and that’s only further increased the need for advanced query understanding techniques, mainly because web search originally trained us to shorten queries (more text = fewer results). But voice search has since increased the query length and included much more structure in the query. Ironically, voice translation may get words wrong, but the spelling is perfect, so this raises other challenges.
基于语音的查询正在兴起,这进一步增加了对高级查询理解技术的需求,主要是因为网络搜索最初训练我们缩短查询(更多文本=更少结果)。但是语音搜索自那时起增加了查询长度,并在查询中包含了更多结构。具有讽刺意味的是,语音翻译可能会出错,但拼写是完美的,因此这带来了其他挑战。
Query understanding tips
查询理解技巧
Query logs are your friend and should help you to set the priorities for query understanding. For example:
查询日志是您的朋友,应帮助您设置查询理解的优先级。例如:
- Zero-result searches with high volume point to opportunities. Why are they failing?
高搜索量的零结果搜索指向机会。它们为什么失败了? - If no one is using natural language and/or you don’t have nicely structured information, then query scoping may not be that useful.
如果没有人在使用自然语言和/或你没有结构良好的信息,那么查询范围可能并不那么有用。 - If business language is not translating well to customer speak, synonyms may be useful.
如果业务语言无法很好地翻译成客户语言,同义词可能会有用。 - Do your customers make spelling mistakes and how frequently? If they make lots of mistakes then corrections will undoubtedly help.
您的客户是否经常拼写错误?如果他们经常犯错,那么纠正肯定会有帮助。
Advanced techniques like vectorization and personalization should come last as they require much more effort. While personalized search seems like the holy grail more often than not, there is much more value to be extracted by getting the basics right. After all, personalizing bad results is not going to be useful.
高级技术,如向量化和个性化,应该放在最后,因为它们需要更多的努力。尽管个性化搜索往往看起来像圣杯,但通过正确掌握基础知识可以提取更多的价值。毕竟,个性化不良结果是没有用的。

Hamish Ogilvy 哈米什·奥吉尔维
VP, Artificial Intelligence副总裁,人工智能
Recommended Articles 推荐文章
Powered by Algolia AI Recommendations